[ad_1]
Grokking is a newly developed phenomenon the place a mannequin begins to generalize nicely lengthy after it has overfitted to the coaching knowledge. It was first seen in a two-layer Transformer skilled on a easy dataset. In grokking, generalization happens solely after many extra coaching iterations than overfitting. This requires excessive computational assets, making it much less sensible for many machine studying practitioners with restricted assets. To completely perceive this uncommon habits, there’s a want for quicker generalization in these overfitting techniques. The principle goal is to hurry up the grokking phenomenon.
An present methodology, grokking is a newly found phenomenon that exhibits that overparameterized neural networks can generalize and motive past simply memorizing the dataset. Most analysis focuses on understanding this mechanism, linking grokking to the double descent phenomenon, the place validation error first will increase after which decreases as mannequin parameters develop. Aside from this methodology, optimization methods are used through which a mannequin’s generalization patterns differ considerably with totally different optimization strategies like mini-batch coaching, selection of optimizer, weight decay, noise injection, dropout, and studying price all have an effect on the mannequin’s grokking sample.
Researchers from the Seoul Nationwide College, Korea launched GROKFAST, an algorithm that accelerated grokking by amplifying sluggish gradients. Researchers proved by experiments that GROKFAST algorithms have the potential to unravel all kinds of duties that comprise photographs, languages, and graphs. This makes the distinctive artifact of fast generalization virtually helpful. Additional, the parameter trajectories underneath gradient descent are break up into two elements: the fast-varying, overfitting-yielding element and the slow-varying, generalization-inducing element. This evaluation helps the grokking methodology to turn out to be 50 occasions quicker with just a few strains of code.
Through the experiment, the concept of the algorithmic dataset used within the first report on grokking is proven, the place the community is a two-layer decoder-only transformer skilled to foretell the reply of a modular binary multiplication operation. Evaluating the time to achieve an accuracy of 0.95, the validation accuracy retains bettering longer. It reaches its peak 97.3 occasions later than the coaching accuracy, which shortly reaches its most and begins overfitting. Additional, hyperparameters are chosen from a easy grid search, and located that the filter works greatest when λ(scalar issue) = 5 and w(window measurement) = 100. Additionally, there’s a discount of 13.57 occasions within the variety of iterations to achieve the validation accuracy of 0.95, which is an effective outcome.
The proposed methodology relies on the concept sluggish gradients (low-pass filtered gradient updates) assist in generalization. The coaching dynamics of a mannequin are interpreted underneath grokking as a state transition, the place the mannequin goes by three levels:
- Initialized, the place each the coaching and validation losses aren’t saturated
- Overfitted, the place the coaching loss is totally saturated however validation loss just isn’t saturated
- Generalized, the place each losses are saturated.
Furthermore, analysis means that the load decay hyperparameter considerably performs a essential position within the grokking phenomenon.
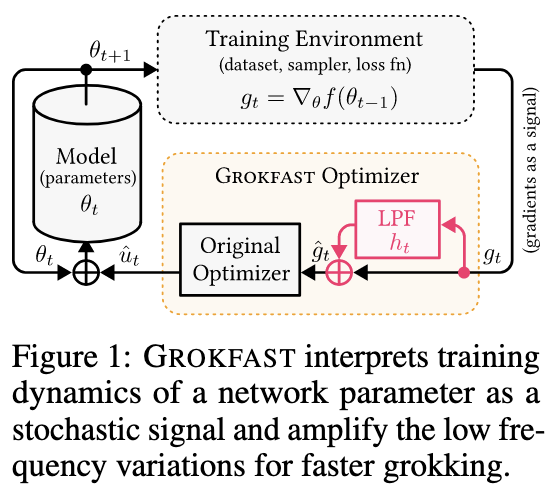
In conclusion, researchers from the Seoul Nationwide College, Korea have proposed an algorithm, GROKFAST, that accelerated grokking phenomenon by amplifying sluggish gradients. The evaluation of how every mannequin parameter modifications right into a random sign throughout coaching iteration helps to separate gradient updates into fast-varying and slow-varying elements. Regardless of exhibiting excellent outcomes, there’s a restrict within the utilization by GROKFAST that wants w occasions extra reminiscence to retailer all of the earlier gradients. Additionally replication of the mannequin parameters additionally makes the coaching slower.
Try the Paper and GitHub. All credit score for this analysis goes to the researchers of this undertaking. Additionally, don’t overlook to observe us on Twitter. Be a part of our Telegram Channel, Discord Channel, and LinkedIn Group.
In the event you like our work, you’ll love our publication..
Don’t Overlook to hitch our 43k+ ML SubReddit | Additionally, take a look at our AI Occasions Platform

Sajjad Ansari is a closing yr undergraduate from IIT Kharagpur. As a Tech fanatic, he delves into the sensible functions of AI with a concentrate on understanding the impression of AI applied sciences and their real-world implications. He goals to articulate complicated AI ideas in a transparent and accessible method.
[ad_2]