[ad_1]
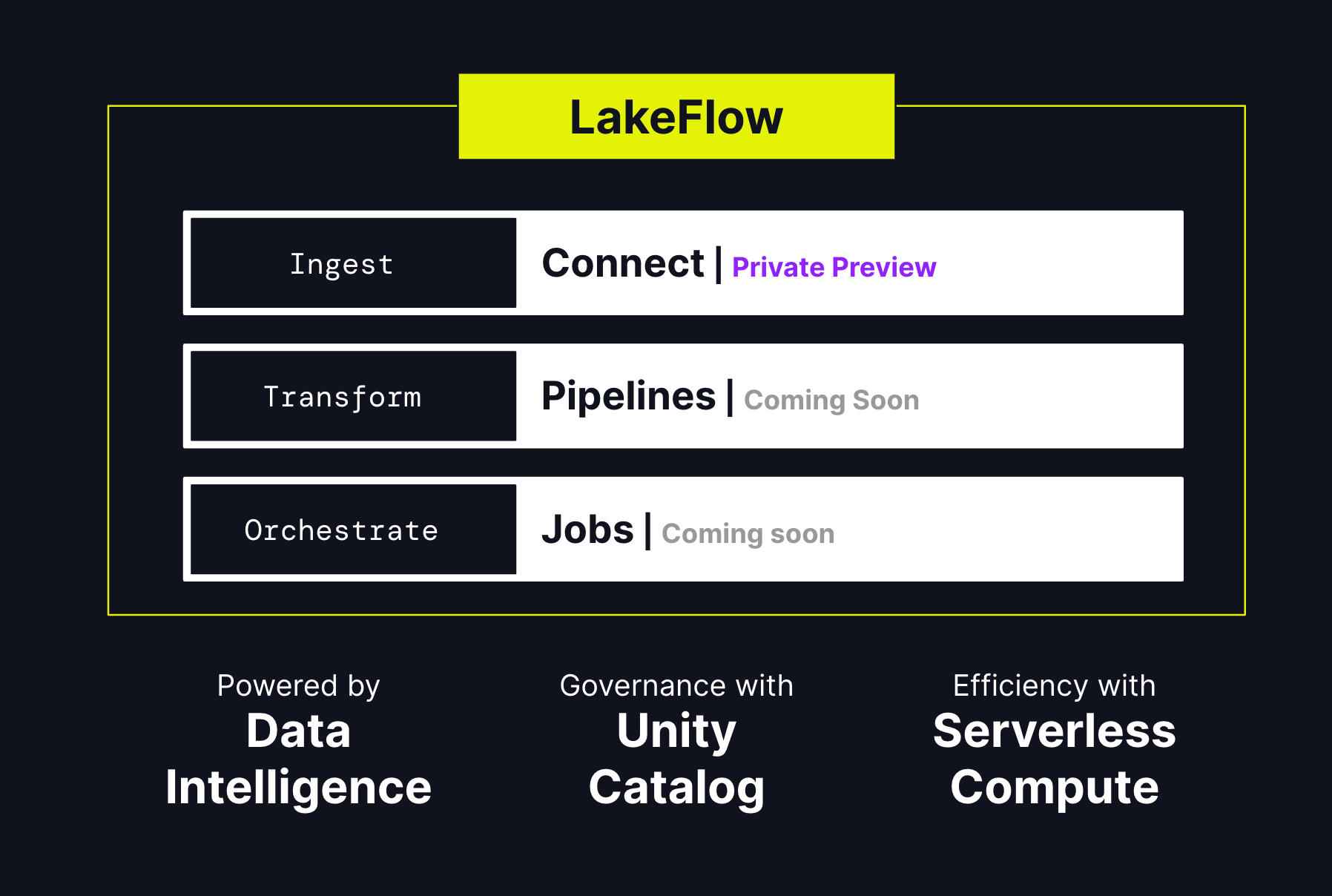
As we speak, we’re excited to announce Databricks LakeFlow, a brand new resolution that incorporates every part it is advisable construct and function manufacturing knowledge pipelines. It contains new native, extremely scalable connectors for databases together with MySQL, Postgres, SQL Server and Oracle and enterprise purposes like Salesforce, Microsoft Dynamics, NetSuite, Workday, ServiceNow and Google Analytics. Customers can remodel knowledge in batch and streaming utilizing commonplace SQL and Python. We’re additionally saying Actual Time Mode for Apache Spark, permitting stream processing at orders of magnitude quicker latencies than microbatch. Lastly, you possibly can orchestrate and monitor workflows and deploy to manufacturing utilizing CI/CD. Databricks LakeFlow is native to the Information Intelligence Platform, offering serverless compute and unified governance with Unity Catalog.
On this weblog submit we focus on the explanation why we imagine LakeFlow will assist knowledge groups meet the rising demand of dependable knowledge and AI in addition to LakeFlow’s key capabilities built-in right into a single product expertise.
Challenges in constructing and working dependable knowledge pipelines
Information engineering – accumulating and making ready contemporary, high-quality and dependable knowledge – is a mandatory ingredient for democratizing knowledge and AI in your enterprise. But attaining this stays filled with complexity and requires stitching collectively many various instruments.
First, knowledge groups must ingest knowledge from a number of techniques every with their very own codecs and entry strategies. This requires constructing and sustaining in-house connectors for databases and enterprise purposes. Simply maintaining with enterprise purposes’ API modifications generally is a full-time job for a complete knowledge group. Information then must be ready in each batch and streaming, which requires writing and sustaining advanced logic for triggering and incremental processing. When latency spikes or a failure happens, it means getting paged, a set of sad knowledge customers and even disruptions to the enterprise that have an effect on the underside line. Lastly, knowledge groups must deploy these pipelines utilizing CI/CD and monitor the standard and lineage of information property. This usually requires deploying, studying and managing one other completely new device like Prometheus or Grafana.
This is the reason we determined to construct LakeFlow, a unified resolution for knowledge ingestion, transformation, and orchestration powered by knowledge intelligence. Its three key parts are: LakeFlow Join, LakeFlow Pipelines and LakeFlow Jobs.
LakeFlow Join: Easy and scalable knowledge ingestion
LakeFlow Join offers point-and-click knowledge ingestion from databases resembling MySQL, Postgres, SQL Server and Oracle and enterprise purposes like Salesforce, Microsoft Dynamics, NetSuite, Workday, ServiceNow and Google Analytics. LakeFlow Join can even ingest unstructured knowledge resembling PDFs and Excel spreadsheets from sources like SharePoint.
It extends our common native connectors for cloud storage (e.g. S3, ADLS Gen2 and GCS) and queues (e.g. Kafka, Kinesis, Occasion Hub and Pub/Sub connectors), and accomplice options resembling Fivetran, Qlik and Informatica.
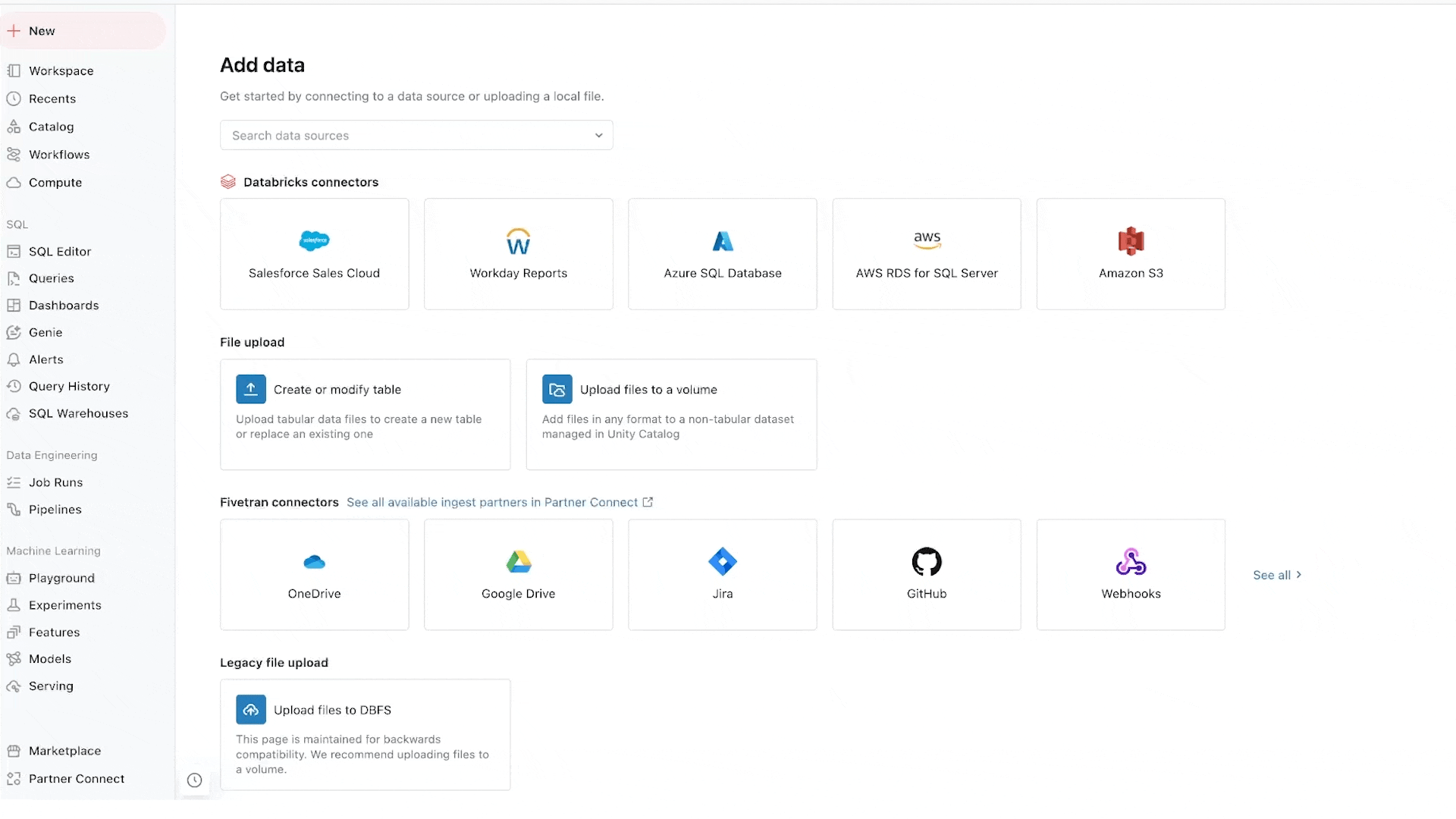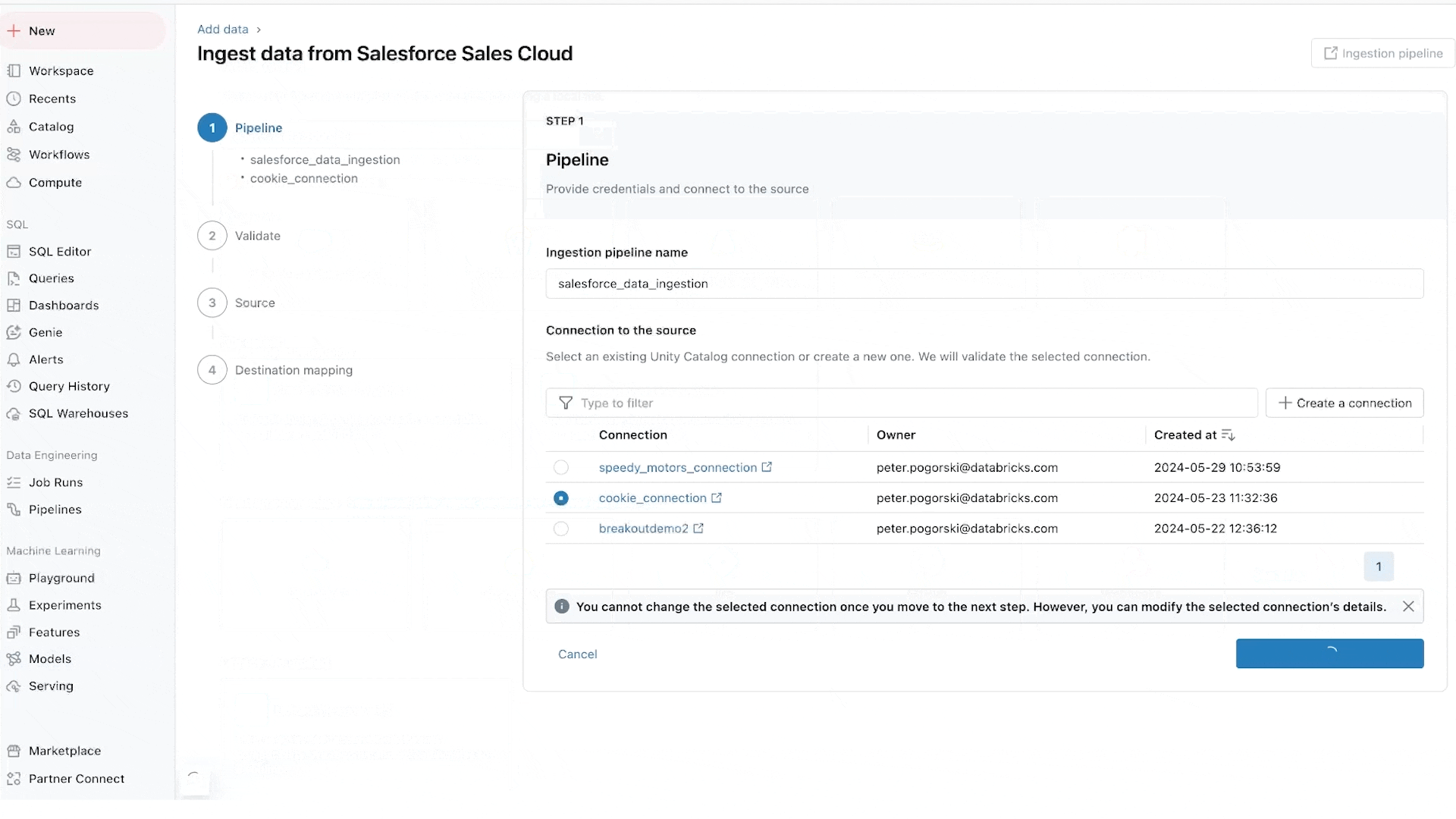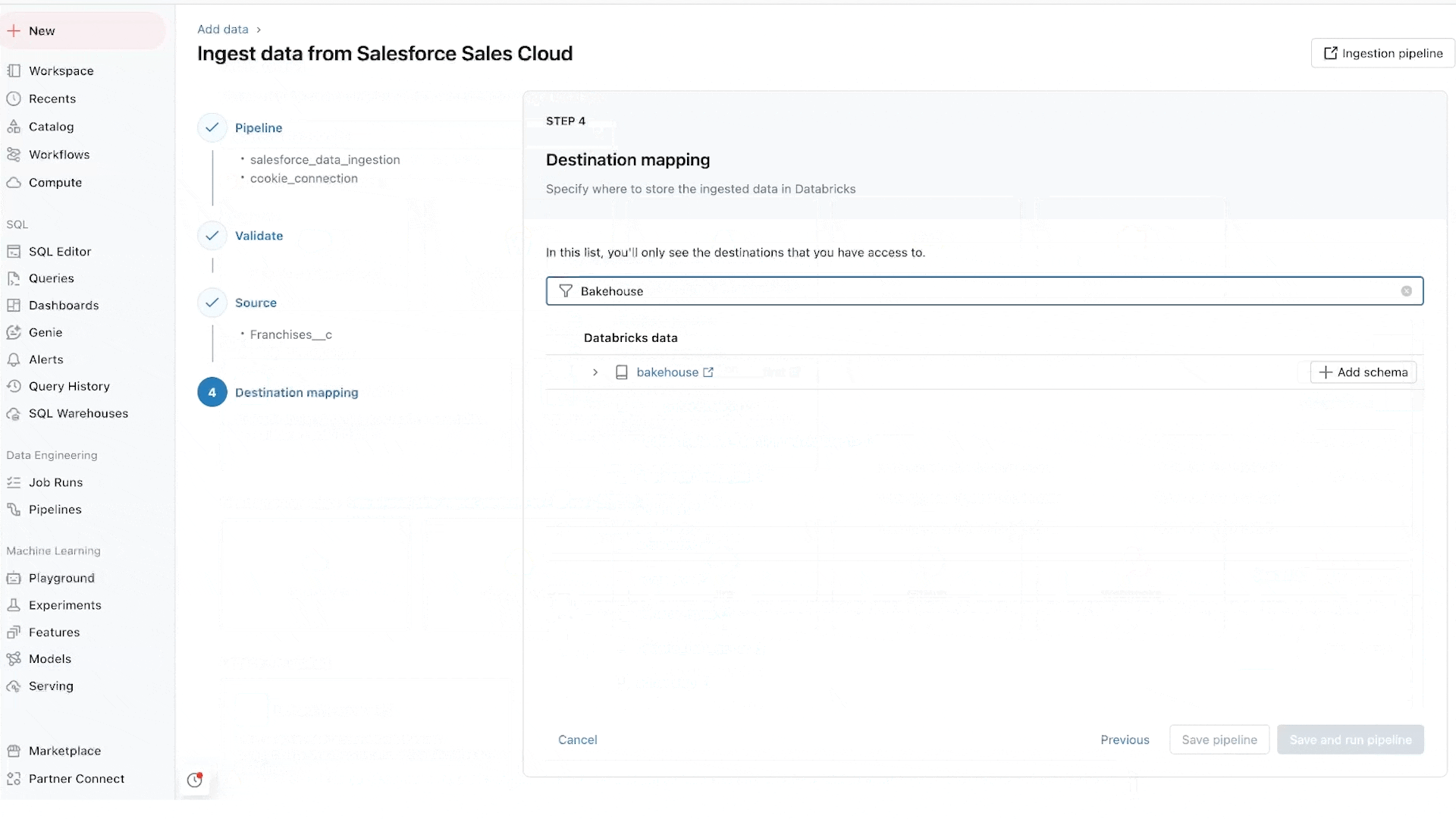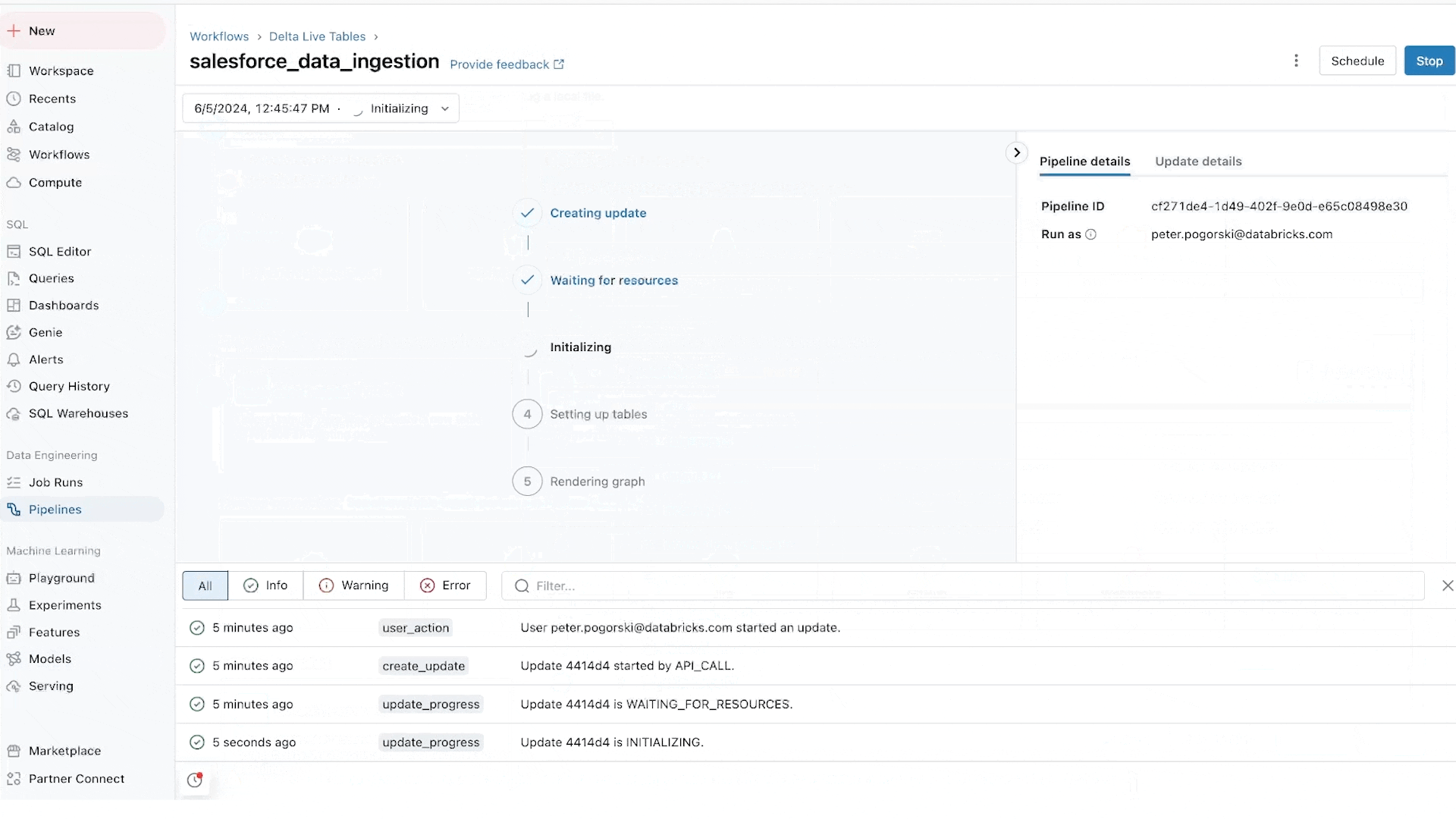
We’re notably enthusiastic about database connectors, that are powered by our acquisition of Arcion. An unbelievable quantity of worthwhile knowledge is locked away in operational databases. As an alternative of naive approaches to load this knowledge, which hit operational and scaling points, LakeFlows makes use of change knowledge seize (CDC) expertise to make it easy, dependable and operationally environment friendly to convey this knowledge to your lakehouse.
Databricks clients who’re utilizing LakeFlow Join discover {that a} easy ingestion resolution improves productiveness and lets them transfer quicker from knowledge to insights. Insulet, a producer of a wearable insulin administration system, the Omnipod, makes use of the Salesforce ingestion connector to ingest knowledge associated to buyer suggestions into their knowledge resolution which is constructed on Databricks. This knowledge is made accessible for evaluation via Databricks SQL to achieve insights relating to high quality points and monitor buyer complaints. The group discovered important worth in utilizing the brand new capabilities of LakeFlow Join.
“With the brand new Salesforce ingestion connector from Databricks, we have considerably streamlined our knowledge integration course of by eliminating fragile and problematic middleware. This enchancment permits Databricks SQL to instantly analyze Salesforce knowledge inside Databricks. Consequently, our knowledge practitioners can now ship up to date insights in near-real time, lowering latency from days to minutes.”
— Invoice Whiteley, Senior Director of AI, Analytics, and Superior Algorithms, Insulet
LakeFlow Pipelines: Environment friendly declarative knowledge pipelines
LakeFlow Pipelines decrease the complexity of constructing and managing environment friendly batch and streaming knowledge pipelines. Constructed on the declarative Delta Reside Tables framework, they free you as much as write enterprise logic in SQL and Python whereas Databricks automates knowledge orchestration, incremental processing and compute infrastructure autoscaling in your behalf. Furthermore, LakeFlow Pipelines presents built-in knowledge high quality monitoring and its Actual Time Mode allows you to allow constantly low-latency supply of time-sensitive datasets with none code modifications.
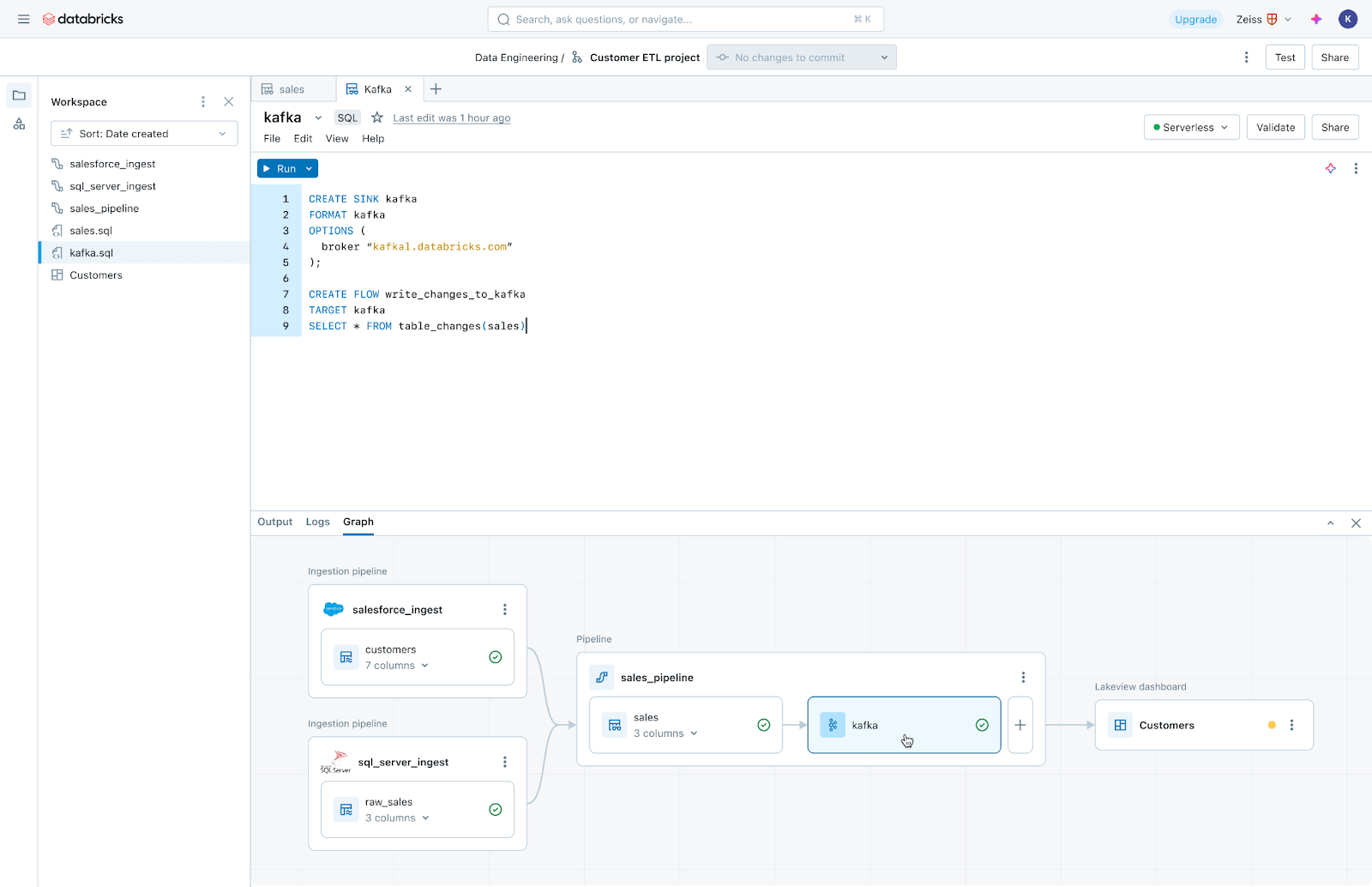
LakeFlow Jobs: Dependable orchestration for each workload
LakeFlow Jobs reliably orchestrates and displays manufacturing workloads. Constructed on the superior capabilities of Databricks Workflows, it orchestrates any workload, together with ingestion, pipelines, notebooks, SQL queries, machine studying coaching, mannequin deployment and inference. Information groups can even leverage triggers, branching and looping to fulfill advanced knowledge supply use circumstances.
LakeFlow Jobs additionally automates and simplifies the method of understanding and monitoring knowledge well being and supply. It takes a data-first view of well being, giving knowledge groups full lineage together with relationships between ingestion, transformations, tables and dashboards. Moreover, it tracks knowledge freshness and high quality, permitting knowledge groups so as to add displays through Lakehouse Monitoring with the press of a button.
Constructed on the Information Intelligence Platform
Databricks LakeFlow is natively built-in with our Information Intelligence Platform, which brings these capabilities:
- Information intelligence: AI-powered intelligence is not only a characteristic of LakeFlow, it’s a foundational functionality that touches each side of the product. Databricks Assistant powers the invention, authoring and monitoring of information pipelines, so you possibly can spend extra time constructing dependable knowledge.
- Unified governance: LakeFlow can also be deeply built-in with Unity Catalog, which powers lineage and knowledge high quality.
- Serverless compute: Construct and orchestrate pipelines at scale and assist your group give attention to work with out having to fret about infrastructure.
The way forward for knowledge engineering is straightforward, unified and clever
We imagine that LakeFlow will allow our clients to ship brisker, extra full and higher-quality knowledge to their companies. LakeFlow will enter preview quickly beginning with LakeFlow Join. If you need to request entry, enroll right here. Over the approaching months, search for extra LakeFlow bulletins as further capabilities turn into accessible.
[ad_2]