[ad_1]
Giant language fashions (LLMs) are utilized in varied purposes, comparable to machine translation, summarization, and content material creation. Nonetheless, a big problem with LLMs is their tendency to provide hallucinations—statements that sound believable however will not be grounded in factual info. This concern impacts the reliability of AI-generated content material, particularly in domains requiring excessive accuracy, comparable to medical and authorized paperwork. Subsequently, mitigating hallucinations in LLMs is crucial to boost their trustworthiness and broaden their applicability.
Hallucinations in LLMs undermine their reliability and may result in misinformation, making it essential to handle this drawback. The complexity arises as a result of LLMs generate textual content based mostly on patterns realized from huge datasets, which can embrace inaccuracies. These hallucinations can manifest as incorrect details or misrepresentations, impacting the mannequin’s utility in delicate purposes. Thus, growing efficient strategies to scale back hallucinations with out compromising the mannequin’s efficiency is a big aim in pure language processing.
Researchers have explored varied strategies to sort out this concern, together with mannequin modifying and context-grounding. Mannequin modifying entails modifying the mannequin parameters to refine responses, whereas context-grounding contains related factual info inside the immediate to information the mannequin’s output. These approaches purpose to align the generated textual content with factual content material, thereby decreasing hallucinations. Nonetheless, every methodology has limitations, comparable to elevated computational complexity and the necessity for in depth retraining, which could be resource-intensive.
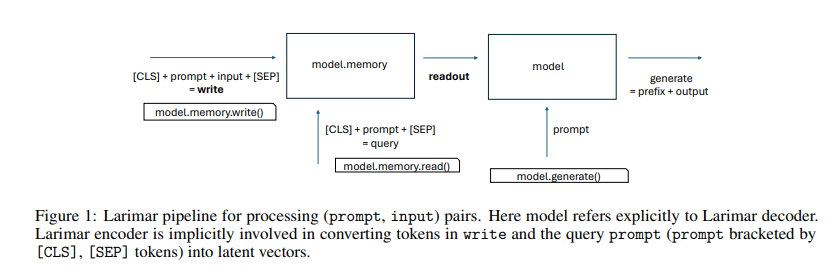
A Workforce of researchers from IBM Analysis and T. J. Watson Analysis Heart has launched a novel methodology leveraging the memory-augmented LLM named Larimar. This mannequin integrates an exterior episodic reminiscence controller to boost textual content era capabilities. Larimar’s structure combines a BERT massive encoder and a GPT-2 massive decoder with a reminiscence matrix, enabling it to retailer and retrieve info successfully. This integration permits the mannequin to make use of previous info extra precisely, decreasing the possibilities of producing hallucinated content material.
In additional element, Larimar’s methodology entails scaling the readout vectors, which act as compressed representations within the mannequin’s reminiscence. These vectors are geometrically aligned with the write vectors to attenuate distortions throughout textual content era. This course of doesn’t require extra coaching, making it extra environment friendly than conventional strategies. The researchers used Larimar and a hallucination benchmark dataset of Wikipedia-like biographies to check its effectiveness. By manipulating the readout vectors’ size by means of scaling, they discovered important reductions in hallucinations.
The Larimar mannequin demonstrated superior efficiency in experiments in comparison with the present GRACE methodology, which makes use of dynamic key-value adapters for mannequin modifying. Particularly, the Larimar mannequin confirmed substantial enhancements in producing factual content material. For example, when scaling by an element of 4, Larimar achieved a RougeL rating of 0.72, in comparison with GRACE’s 0.49, indicating a 46.9% enchancment. Moreover, Larimar’s Jaccard similarity index reached 0.69, considerably greater than GRACE’s 0.44. These metrics underscore Larimar’s effectiveness in producing extra correct textual content with fewer hallucinations.
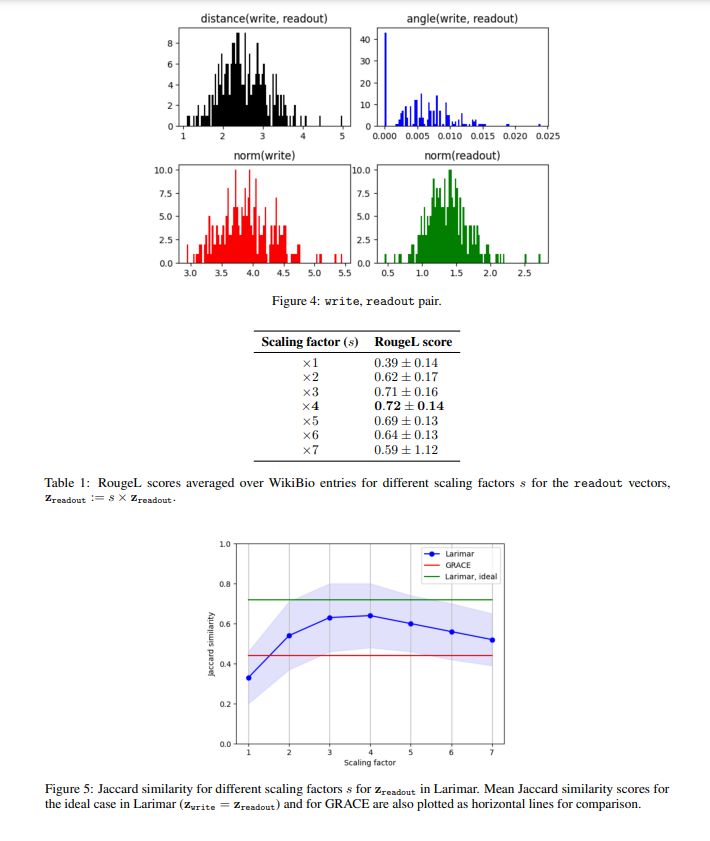
The Larimar mannequin’s method to mitigating hallucinations affords a promising answer by using light-weight reminiscence operations. This methodology simplifies the method quicker and extra successfully than training-intensive approaches like GRACE. For example, producing a WikiBio entry with Larimar took roughly 3.1 seconds on common, in comparison with GRACE’s 37.8 seconds, showcasing a considerable pace benefit. Furthermore, Larimar’s memory-based methodology aligns reminiscence vectors to scale back hallucinations, making certain greater factual accuracy in generated textual content.
In conclusion, the analysis from IBM Analysis and T. J. Watson Analysis Heart highlights a novel and environment friendly methodology to handle hallucinations in LLMs. By leveraging memory-augmented fashions like Larimar and using a geometry-inspired scaling method, the researchers have made important strides in enhancing the reliability of AI-generated content material. This method simplifies the method and ensures higher efficiency and accuracy. Because of this, Larimar’s methodology may pave the best way for extra reliable purposes of LLMs throughout varied essential fields, making certain that AI-generated content material is dependable and correct.
Take a look at the Paper. All credit score for this analysis goes to the researchers of this mission. Additionally, don’t neglect to comply with us on Twitter and be part of our Telegram Channel and LinkedIn Group. Should you like our work, you’ll love our publication..
Don’t Neglect to hitch our 47k+ ML SubReddit
Discover Upcoming AI Webinars right here
Nikhil is an intern guide at Marktechpost. He’s pursuing an built-in twin diploma in Supplies on the Indian Institute of Know-how, Kharagpur. Nikhil is an AI/ML fanatic who’s all the time researching purposes in fields like biomaterials and biomedical science. With a powerful background in Materials Science, he’s exploring new developments and creating alternatives to contribute.
[ad_2]