[ad_1]
Exploring new frontiers in cybersecurity is crucial as digital threats evolve. Conventional approaches, corresponding to handbook supply code audits and reverse engineering, have been foundational in figuring out vulnerabilities. But, the surge within the capabilities of Giant Language Fashions (LLMs) presents a novel alternative to transcend these standard strategies, doubtlessly uncovering and mitigating beforehand undetectable safety vulnerabilities.
The problem in cybersecurity is the persistent risk of ‘unfuzzable’ vulnerabilities—flaws that evade detection by standard automated techniques. These vulnerabilities signify vital dangers, as they typically go unnoticed till exploited. The appearance of refined LLMs gives a promising resolution by doubtlessly replicating the analytical prowess of human specialists in figuring out these elusive threats.
Through the years, the analysis crew at Google Undertaking Zero has synthesized insights from their intensive expertise in human-powered vulnerability analysis to refine the applying of LLMs on this discipline. They recognized key rules that harness the strengths of LLMs whereas addressing their limitations. Essential to their findings is the significance of intensive reasoning processes, which have confirmed efficient throughout varied duties. An interactive atmosphere is crucial, permitting fashions to regulate and proper errors dynamically, enhancing their effectiveness. Moreover, equipping LLMs with specialised instruments, corresponding to debuggers and Python interpreters, is significant for mimicking human researchers’ operational atmosphere and conducting exact calculations and state inspections. The crew additionally emphasizes the necessity for a sampling technique that permits the exploration of a number of hypotheses by means of distinct trajectories, facilitating extra complete and efficient vulnerability analysis. These rules leverage LLMs’ capabilities for extra correct and dependable outcomes in safety duties.
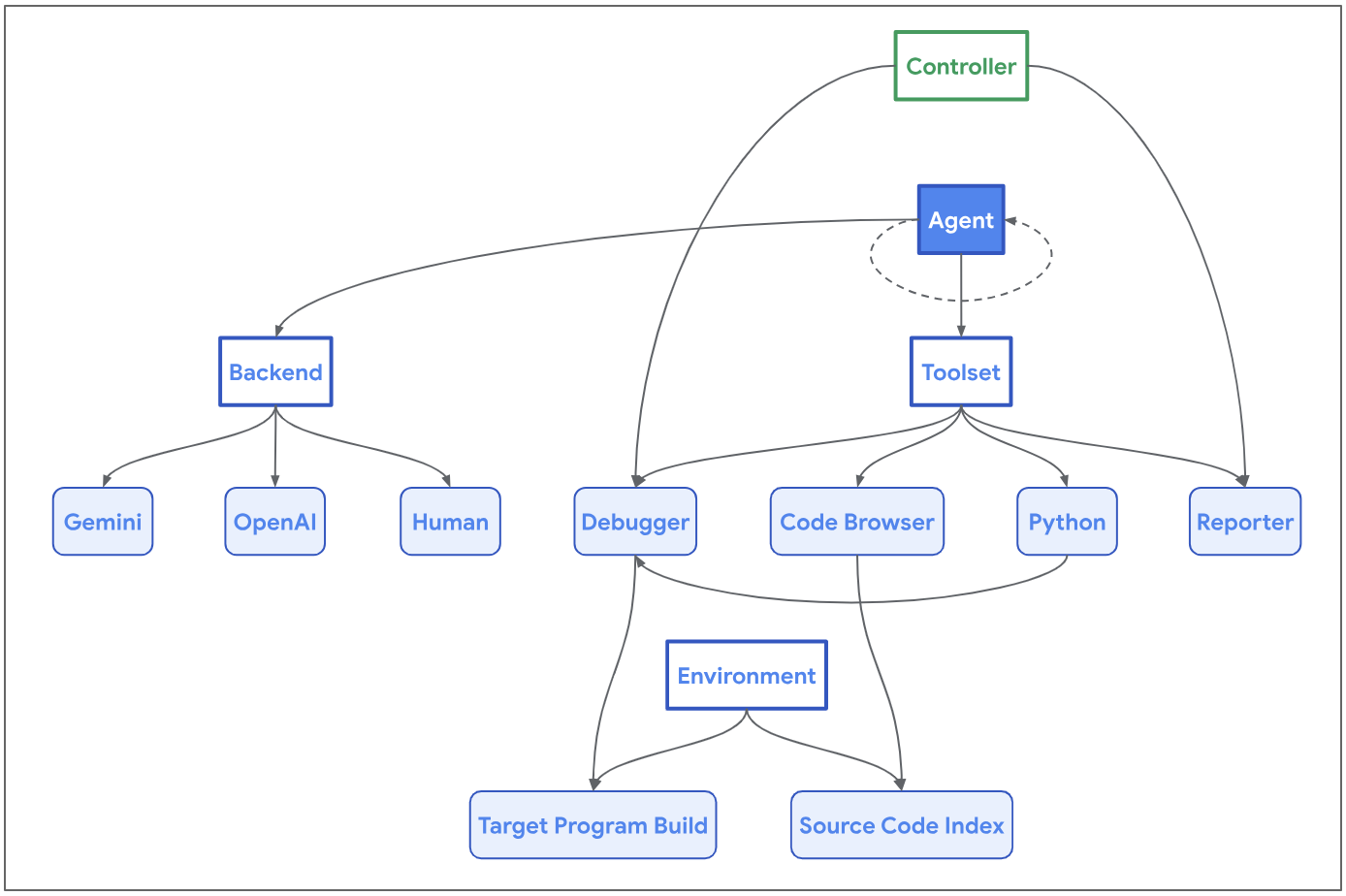
The analysis crew has developed “Naptime,” a pioneering structure for LLM-assisted vulnerability analysis. Naptime incorporates a specialised structure that equips LLMs with particular instruments to reinforce their skill to carry out safety analyses successfully. A key side of this structure is its concentrate on grounding by means of software utilization, guaranteeing that the LLMs’ interactions with the goal codebase carefully mimic the workflows of human safety researchers. This strategy permits for computerized verification of the agent’s outputs, a significant characteristic contemplating the autonomous nature of the system.
The Naptime structure facilities on the interplay between an AI agent and a goal codebase, outfitted with instruments just like the Code Browser, Python software, Debugger, and Reporter. The Code Browser permits the agent to navigate and analyze the codebase in-depth, much like how engineers use instruments like Chromium Code Search. The Python software and Debugger allow the agent to carry out intermediate calculations and dynamic analyses, enhancing the precision and depth of safety testing. These instruments work collectively inside a structured atmosphere to detect and confirm safety vulnerabilities autonomously, guaranteeing the integrity and reproducibility of the analysis findings.
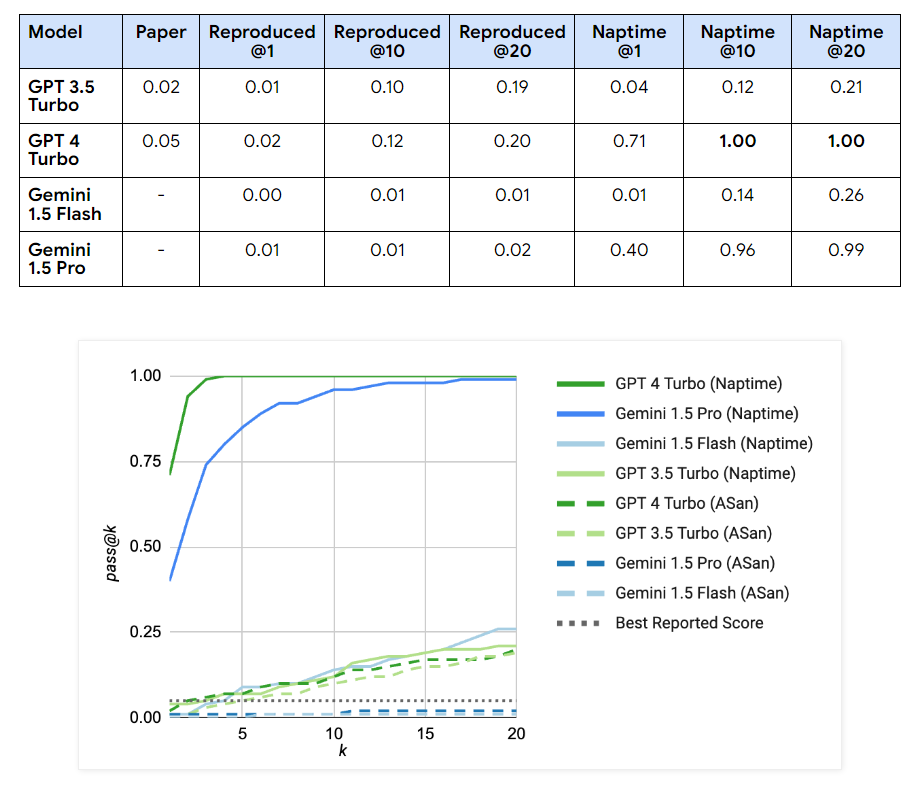
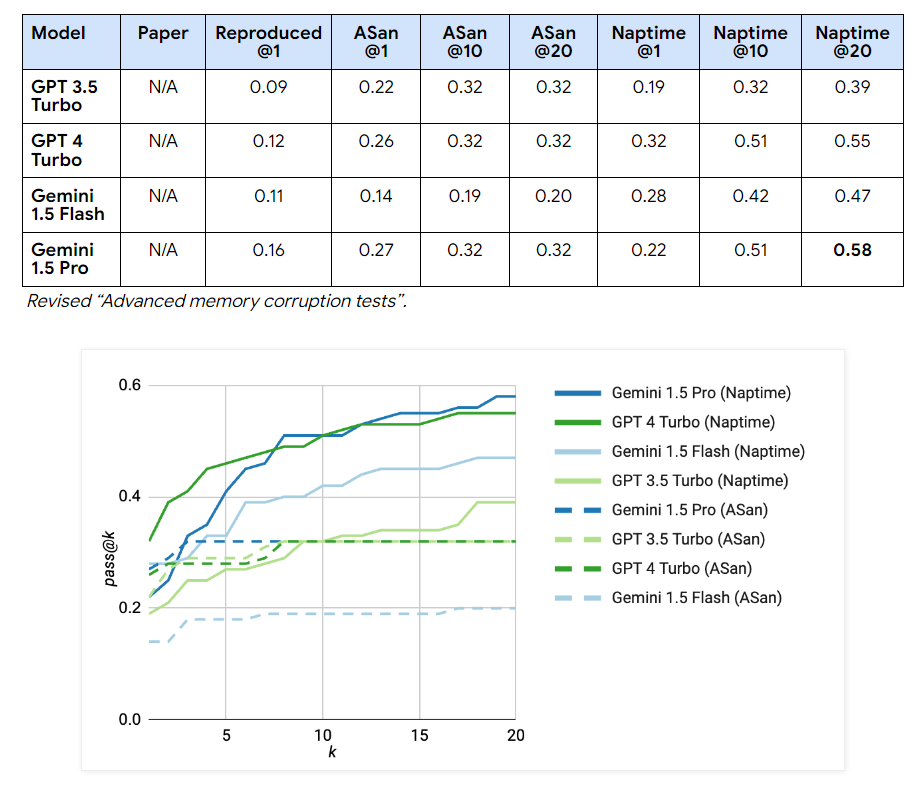
Researchers have built-in the Naptime structure with CyberSecEval 2 analysis, considerably enhancing LLM safety take a look at efficiency. For “Buffer Overflow” eventualities, GPT 4 Turbo’s scores surged to good passes utilizing the Naptime structure, reaching 1.00 throughout a number of trials, in comparison with its preliminary scores of 0.05. Equally, enhancements had been evident within the “Superior Reminiscence Corruption” class, with GPT 4 Turbo’s efficiency growing from 0.16 to 0.76 in additional complicated take a look at eventualities. The Gemini fashions additionally confirmed marked enhancements; for example, Gemini 1.5 Professional’s scores in Naptime configurations rose to 0.58, demonstrating vital developments in dealing with complicated duties in comparison with the preliminary testing phases. These outcomes underscore the efficacy of the Naptime framework in enhancing the precision and functionality of LLMs in conducting detailed and correct vulnerability assessments.
To conclude, the Naptime venture demonstrates that LLMs can considerably improve their efficiency in vulnerability analysis with the precise instruments, notably in managed testing environments corresponding to CTF-style challenges. Nevertheless, the true problem lies in translating this functionality to the complexities of autonomous offensive safety analysis, the place understanding system states and attacker management is essential. The research underscores the necessity to present LLMs with versatile, iterative processes akin to these employed by professional human researchers to replicate their potential actually. Because the crew at Google Undertaking Zero, in collaboration with Google DeepMind, continues to develop this expertise, they continue to be dedicated to pushing the boundaries of what LLMs can obtain in cybersecurity, promising extra refined developments sooner or later.
Nikhil is an intern advisor at Marktechpost. He’s pursuing an built-in twin diploma in Supplies on the Indian Institute of Know-how, Kharagpur. Nikhil is an AI/ML fanatic who’s at all times researching purposes in fields like biomaterials and biomedical science. With a robust background in Materials Science, he’s exploring new developments and creating alternatives to contribute.
[ad_2]