[ad_1]
Massive Language Fashions (LLMs) have made vital strides in recent times, prompting researchers to discover the event of Massive Imaginative and prescient Language Fashions (LVLMs). These fashions goal to combine visible and textual info processing capabilities. Nonetheless, present open-source LVLMs face challenges in matching the flexibility of proprietary fashions like GPT-4, Gemini Professional, and Claude 3. The first obstacles embody restricted range in coaching knowledge and difficulties in dealing with long-context enter and output. Researchers are striving to boost open-source LVLMs’ capability to carry out a variety of vision-language comprehension and composition duties, bridging the hole between open-source and closed-source main paradigms by way of versatility and efficiency throughout varied benchmarks.
Researchers have made vital efforts to deal with the challenges in creating versatile LVLMs. These approaches embody text-image dialog fashions, high-resolution picture evaluation strategies, and video understanding strategies. For text-image conversations, most current LVLMs deal with single-image multi-round interactions, with some extending to multi-image inputs. Excessive-resolution picture evaluation has been tackled by two primary methods: high-resolution visible encoders and picture patchification. Video understanding in LVLMs has employed strategies equivalent to sparse sampling, temporal pooling, compressed video tokens, and reminiscence banks.
Additionally, researchers have explored webpage era, transferring from easy UI-to-code transformations to extra complicated duties utilizing giant vision-language fashions skilled on artificial datasets. Nonetheless, these approaches usually lack range and real-world applicability. To align mannequin outputs with human preferences, strategies like Reinforcement Studying from Human Suggestions (RLHF) and Direct Choice Optimization (DPO) have been tailored for multimodal LVLMs, specializing in lowering hallucinations and enhancing response high quality.
Researchers from Shanghai Synthetic Intelligence Laboratory, The Chinese language College of Hong Kong, SenseTime Group, and Tsinghua College have launched InternLM-XComposer-2.5 (IXC-2.5), representing a major development in LVLMs, providing versatility and long-context capabilities. This mannequin excels in comprehension and composition duties, together with free-form text-image conversations, OCR, video understanding, article composition, and webpage crafting. IXC-2.5 helps a 24K interleaved image-text context window, extendable to 96K, enabling long-term human-AI interplay and content material creation.
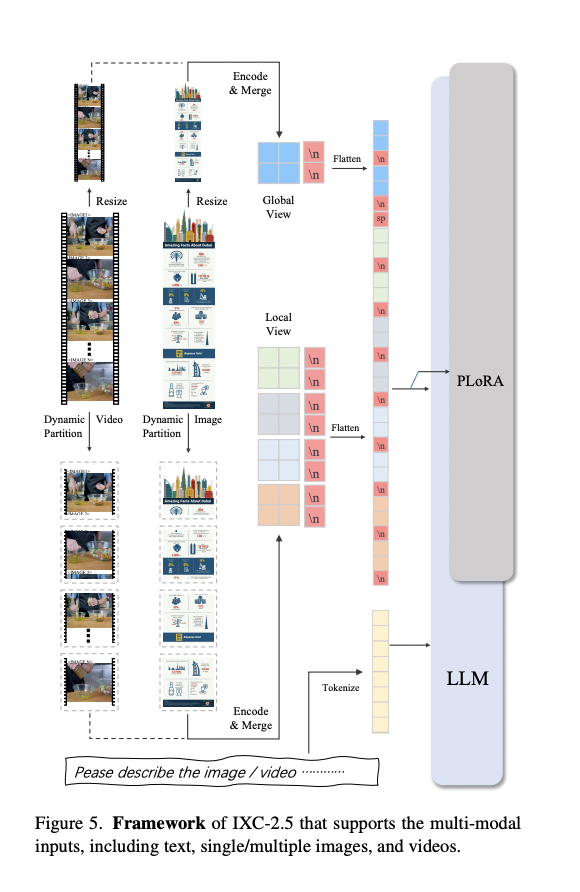
The mannequin introduces three key comprehension upgrades: ultra-high decision understanding, fine-grained video evaluation, and multi-turn multi-image dialogue help. For composition duties, IXC-2.5 incorporates further LoRA parameters, enabling webpage creation and high-quality text-image article composition. The latter advantages from Chain-of-Thought and Direct Choice Optimization strategies to boost content material high quality.
IXC-2.5 enhances its predecessors’ structure with a ViT-L/14 Imaginative and prescient Encoder, InternLM2-7B Language Mannequin, and Partial LoRA. It handles various inputs by a Unified Dynamic Picture Partition technique, processing photographs at 560×560 decision with 400 tokens per sub-image. The mannequin employs a scaled id technique for high-resolution photographs and treats movies as concatenated frames. Multi-image inputs are dealt with with interleaved formatting. IXC-2.5 additionally helps audio enter/output utilizing Whisper for transcription and MeloTTS for speech synthesis. This versatile structure permits efficient processing of assorted enter sorts and sophisticated duties.
IXC-2.5 demonstrates distinctive efficiency throughout varied benchmarks. In video understanding, it outperforms open-source fashions in 4 out of 5 benchmarks, matching closed-source APIs. For structural high-resolution duties, IXC-2.5 competes with bigger fashions, excelling in kind and desk understanding. It considerably improves multi-image multi-turn comprehension, outperforming earlier fashions by 13.8% on the MMDU benchmark. Generally visible QA duties, IXC-2.5 matches or surpasses each open-source and closed-source fashions, notably outperforming GPT-4V and Gemini-Professional on some challenges. For screenshot-to-code translation, IXC-2.5 even surpasses GPT-4V in common efficiency, showcasing its versatility and effectiveness throughout various multimodal duties.

IXC-2.5 represents a major development in Massive Imaginative and prescient-Language Fashions, providing long-contextual enter and output capabilities. This mannequin excels in ultra-high decision picture evaluation, fine-grained video comprehension, multi-turn multi-image dialogues, webpage era, and article composition. Regardless of using a modest 7B Massive Language Mannequin backend, IXC-2.5 demonstrates aggressive efficiency throughout varied benchmarks. This achievement paves the best way for future analysis into extra contextual multi-modal environments, probably extending to long-context video understanding and interplay historical past evaluation. Such developments promise to boost AI’s capability to help people in various real-world functions, marking a vital step ahead in multimodal AI know-how.
Take a look at the Paper and GitHub. All credit score for this analysis goes to the researchers of this mission. Additionally, don’t neglect to observe us on Twitter.
Be a part of our Telegram Channel and LinkedIn Group.
In case you like our work, you’ll love our e-newsletter..
Don’t Overlook to affix our 46k+ ML SubReddit
Asjad is an intern guide at Marktechpost. He’s persuing B.Tech in mechanical engineering on the Indian Institute of Know-how, Kharagpur. Asjad is a Machine studying and deep studying fanatic who’s all the time researching the functions of machine studying in healthcare.
[ad_2]