[ad_1]
Current years have seen important advances in neural language fashions, notably Giant Language Fashions (LLMs) enabled by the Transformer structure and elevated scale. LLMs exhibit distinctive expertise in producing grammatical textual content, answering questions, summarising content material, creating imaginative outputs, and fixing complicated puzzles. A key functionality is in-context studying (ICL), the place the mannequin makes use of novel job exemplars introduced throughout inference to reply precisely with out weight updates. ICL is often attributed to Transformers and their attention-based mechanisms.
ICL has been proven for linear regression duties with Transformers, which might generalize to new enter/label pairs in-context. Transformers obtain this by doubtlessly implementing gradient descent or replicating least-squares regression. Transformers interpolate between in-weight studying (IWL) and ICL, with numerous datasets enhancing ICL capabilities. Whereas most research concentrate on Transformers, some analysis explores recurrent neural networks (RNNs) and LSTMs, with combined outcomes. Current findings spotlight varied causal sequence fashions and state house fashions additionally reaching ICL. Nonetheless, MLPs’ potential for ICL stays underexplored regardless of their resurgence in complicated duties, prompted by the introduction of the MLP-Mixer mannequin.
On this research researchers from Harvard reveal that multi-layer perceptrons (MLPs) can successfully study in-context. MLPs and MLPMixer fashions carry out competitively with Transformers on ICL duties throughout the identical compute price range. Significantly, MLPs outperform Transformers in relational reasoning ICL duties, difficult the idea that ICL is exclusive to Transformers. This success suggests exploring past attention-based architectures and signifies that Transformers, constrained by self-attention and positional encodings, could also be biased away from sure job constructions in comparison with MLPs.
The research investigates MLPs’ habits in ICL by two duties: in-context regression and in-context classification. For ICL regression, the enter is a sequence of linearly associated worth pairs (xi, yi), with various weights β and added noise, plus a question xq. The mannequin predicts the corresponding yq by inferring β from the context exemplars. For ICL classification, the enter is a sequence of exemplars (xi, yi) adopted by a question xq, sampled from a Gaussian combination mannequin. The mannequin predicts the right label for xq by referencing the context exemplars, contemplating information range and burstiness (Variety of repeats per cluster within the context).
MLPs and Transformers had been in contrast on in-context regression and classification duties. Each architectures, together with MLP-Mixers, achieved near-optimal imply squared error (MSE) with enough computing, though Transformers barely outperformed MLPs for smaller computing budgets. For longer context lengths, vanilla MLPs carried out worse, whereas MLP-Mixers maintained optimum MSE. As information range elevated, all fashions transitioned from IWL to ICL, with Transformers making the transition extra shortly. In in-context classification, MLPs carried out comparably to Transformers, sustaining comparatively flat loss throughout context lengths and transitioning from IWL to ICL with elevated information range.
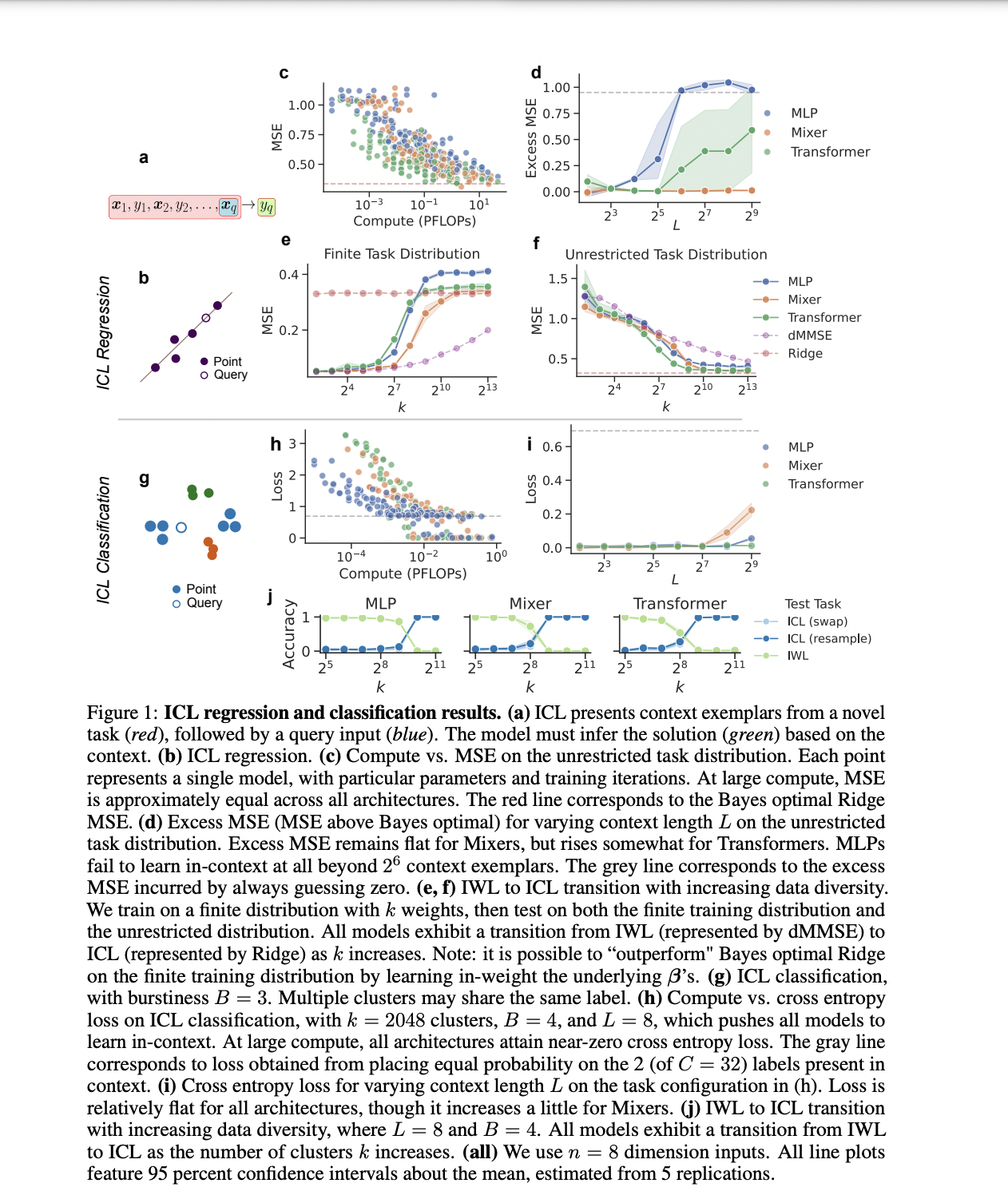
On this work, Harvard researchers evaluate MLPs and Transformers on in-context regression and classification duties. All architectures, together with MLP-Mixers, achieved near-optimal MSE with enough compute, though Transformers barely outperformed MLPs with smaller compute budgets. Vanilla MLPs carried out worse with longer context lengths, whereas MLP-Mixers maintained optimum MSE. As information range elevated, all fashions transitioned from IWL to ICL, with Transformers making the transition extra shortly. In in-context classification, MLPs carried out comparably to Transformers, sustaining flat loss throughout context lengths and transitioning from IWL to ICL as information range elevated.
Take a look at the Paper. All credit score for this analysis goes to the researchers of this undertaking. Additionally, don’t neglect to comply with us on Twitter. Be part of our Telegram Channel, Discord Channel, and LinkedIn Group.
When you like our work, you’ll love our e-newsletter..
Don’t Neglect to hitch our 43k+ ML SubReddit | Additionally, try our AI Occasions Platform
Asjad is an intern advisor at Marktechpost. He’s persuing B.Tech in mechanical engineering on the Indian Institute of Know-how, Kharagpur. Asjad is a Machine studying and deep studying fanatic who’s at all times researching the functions of machine studying in healthcare.
[ad_2]