[ad_1]
Efficiently constructing GenAI purposes means going past simply leveraging the newest cutting-edge fashions. It requires the event of compound AI methods that combine information, fashions, and infrastructure in a versatile, scalable, and production-ready method. This entails entry to each open supply and proprietary fashions, vector databases, the power to fine-tune fashions and question structured information, create endpoints, put together information, handle prices, and monitor options.
On this weblog, we’ll stroll by way of the GenAI transformation for a number one enterprise capital agency (known as “VC” all through the weblog) that can be an investor in Databricks. Along with driving innovation internally, this VC needed to raised perceive alternatives to construct GenAI purposes to information their future investments. The VC developed a number of GenAI use instances, together with a Q&A interface to question info from their structured fund information, akin to “How a lot did we spend money on Databricks, and what’s its present worth?” In addition they constructed an IT assistant to reply to person questions, considerably lowering response turn-around time by the IT division. Extra use instances have been and are being quickly developed. On this weblog, we’ll stroll by way of the specifics of those two preliminary purposes with a concentrate on the framework at the moment being prolonged to new purposes in collaboration with Databricks Skilled Providers.
Use Case #1: Fund Knowledge Q&A
The VC has many common companions (GP) who make investments strategically in know-how startups throughout a number of funds. VC already has highly effective, self-service dashboards that resolve many GP requests, however particular analyses should undergo a guide course of by strategists and analysts who want to write down and execute SQL queries with a purpose to get them the data they want. VC requested for our assist in utilizing GenAI to automate this course of in collaboration with their analysts. The purpose was to arrange a Slackbot that might automate a lot of the frequent forms of questions being requested by GPs, lowering the response time and liberating up analysts to work on extra complicated duties.
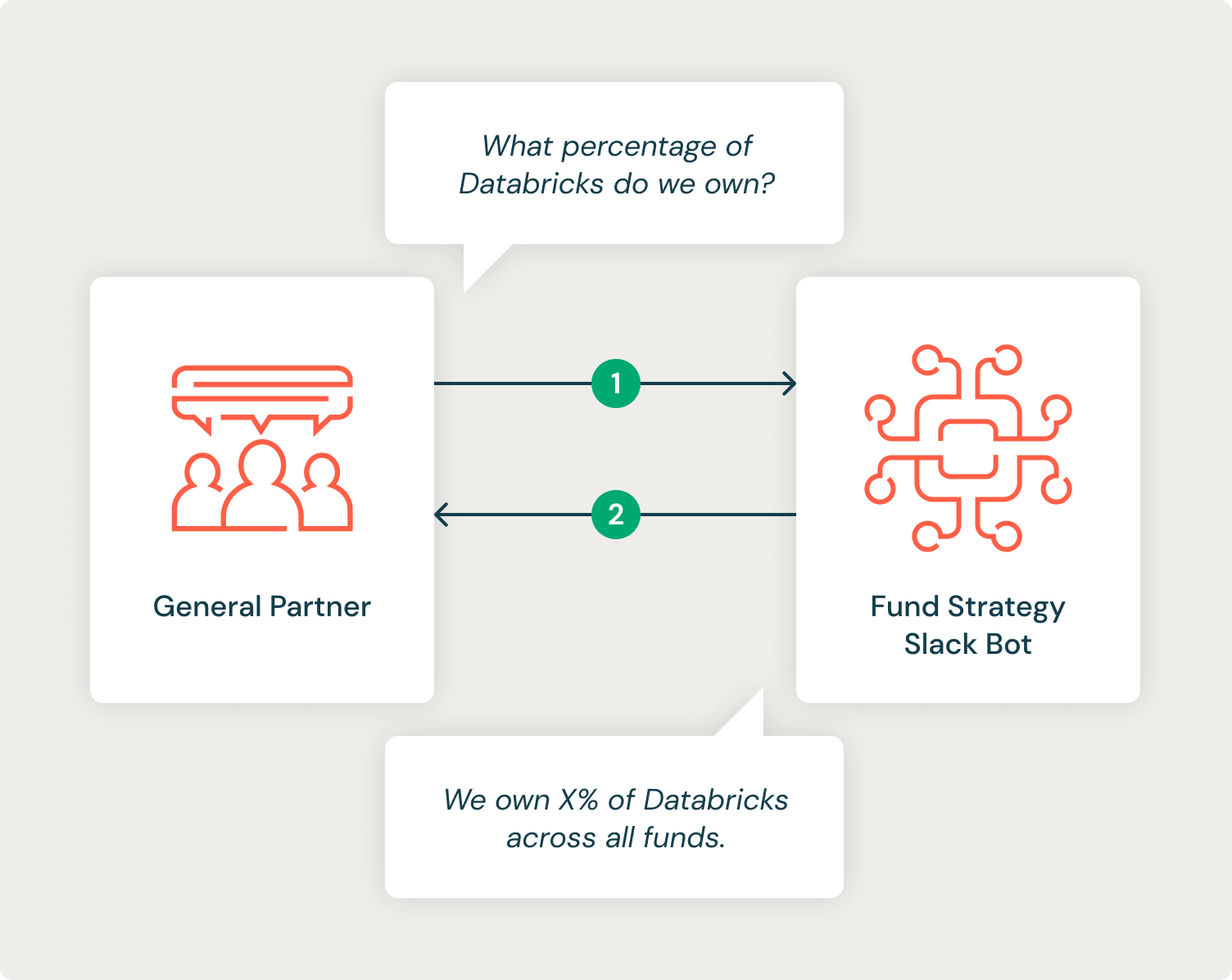
System Design
To construct this method, we wanted to leverage the ability of LLMs to generate SQL code, execute and debug the generated SQL, and interpret the returned structured information to reply the query in pure language.
We additionally thought-about among the implicit information of the analysts after they full these requests, akin to:
- Requests ought to assume an understanding of the info desk schema, together with caveats for a way columns must be used.
- Requests must be primarily based on probably the most present information except in any other case specified.
- Requests containing a primary title must be assumed to be a Common Companion’s title (e.g. “What has Rafael invested on this yr?”).
- Firm names could not precisely match these within the database (“databricks” vs “Databricks, Inc.”).
Our system ought to ask clarifying questions if the person’s intent isn’t clear from their query. For instance, if a person asks about “Adam’s investments” and there are two common companions named Adam, it ought to make clear which Adam the person desires to learn about.
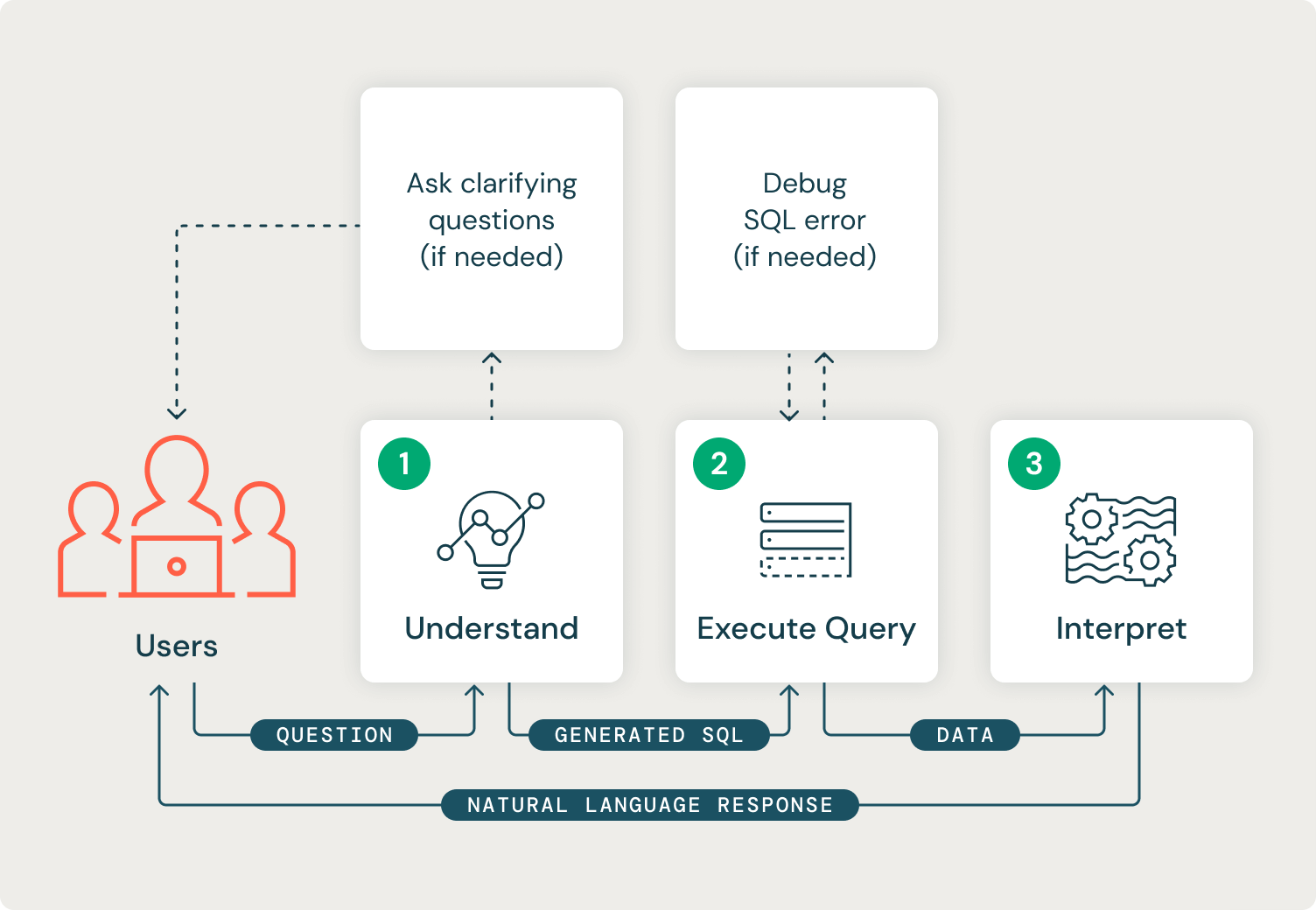
Our system also needs to frequently progress by way of three distinct phases. The primary stage is to grasp the person’s request intent. On this stage, our system ought to perceive the obtainable information tables and decide whether or not it has sufficient info from the person to generate a legitimate SQL question to perform the specified process. If it doesn’t have sufficient info, it ought to ask the person a clarifying query and restart the method. The output of the primary stage shall be a legitimate SQL string.
The second stage is the execution of the generated SQL and automatic debugging of any returned errors or information points. The output of this stage shall be an information body containing the info required to reply the person’s query.
The third and last stage interprets the info outcomes to generate a pure language response to the person. This stage’s output shall be a string response.
It’s attainable to construct this method with an agent method (often known as ReAct) or a Finite State Machine (FSM). Agent approaches excel in complicated and dynamic environments, when duties could must be utilized in completely different mixtures or orders and when the selection of process choice is ambiguous. Brokers are likely to carry alongside complexity in debugging, reminiscence administration, controllability, and interpretability. FSM-based methods are finest utilized to easier, well-defined processes with deterministic outcomes. FSM’s simplified and deterministic movement permits for simpler debugging and interpretability. FSMs are typically much less versatile than agent-based methods and could be tough to scale if many attainable states are desired.
We selected an FSM method as a result of:
- The movement of our system is constant for every person question, and our phases have very well-defined inputs and outputs.
- Interpretability and debugging functionality are of the utmost significance for this challenge, and a state-based method permits this by design.
- Now we have extra direct management over the actions of the system relying on its present state.
So as to construct our system we wanted a hosted endpoint capable of run the mannequin and reply to requests from the Slackbot. Databricks Mannequin Serving permits simple, scalable, production-ready mannequin endpoints that may host any native MLflow mannequin. Utilizing Databricks Exterior Fashions and Mannequin Serving allowed us to rapidly benchmark quite a lot of fashions and choose the best-performing mannequin. Databricks contains a built-in integration of MLflow that makes it easy to make use of one interface for managing experimentation, analysis, and deployment. Particularly, MLflow permits monitoring of a generic Python operate mannequin (pyfunc). Generic Python operate fashions can be utilized to rapidly wrap and log any Python class as a mannequin. We used this sample to iterate rapidly on a core unit-testable class, which we then wrapped in a pyfunc to log to MLflow.
Every distinct state of our FSM had well-defined inputs, outputs, and execution patterns:
- Perceive: requires a Chat taste LLM which is able to operate calling. A operate calling LLM is equipped with a structured information object that defines obtainable capabilities alongside the person’s question. The LLM determines whether or not it ought to name the obtainable operate or reply with a pure language response. For our system, we offered a `sql_query` operate to the LLM, which took a SQL string as enter. We then equipped the LLM with our delta desk schemas and instructed it to ask a clarifying query to the person if it was unable to name the obtainable operate.
- Execute Question: our system ought to attempt to execute the SQL question generated from step one and debug any SQL errors which may be returned. From the Mannequin Serving endpoint, our system can authenticate again to our Databricks delta tables through the use of the Databricks SDK for Python. The output of this step is an information body returned from our SQL question which is able to be interpreted.
- Interpret: consists of an LLM name that passes the unique person’s query, the generated SQL question, and the info body of retrieved information to the mannequin and is requested to reply the person’s query.
VC wrapped the API name to the Mannequin Serving endpoint in a Slackbot and deployed it to their inner Slack workspace. We took benefit of Slack’s built-in threads to retailer a conversational state which allowed GPs to ask follow-up questions.
Analysis
One explicit problem on this challenge was analysis. Since this method shall be offering monetary info to GPs who’re making choices, the accuracy of the responses is paramount. We wanted to judge the SQL queries that have been generated, the returned information, and the ultimate response. In an unstructured RAG, metrics like ROUGE are sometimes used to match a last outcome towards a reference reply from an analysis set. For our system, it’s attainable to have a excessive ROUGE rating because of related language however a totally unsuitable numeric outcome within the response!
Evaluating SQL queries may also be difficult. It’s attainable to write down many alternative SQL queries to perform the identical factor. It’s additionally attainable for column names to be aliased, or further columns retrieved which our analysis information didn’t anticipate. For instance, a query like “What are Rafael’s investments this yr?” may set off the technology of a SQL question that solely returns the corporate names of investments or may also embrace the quantity invested.
We solved the above issues by evaluating 3 metrics on our analysis set:
- Did it question the precise stuff? ⇒ Recall on tables and columns queried
- Did the question retrieve the precise information? ⇒ Recall for essential strings and numeric values in information response
- Did the ultimate generated reply have the precise language? ⇒ ROUGE for last generated response
Outcomes
Suggestions from inner VC stakeholders was very optimistic and excessive metrics have been noticed throughout the mannequin creation. Some instance conversations (scrubbed of figuring out data) are beneath:

Use Case #2: IT Helpdesk Assistant
Like many corporations, VC staff can ship emails to an IT electronic mail alias to get help from their IT helpdesk, which in flip creates a ticket of their IT ticketing system. The IT department shops its inner documentation in Confluence, and the purpose of this use case was to seek out the suitable Confluence documentation and reply to the IT ticket with hyperlinks to the related documentation together with directions for resolving the person’s request.
System Design
Utilizing APIs offered by the IT ticketing system, our GenAI use case runs a job that periodically checks for brand spanking new tickets and processes them in batches. Generated summaries, hyperlinks, and last responses are posted again to the IT ticketing system. This enables the IT division to proceed utilizing its software of alternative whereas leveraging the data gained from this GenAI resolution.
The IT documentation from Confluence is extracted by API and put in a vector retailer for retrieval (Databricks Vector Search, FAISS, Chroma, and so on.). As is usually the case with RAG on a information repository of inner paperwork, we iterated on the confluence pages to scrub the content material. We rapidly discovered that passing within the uncooked electronic mail threads resulted in poor retrieval of Confluence context because of noisy parts like electronic mail signatures. We added an LLM step earlier than retrieval to summarize the e-mail chain right into a single-sentence query. This served two functions: it improved retrieval dramatically, and it allowed the IT division to learn a single-sentence abstract of the request relatively than having to scroll by way of an electronic mail trade.

After retrieving the correct Confluence documentation, our GenAI helpdesk assistant generates a possible response to the person’s summarized query and posts the entire info (summarized query, confluence hyperlinks, and reply) again to the IT ticket as a non-public observe that solely the IT division can see. The IT division can then use this info to reply to the person’s ticket.
Much like the earlier use case, this RAG implementation was written as a wrapped PyFunc for straightforward deployment to a streaming job that might course of new information as they arrived.
Databricks workflows and Spark structured streaming have been utilized to load the mannequin out of MLflow, apply it to the IT tickets, and publish again the outcomes. Databricks Exterior Fashions was used to simply change between LLM fashions and discover the mannequin with the most effective efficiency. This design sample permits for fashions to be simply switched out for cheaper, quicker, and higher choices as they change into obtainable. Workflows have been routinely deployed utilizing Databricks Asset Bundles, Databricks’ resolution for productionizing workflows into CI/CD methods.
Outcomes
The IT helpdesk assistant has been an immediate success, including key items of data to every IT ticket to speed up the IT helpdesk’s decision. Beneath is an instance of an IT ticket and response from the IT helpdesk assistant.
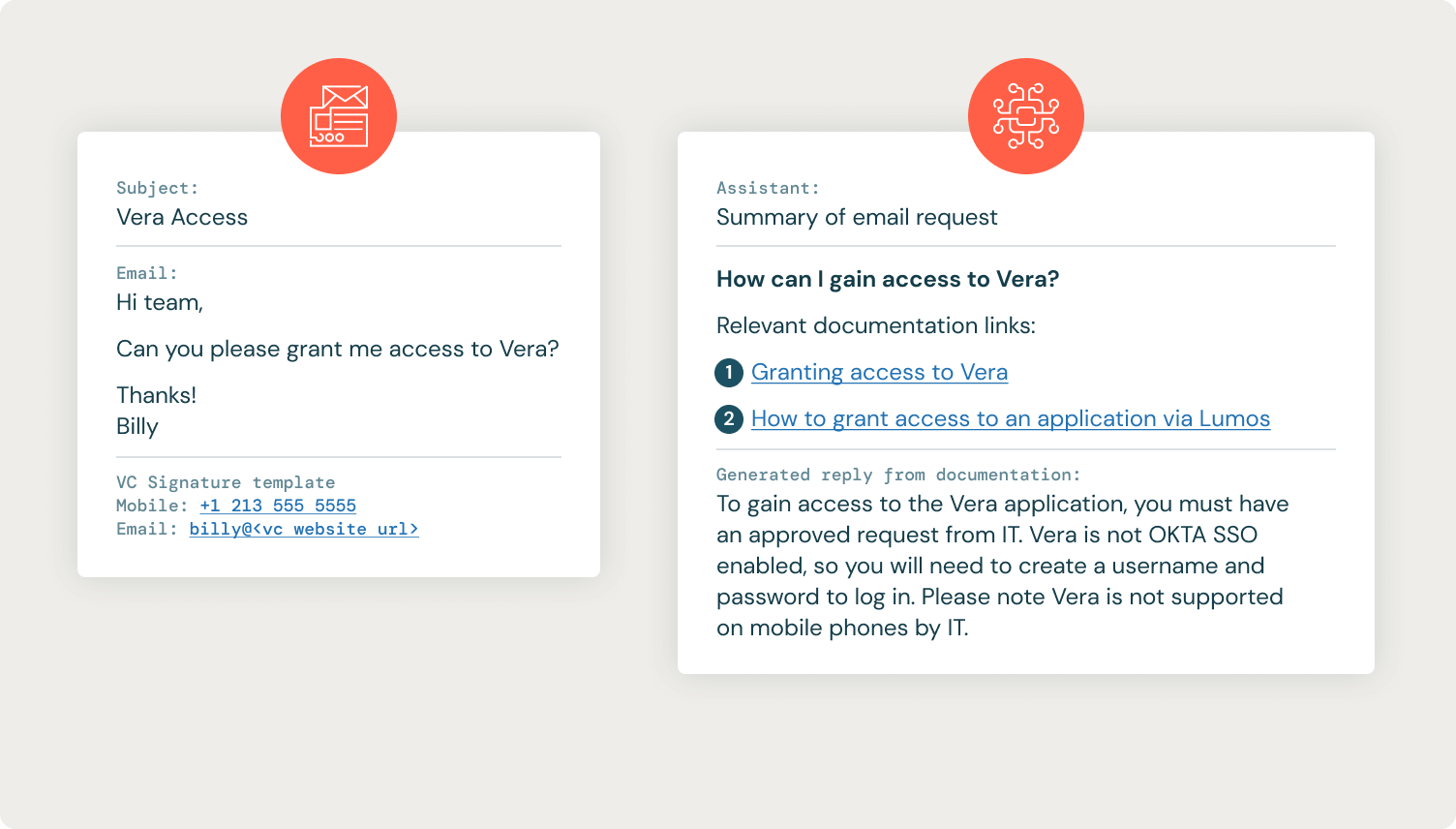
Many requests nonetheless require the IT division to course of them manually, however by offering a fast abstract of the required steps and immediately linking the IT helpdesk to the related Confluence documentation pages, we have been capable of pace up the decision course of.
Conclusion and Subsequent Steps
These options enabled the VC to launch their first manufacturing GenAI purposes and prototype options to new use instances. Databricks is enabling the following technology of compound AI methods throughout the GenAI maturity course of. By standardizing throughout a set of instruments for information processing, vector retrieval, deploying endpoints, fine-tuning fashions, and outcomes monitoring, corporations can create a manufacturing GenAI framework that permits them to extra simply create purposes, management prices, and adapt to new improvements on this rapidly-changing atmosphere.
VC is additional creating these initiatives because it evaluates fine-tuning; for instance, they’re adapting the tone of the GenAI IT assistant’s responses to raised resemble their IT division. By means of Databricks’ acquisition of MosaicML, Databricks is ready to simplify the fine-tuning course of, permitting companies to simply customise GenAI fashions with their information by way of instruction fine-tuning or continued pretraining. Upcoming options will enable customers to rapidly deploy a RAG system to a chat-like interface that may collect person suggestions throughout their group. Databricks acknowledges that organizations throughout all industries are quickly adopting GenAI, and companies that discover methods to rapidly work by way of technical limitations could have a robust aggressive benefit.
Study extra:
[ad_2]