[ad_1]
We’re excited to announce a brand new knowledge kind known as variant for semi-structured knowledge. Variant supplies an order of magnitude efficiency enhancements in contrast with storing these knowledge as JSON strings, whereas sustaining the pliability for supporting extremely nested and evolving schema.
Working with semi-structured knowledge has lengthy been a foundational functionality of the Lakehouse. Endpoint Detection & Response (EDR), Advert-click evaluation, and IoT telemetry are simply a few of the common use instances that depend on semi-structured knowledge. As we migrate an increasing number of clients from proprietary knowledge warehouses, we’ve got heard that they depend on the variant knowledge kind these proprietary warehouses supply, and would like to see an open supply commonplace for that to keep away from any lock-in.
The open variant kind is the results of our collaboration with each the Apache Spark open-source neighborhood and the Linux Basis Delta Lake neighborhood:
- The Variant knowledge kind, Variant binary expressions, and the Variant binary encoding format are already merged in open supply Spark. Particulars in regards to the binary encoding could be reviewed right here.
- The binary encoding format permits for sooner entry and navigation of the information when in comparison with Strings. The implementation of the Variant binary encoding format is packaged in an open-source library, in order that it may be utilized in different tasks.
- Help for the Variant knowledge kind can be open-sourced to Delta, and the protocol RFC could be discovered right here. Variant help will likely be included in Spark 4.0 and Delta 4.0.
“We’re a supporter of the open supply neighborhood with a give attention to knowledge by way of our open sourced knowledge platform Legend,” stated Neema Raphael, Chief Knowledge Officer and Head of Knowledge Engineering at Goldman Sachs. “The launch of Open Supply Variant in Spark is one other nice step ahead for an open knowledge ecosystem.”
And beginning DBR 15.3, the entire aforementioned capabilities will likely be out there for our clients to make use of.
What’s Variant?
Variant is a brand new knowledge kind for storing semi-structured knowledge. Within the Public Preview of the upcoming Databricks Runtime 15.3 launch, ingress and egress of hierarchical knowledge by way of JSON will likely be supported. With out Variant, clients had to decide on between flexibility and efficiency. To keep up flexibility, clients would retailer JSON in single columns as strings. To see higher efficiency, clients would apply strict schematizing approaches with structs, which requires separate processes to keep up and replace with schema modifications. With Variant, clients can retain flexibility (there isn’t any have to outline an express schema) and obtain vastly improved efficiency in comparison with querying the JSON as a string.
Variant is especially helpful when the JSON sources have unknown, altering, and continuously evolving schema. For instance, clients have shared Endpoint Detection & Response (EDR) use instances, with the necessity to learn and mix logs containing completely different JSON schemas. Equally, for makes use of involving ad-click and utility telemetry, the place the schema is unknown and altering on a regular basis, Variant is well-suited. In each instances, the Variant knowledge kind’s flexibility permits the information to be ingested and performant with out requiring an express schema.
Efficiency Benchmarks
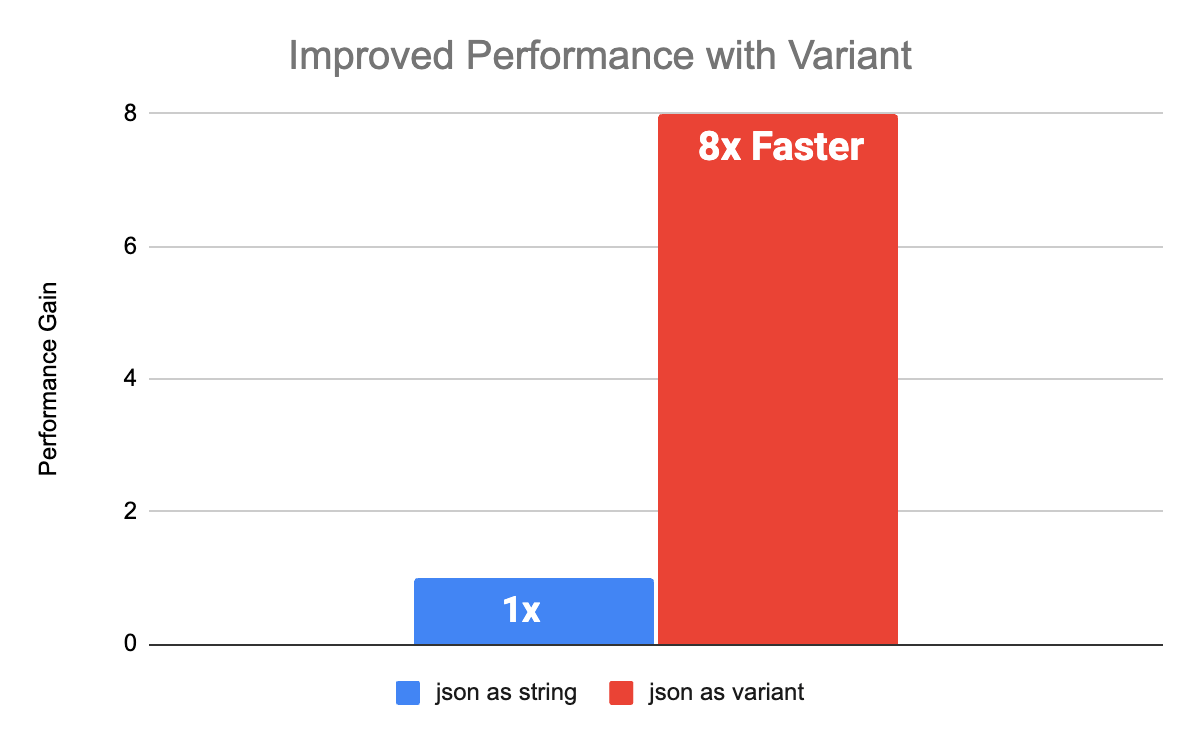
Variant will present improved efficiency over current workloads that preserve JSON as a string. We ran a number of benchmarks with schemas impressed by buyer knowledge to match String vs Variant efficiency. For each nested and flat schemas, efficiency with Variant improved 8x over String columns. The benchmarks have been performed with Databricks Runtime 15.0 with Photon enabled.
How can I exploit Variant?
There are a selection of recent features for supporting Variant varieties, that permit you to examine the schema of a variant, explode a variant column, and convert it to JSON. The PARSE_JSON() operate will likely be generally used for returning a variant worth that represents the JSON string enter.
-- SQL instance
SELECT PARSE_JSON(json_str_col) FROM T
# python instance
df.choose(parse_json(json_str_col))To load Variant knowledge, you may create a desk column with the Variant kind. You possibly can convert any JSON-formatted string to Variant with the PARSE_JSON() operate, and insert right into a Variant column.
CREATE TABLE T (variant_col Variant);
INSERT INTO T (variant_col) SELECT PARSE_JSON(json_str_col) ... ;You need to use CTAS to create a desk with Variant columns. The schema of the desk being created is derived from the question consequence. Due to this fact, the question consequence should have Variant columns within the output schema with the intention to create a desk with Variant columns.
-- Desk T can have a single column: variant_col Variant
CREATE TABLE T AS SELECT PARSE_JSON(json_str) variant_col FROM knowledge
-- Desk T can have 2 columns: id, variant_col Variant
CREATE TABLE T AS SELECT id, PARSE_JSON(json_str) variant_col FROM knowledgeIt’s also possible to use COPY INTO to repeat JSON knowledge right into a desk with a number of Variant columns.
CREATE TABLE T (title Variant)
COPY INTO T FROM ...
FILEFORMAT = JSON
FORMAT_OPTIONS ('singleVariantColumn' = 'title')Path navigation follows intuitive dot-notation syntax.
// Path navigation of a variant column
SELECT variant_col:a.b.c::int, variant_col:arr[1].area::double
FROM TAbsolutely open-sourced, no proprietary knowledge lock-in
Let’s recap:
- The Variant knowledge kind, binary expressions, and binary encoding format are already merged in Apache Spark. The binary encoding format could be reviewed intimately right here.
- The binary encoding format is what permits for sooner entry and navigation of the information when in comparison with Strings. The implementation of the binary encoding format is packaged in an open-source library, in order that it may be utilized in different tasks.
- Help for the Variant knowledge kind can be open-sourced to Delta, and the protocol RFC could be discovered right here. Variant help will likely be included in Spark 4.0 and Delta 4.0.
Additional, we’ve got plans for implementing shredding/sub-columnarization for the Variant kind. Shredding is a way to enhance the efficiency of querying specific paths throughout the Variant knowledge. With shredding, paths could be saved in their very own column, and that may cut back the IO and computation required to question that path. Shredding additionally allows pruning of information to keep away from further pointless work. Shredding will even be out there in Apache Spark and Delta Lake.
Are you attending this yr’s DATA + AI Summit June 10-Thirteenth in San Francisco?
Please attend “Variant Knowledge Kind – Making Semi-Structured Knowledge Quick and Easy“.
Variant will likely be enabled by default in Databricks Runtime 15.3 in Public Preview and DBSQL Preview channel quickly after. Take a look at out your semi-structured knowledge use instances and begin a dialog on the Databricks Neighborhood boards when you have ideas or questions. We’d love to listen to what the neighborhood thinks!
[ad_2]