[ad_1]
Think about giving what you are promoting an clever bot to speak to prospects. Chatbots are generally used to speak to prospects and supply them with assist or info. However, the standard chatbots generally wrestle to reply sophisticated questions.
What’s RAG?
Retrieval Augmented Technology (RAG) is a technique that makes chatbots higher at understanding and responding to robust questions. This Generative AI design sample combines massive language fashions (LLMs) with exterior data retrieval. It permits real-time knowledge to be built-in into your AI functions throughout the era course of (inference time). By offering the LLM with this contextual info, RAG considerably improves the accuracy and high quality of the generated outputs.
Listed below are among the advantages of utilizing RAG:
- Improved accuracy and high quality of AI functions: By offering real-time knowledge as context to the LLM, RAG can enhance the accuracy and high quality of AI functions. It is because the LLM has entry to extra info, which it may use to generate extra knowledgeable and related responses.
- Means to deal with various kinds of knowledge: RAG can deal with various kinds of knowledge, together with unstructured knowledge like paperwork and emails and structured knowledge like tables. This makes it a flexible software that can be utilized in quite a lot of functions.
- Extra dynamic and versatile responses to consumer queries: RAG can generate extra dynamic and versatile responses to consumer queries, resembling limiting responses based mostly on consumer pursuits or knowledge entry controls. This makes RAG chatbots extra partaking and useful for customers, with safety controls.
- Decreased up-front prices and sooner growth: RAG may be deployed shortly and simply with out intensive growth work or LLM fine-tuning.
Databricks and Pinecone
Pinecone’s vector database excels at managing advanced knowledge searches with pinpoint accuracy, whereas the Databricks Information Intelligence Platform streamlines the dealing with and evaluation of huge datasets.
The combination with Pinecone is seamless, enabling Databricks to effectively retailer and retrieve vector embeddings at scale. This integration simplifies the event of high-performance vector search functions that leverage Pinecone and Databricks.
Utilizing Databricks and Pinecone collectively, you’ll be able to create a extra correct and environment friendly chatbot than conventional chatbots.
Step-by-Step Implementation
On this weblog, we stroll you thru constructing a chatbot that may reply any questions round Databricks, by leveraging Databricks documentation and whitepapers.
There are 4 key phases required in constructing a chatbot. The primary stage is ingesting and knowledge preparation. The subsequent stage is storing the info in a vector database like Pinecone, for environment friendly info retrieval. The third stage is to arrange a RAG retriever and chain that makes use of Pinecone for retrieval and an LLM like Llama 3.1 to generate responses. The ultimate stage is registering the chatbot to Databricks Unity Catalog and deploying it by way of Databricks Mosaic AI Mannequin Serving. Proceed studying for a step-by-step walkthrough of this course of.
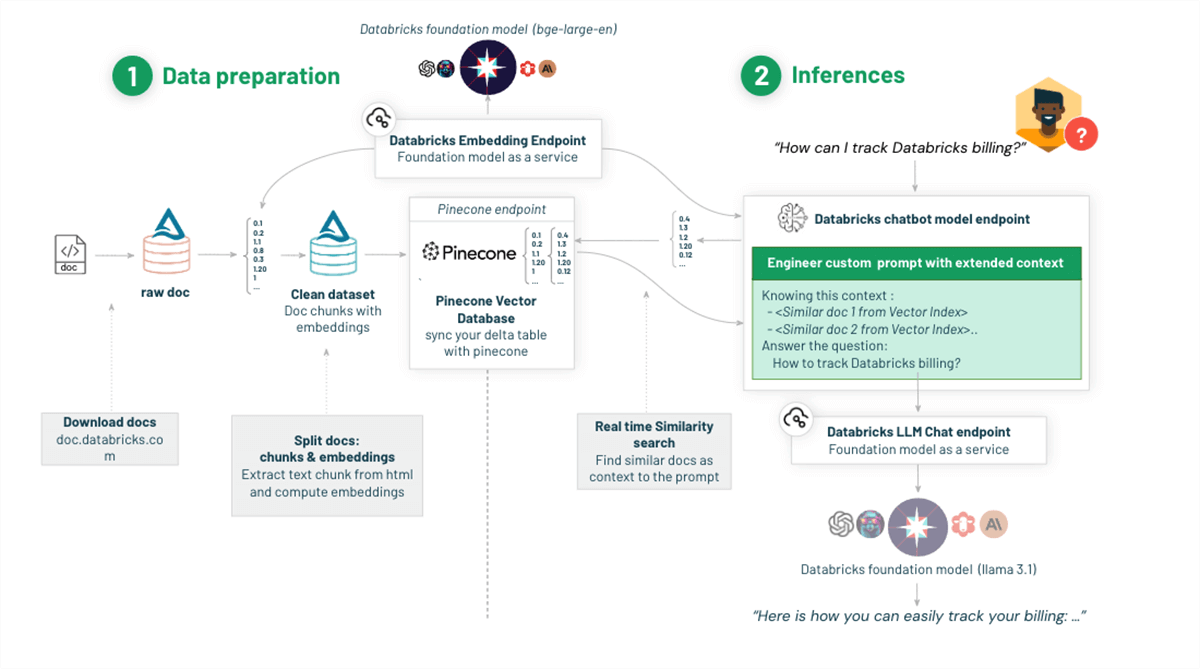
Step 1: Put together Information with Databricks
- Ingest uncooked information situated on cloud storage utilizing Databricks Autoloader.
We use Databricks autoloader, which gives a hands-off method that robotically processes new information as they land in cloud storage, guaranteeing effectivity and fault tolerance with out the necessity for handbook state administration. Databricks Autoloader is designed to scale to billions of information, and is cost-effective, leveraging native cloud APIs for file discovery to maintain prices in examine. Furthermore, Auto Loader is clever, with built-in schema inference and evolution capabilities that adapt to schema modifications. Whether or not you are coping with excessive volumes of knowledge or require near-real-time ingestion, Auto Loader helps simplify and speed up the info ingest course of. Streaming tables present a way more simplified expertise, particularly for dealing with streaming or incremental knowledge processing. - Extract the textual content from the pdf / html information.
First, we have to rework the byte content material of PDF information into readable textual content and retrieve particular segments from the textual content. On this reference implementation, we leverage the PyPdf or UnstructuredIO libraries with a Spark UDF to simplify the textual content extraction course of. We additionally use a textual content splitter to interrupt the textual content into manageable chunks. - Create vector embeddings and save them to a Delta desk.
For creating the vector embeddings, we use the BGE embedding mannequin out there by way of Databricks Mosaic AI Foundational Mannequin API. A Python UDF computes the embeddings utilizing the foundational mannequin endpoints. The extracted knowledge from the PDFs and embeddings are then saved in a Delta desk.
Step 2: Retailer Information in a Pinecone vector database
- Initialize Pinecone consumer configs.
Whenever you upsert vector embeddings into Pinecone, you will first create an index. An index is a bunch of embeddings with the identical variety of dimensions and usually represents the underlying dataset for related forms of use instances. Log in to Pinecone to create a Pinecone API key.
Databricks Secrets and techniques securely handle and retailer delicate info resembling passwords, API keys, and different credentials that you could be want to make use of inside your Databricks notebooks, jobs, and knowledge pipelines. We use Databricks secrets and techniques to retailer delicate info just like the Pinecone API key and different required credentials.
The beneath reveals how one can retrieve delicate info, such because the Pinecone API key, utilizing Databricks secrets and techniques. Then, utilizing your Pinecone API key and atmosphere, initialize your consumer connection to Pinecone.
# Initialize pinecone import pinecone from pinecone import Pinecone pinecone_api_key = dbutils.secrets and techniques.get("your_secrets_scope", "PINECONE_API_KEY") project_name = "Starter" # your-pinecone-project-name index_name = "dbdemo-index" # your-pinecone-index-name # connect with pinecone index computer = Pinecone(api_key=api_key) index = computer.Index(index_name) - You then create a Pinecone index both utilizing the Pinecone UI or the API.
computer.create_index( title= index_name, # pinecone index title dimension=1536, metric="cosine", spec=ServerlessSpec( cloud="aws", area="us-east-1" ) ) - Remodel knowledge to the schema required by Pinecone.
Pinecone allows you to connect metadata key-value pairs to vectors in an index. This can be utilized to retailer the unique doc and its metadata and to specify further filter expressions. Earlier than we will write to Pinecone, we rework the info from the delta desk by including a metadata column that captures the content material/snippet of the unique doc and extra metadata like doc supply and ID, in accordance with Pinecone’s schema necessities.
from pyspark.sql.capabilities import col, lit, struct, to_json from pyspark.sql.capabilities import encode df = spark.desk('databricks_pdf_documentation') .withColumn("metadata", to_json(struct(col("content material"), col("url"), col("id")))) .withColumn("namespace", lit("dbdemo-namespace")) .withColumn("values", col("embedding")) .withColumn("sparse_values", lit(None)) .choose("id", "values", "namespace", "metadata", "sparse_values") - Write to the Pinecone index.
Set up the Pinecone spark connector as described within the documentation. We use the Pinecone spark connector to write down the embeddings to the Pinecone index. Word that mode “append” permits us to reinforce the index with new knowledge as properly.
#write to pinecone ( df.write .possibility("pinecone.apiKey", api_key) .possibility("pinecone.indexName", index_name) .format("io.pinecone.spark.pinecone.Pinecone") .mode("append") .save() )
Step 3: Question the Pinecone vector database
We then can question the Pinecone vector index, utilizing the question API. This API takes the query embedding as enter.
# UDF for embedding
from pyspark.sql.sorts import *
def get_embedding_for_string(textual content):
response = deploy_client.predict(endpoint="databricks-bge-large-en", inputs={"enter": textual content})
e = response.knowledge
return e[0]['embedding']
#register as udf
get_embedding_for_string_udf = udf(get_embedding_for_string, ArrayType(FloatType()))
# Querying the pinecone vector database
query = "How can I observe billing utilization on my workspaces?"
# create the question embedding
xq = get_embedding_for_string(query)
# question pinecone the highest 5 most related outcomes
query_response = index.question(
namespace='dbdemo-namespace',
top_k=5,
include_values=True,
include_metadata=True,
vector=xq
)
#print(query_response)
query_response_docs = []
for match in query_response['matches']:
query_response_docs.append([match['metadata']['url'],match['metadata']['content'],match['score']])
print(query_response_docs)Querying Pinecone immediately by way of the API lets you combine Pinecone and Databricks into arbitrary code.

Within the subsequent part, we present the best way to simplify this workflow utilizing the favored LangChain framework.
Step 4: Question a Pinecone vector database utilizing LangChain
Langchain is a framework that simplifies constructing functions powered by LLMs (massive language fashions). Its Databricks Embeddings assist simplify interacting with embedding fashions, and its integration with Pinecone offers a simplified question interface.
Langchain wrappers make it simple, by dealing with all of the underlying logic and API requires you. The LangChain code beneath abstracts away the necessity to explicitly convert the question textual content to a vector.
import pinecone
from langchain_community.embeddings import DatabricksEmbeddings
from langchain.chains import RetrievalQA
from pinecone import Pinecone
from langchain_pinecone import PineconeVectorStore
import os
#Creating the enter query embeddings (with Databricks `bge-large-en`)
embedding_model = DatabricksEmbeddings(endpoint="databricks-bge-large-en")
# connect with pinecone index
computer = Pinecone(api_key=pinecone_api_key)
index_pc = computer.Index(pinecone_index_name)
vectorstore = PineconeVectorStore(
index=index_pc,
namespace=pinecone_namespace,
embedding=embedding_model,
text_key="content material"
)
#Calling the Pinecone vector database to seek out related paperwork
question = "What's Apache Spark?"
docs = vectorstore.similarity_search(
question, # our search question
ok=3 # return 3 most related docs
)
pprint(docs[0])Step 5: Create a retriever for Pinecone and LangChain
Above, we confirmed the best way to do a similarity search on our Pinecone vector index. To create a RAG chatbot, we’ll use the LangChain Retriever interface to wrap the index.
We first provoke Pinecone to set the API key and atmosphere. Then, we create a VectorStore occasion from the present Pinecone index we created earlier, with the right namespace and keys.
from langchain_community.embeddings import DatabricksEmbeddings
from langchain.chains import RetrievalQA
from pinecone import Pinecone
from langchain_pinecone import PineconeVectorStore
embedding_model = DatabricksEmbeddings(endpoint="databricks-bge-large-en")
def get_retriever(persist_dir: str = None):
# initialize pinecone and connect with pinecone index
computer = Pinecone(api_key=pinecone_api_key)
index_pc = computer.Index(pinecone_index_name)
vectorstore = PineconeVectorStore(
index=index_pc,
namespace=pinecone_namespace,
embedding=embedding_model,
text_key="content material"
)
return vectorstore.as_retriever()
retriever = get_retriever()Step 6: Assemble the chatbot chain
Now, we will put the retriever into a series defining our chatbot!
retrieve_document_chain = (
itemgetter("messages")
| RunnableLambda(extract_question)
| retriever
)
#check the retriever chain
print(retrieve_document_chain.invoke({"messages": [{"role": "user", "content": "What is Apache Spark?"}]}))Let’s examine if our chatbot can accurately extract the query from the chat messages and retrieve related context from Pinecone.

Step 7: Deploy the chatbot as a mannequin
As we iterate on our chatbot, we’ll wish to observe mannequin objects, mannequin variations, and metadata, in addition to handle entry controls. For that, we’ll use MLflow’s Mannequin Registry, built-in with Unity Catalog.
You may register the chatbot chain as a mannequin utilizing mlflow.langchain.log_model, with the Unity Catalog. The signature of the mannequin may be inferred utilizing infer_signature in mlflow. Bear in mind to place pinecone-client into the dependencies. Set "mlflow.fashions.set_model(mannequin=full_chain)" within the pocket book the place you outlined the chain. In a brand new driver pocket book, register the chatbot and deploy chatbot to Mannequin Serving.
from mlflow.fashions import infer_signature
import mlflow
import langchain
import pandas as pd
mlflow.set_registry_uri("databricks-uc")
model_name = f"{catalog_name}.{schema_name}.rag_with_pinecone_model" #catalog_name, schema_name and mannequin title
# Specify the complete path to the chain pocket book
chain_notebook_file = "2.1 - Superior-Chatbot-Chain - Utilizing Pinecone" # the title of the pocket book that has the chain definition
chain_notebook_path = os.path.be a part of(os.getcwd(), chain_notebook_file)
with mlflow.start_run():
signature = infer_signature(input_example, output_example)
logged_chain_info = mlflow.langchain.log_model(
lc_model=chain_notebook_path,
artifact_path="chain",
registered_model_name=model_name,
input_example=input_example,
signature=signature,
example_no_conversion=True, # required to permit the schema to work
extra_pip_requirements=[
"mlflow==" + mlflow.__version__,
"langchain==" + langchain.__version__,
"pinecone-client==3.2.2",
"langchain-pinecone==0.1.1",
"langchain-community",
]
)The mannequin is registered with Databricks Unity Catalog, which centralizes entry management, auditing, lineage, and discovery for all knowledge and AI property.

Step 8: Deploy the chatbot to Databricks Mannequin Serving
Now let’s deploy the chatbot chain mode as a Mannequin Serving endpoint. Under, we put PINECONE_API_KEY and DATABRICKS_TOKEN into the atmosphere variables because the serving endpoint will use them to speak to Pinecone and Databricks Basis Fashions. This permits us to grant entry to the served mannequin, with out revealing these secrets and techniques in code or to customers.
# Create or replace serving endpoint
from databricks.sdk import WorkspaceClient
from databricks.sdk.service.serving import EndpointCoreConfigInput, ServedModelInput, ServedModelInputWorkloadSize
import requests
# Verify for contemporary mannequin model
def get_latest_model_version(model_name):
from mlflow import MlflowClient
mlflow_client = MlflowClient()
latest_version = 1
for mv in mlflow_client.search_model_versions(f"title='{model_name}'"):
version_int = int(mv.model)
if version_int > latest_version:
latest_version = version_int
return latest_version
# Now Create or replace serving endpoint
serving_endpoint_name = "pinecone_rag_chain"
latest_model_version = get_latest_model_version(model_name)
databricks_api_token = dbutils.pocket book.entry_point.getDbutils().pocket book().getContext().apiToken().get()
w = WorkspaceClient()
endpoint_config = EndpointCoreConfigInput(
title=serving_endpoint_name,
served_models=[
ServedModelInput(
model_name=model_name,
model_version=latest_model_version,
workload_size=ServedModelInputWorkloadSize.SMALL,
scale_to_zero_enabled=True,
environment_vars={
"PINECONE_API_KEY": "{{secrets/prasad_kona/PINECONE_API_KEY}}",
"DATABRICKS_TOKEN": "{{secrets/dbdemos/rag_sp_token}}",
}
)
]
)
existing_endpoint = subsequent(
(e for e in w.serving_endpoints.listing() if e.title == serving_endpoint_name), None
)
serving_endpoint_url = f"{host}/ml/endpoints/{serving_endpoint_name}"
if existing_endpoint == None:
print(f"Creating the endpoint {serving_endpoint_url}, this may take a couple of minutes to bundle and deploy the endpoint...")
w.serving_endpoints.create_and_wait(title=serving_endpoint_name, config=endpoint_config)
else:
print(f"Updating the endpoint {serving_endpoint_url} to model {latest_model_version}, this may take a couple of minutes to bundle and deploy the endpoint...")
w.serving_endpoints.update_config_and_wait(served_models=endpoint_config.served_models, title=serving_endpoint_name)
displayHTML(f'Your Mannequin Endpoint Serving is now out there. Open the <a href="/ml/endpoints/{serving_endpoint_name}">Mannequin Serving Endpoint web page</a> for extra particulars.')The Mannequin Serving UI offers real-time info on the well being of the mannequin being served.
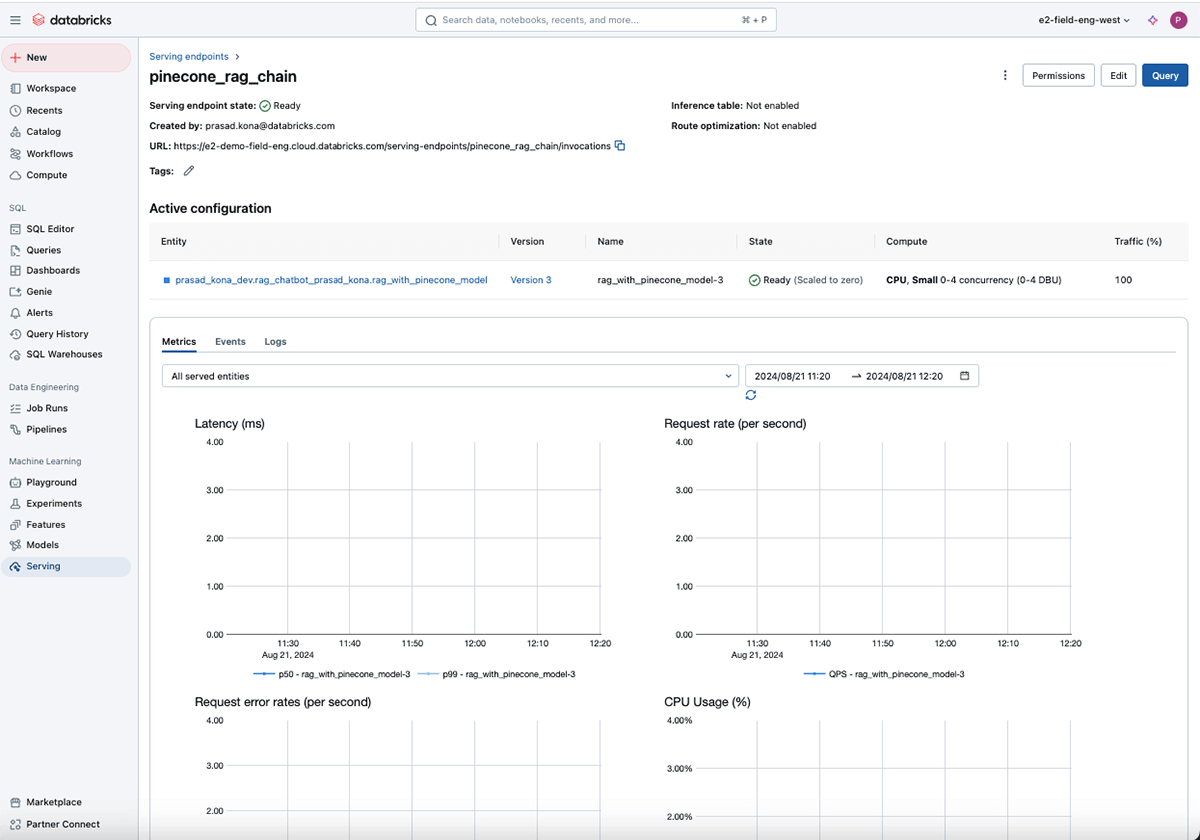
Step 9: Check your chatbot
After deploying the chatbot, you’ll be able to check it with a REST API or Databricks SDK.
from databricks.sdk.service.serving import DataframeSplitInput
test_dialog = DataframeSplitInput(
columns=["messages"],
knowledge=[
{
"messages": [
{"role": "user", "content": "What is Apache Spark?"},
{
"role": "assistant",
"content": "Apache Spark is an open-source data processing engine that is widely used in big data analytics.",
},
{"role": "user", "content": "Does it support streaming?"},
]
}
],
)
reply = w.serving_endpoints.question(serving_endpoint_name, dataframe_split=test_dialog)
print(reply.predictions[0])You may as well check it utilizing the Question UI out there as a part of mannequin serving.
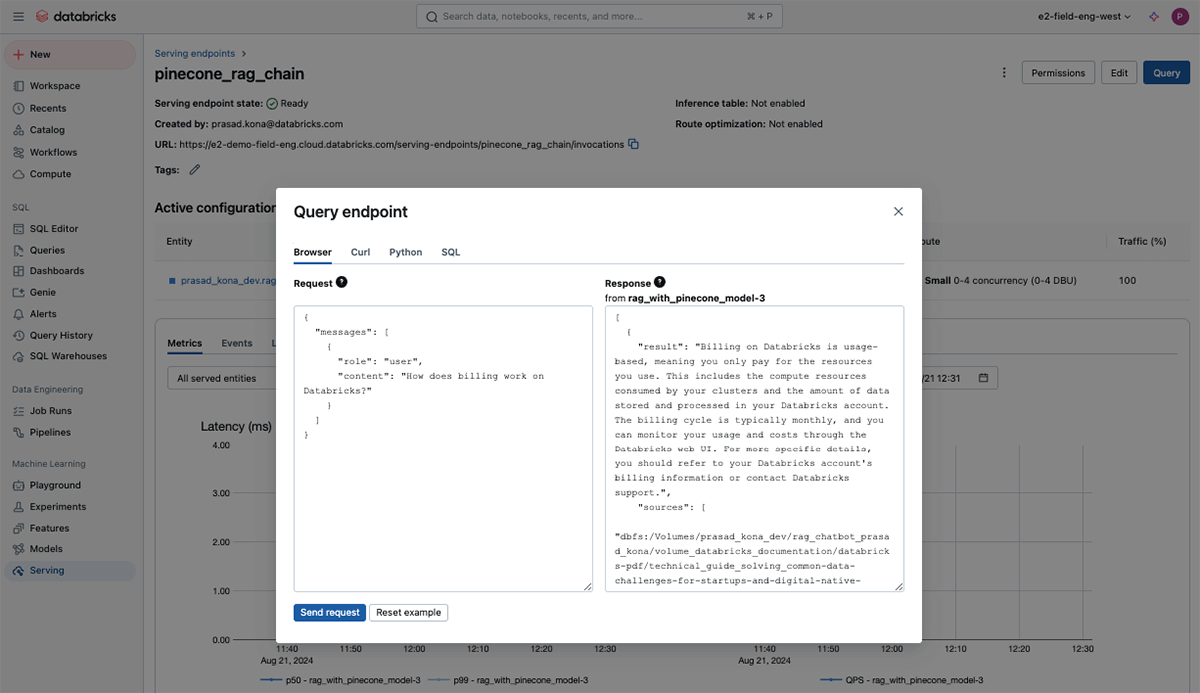
Subsequent steps
Enhance your customer support with Databricks and Pinecone by deploying cutting-edge RAG chatbots. In contrast to conventional bots, these superior chatbots leverage the Databricks Information Intelligence Platform and Pinecone’s vector database to ship exact, well timed responses. They quickly sift by means of huge knowledge to seek out the precise info wanted, offering prospects with correct solutions in seconds. This not solely elevates the shopper expertise but additionally units a brand new benchmark for digital engagement.
For enterprise leaders, embracing this know-how is extra than simply an improve—it is a strategic transfer to steer in customer support innovation. By adopting data-driven, clever options, you’ll be able to place what you are promoting on the forefront of buyer engagement, showcasing a dedication to excellence that resonates together with your viewers.
Try our free coaching to study extra about Generative AI with Databricks, and skim further Pinecone and Databricks documentation right here. Entry pattern notebooks from this weblog right here.
[ad_2]