[ad_1]
The Combination of Specialists (MoE) fashions improve efficiency and computational effectivity by selectively activating subsets of mannequin parameters. Whereas conventional MoE fashions make the most of homogeneous specialists with an identical capacities, this method limits specialization and parameter utilization, particularly when dealing with various enter complexities. Latest research spotlight that homogeneous specialists are likely to converge to comparable representations, lowering their effectiveness. To deal with this, introducing heterogeneous specialists may supply higher specialization. Nevertheless, challenges come up in figuring out the optimum heterogeneity and designing efficient load distributions for these various specialists to steadiness effectivity and efficiency.
Researchers from Tencent Hunyuan, the Tokyo Institute of Know-how, and the College of Macau have launched a Heterogeneous Combination of Specialists (HMoE) mannequin, the place specialists range in measurement, enabling higher dealing with of various token complexities. To deal with the activation imbalance, they suggest a brand new coaching goal that prioritizes the activation of smaller specialists, bettering computational effectivity and parameter utilization. Their experiments present that HMoE achieves decrease loss with fewer activated parameters and outperforms conventional homogeneous MoE fashions on varied benchmarks. Moreover, they discover methods for optimum professional heterogeneity.
The MoE mannequin divides studying duties amongst specialised specialists, every specializing in completely different facets of the information. Later developments launched methods to selectively activate a subset of those specialists, bettering effectivity and efficiency. Latest developments have built-in MoE fashions into fashionable architectures, optimizing specialists’ selections and balancing their workloads. The examine expands on these ideas by introducing an HMoE mannequin, which makes use of specialists of various sizes to raised deal with various token complexities. This method results in simpler useful resource use and better total efficiency.
Classical MoE fashions change the Feed-Ahead Community (FFN) layer in transformers with an MoE layer consisting of a number of specialists and a routing mechanism that prompts a subset of those specialists for every token. Nevertheless, standard homogeneous MoE fashions want extra professional specialization, environment friendly parameter allocation, and cargo imbalance. The HMoE mannequin is proposed to handle these, the place specialists range in measurement. This permits higher task-specific specialization and environment friendly use of sources. The examine additionally introduces new loss capabilities to optimize the activation of smaller specialists and keep total mannequin steadiness.
The examine evaluates the HMoE mannequin towards Dense and Homogeneous MoE fashions, demonstrating its superior efficiency, notably when utilizing the High-P routing technique. HMoE constantly outperforms different fashions throughout varied benchmarks, with advantages changing into extra pronounced as coaching progresses and computational sources enhance. The analysis highlights the effectiveness of the P-Penalty loss in optimizing smaller specialists and the benefits of a hybrid professional measurement distribution. Detailed analyses reveal that HMoE successfully allocates tokens primarily based on complexity, with smaller specialists dealing with normal duties and bigger specialists specializing in additional advanced ones.
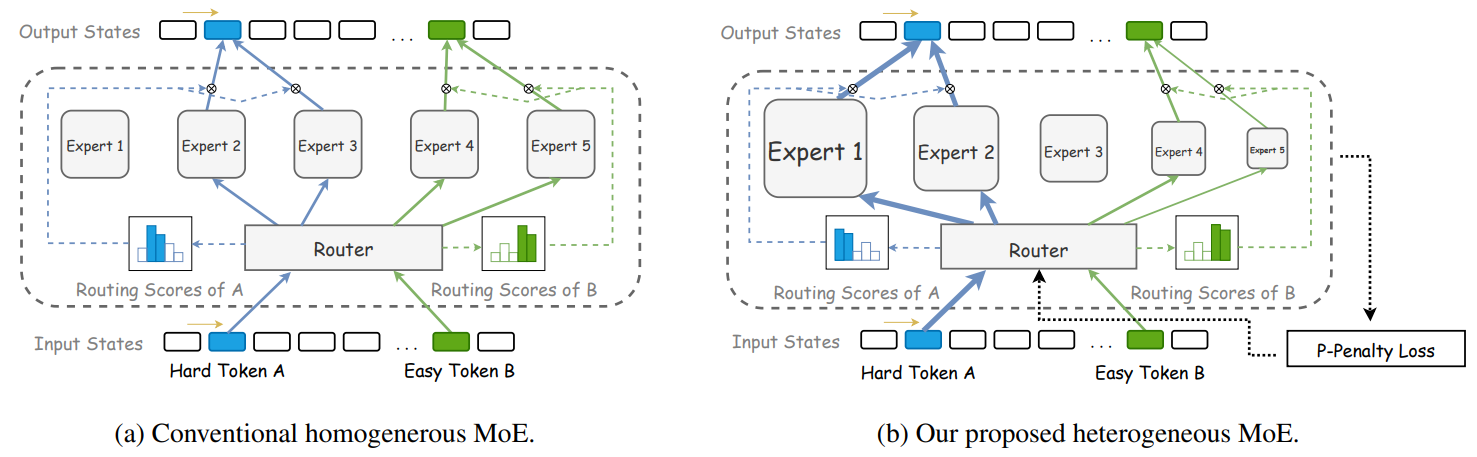
The HMoE mannequin was designed with specialists of various sizes to raised tackle various token complexities. A brand new coaching goal was developed to encourage smaller specialists’ activation, bettering computational effectivity and efficiency. Experiments confirmed that HMoE outperforms conventional homogeneous MoE fashions, attaining decrease loss with fewer activated parameters. The analysis means that HMoE’s method opens up new potentialities for giant language mannequin improvement, with potential future functions in various pure language processing duties. The code for this mannequin will probably be made out there upon acceptance.
Try the Paper. All credit score for this analysis goes to the researchers of this mission. Additionally, don’t neglect to observe us on Twitter and be a part of our Telegram Channel and LinkedIn Group. For those who like our work, you’ll love our publication..
Don’t Overlook to hitch our 49k+ ML SubReddit
Discover Upcoming AI Webinars right here
Sana Hassan, a consulting intern at Marktechpost and dual-degree scholar at IIT Madras, is enthusiastic about making use of know-how and AI to handle real-world challenges. With a eager curiosity in fixing sensible issues, he brings a recent perspective to the intersection of AI and real-life options.
[ad_2]