[ad_1]
Retrieval-augmented era (RAG) has emerged as a outstanding software within the area of pure language processing. This revolutionary strategy entails breaking down massive paperwork into smaller, manageable textual content chunks, usually restricted to round 512 tokens. These bite-sized items of knowledge are then saved in a vector database, with every chunk represented by a singular vector generated utilizing a textual content embedding mannequin. This course of types the inspiration for environment friendly data retrieval and processing.
The ability of RAG turns into evident throughout runtime operations. When a person submits a question, the identical embedding mannequin that processed the saved chunks comes into play. It encodes the question right into a vector illustration, bridging the person’s enter and the saved data. This vector is then used to establish and retrieve probably the most related textual content chunks from the database, guaranteeing that solely probably the most pertinent data is accessed for additional processing.
In October 2023, a major milestone in pure language processing was reached with the discharge of jina-embeddings-v2-base-en, the world’s first open-source embedding mannequin boasting a powerful 8K context size. This groundbreaking improvement sparked appreciable dialogue throughout the AI group concerning the sensible functions and limitations of long-context embedding fashions. The innovation pushed the boundaries of what was doable in textual content illustration, however it additionally raised necessary questions on its effectiveness in real-world situations.
Regardless of the preliminary pleasure, many specialists started to query the practicality of encoding extraordinarily lengthy paperwork right into a single embedding illustration. It turned obvious that for quite a few functions, this strategy won’t be perfect. The AI group acknowledged that many use instances require the retrieval of smaller, extra targeted parts of textual content relatively than processing complete paperwork without delay. This realization led to a deeper exploration of the trade-offs between context size and retrieval effectivity.
Additionally, analysis indicated that dense vector-based retrieval methods typically carry out extra successfully when working with smaller textual content segments. The reasoning behind that is rooted within the idea of semantic compression. When coping with shorter textual content chunks, the embedding vectors are much less more likely to endure from “over-compression” of semantics. Which means that the nuanced meanings and contexts throughout the textual content are higher preserved, resulting in extra correct and related retrieval ends in numerous functions.
The controversy surrounding long-context embedding fashions has led to a rising consensus that embedding smaller chunks of textual content is commonly extra advantageous. This desire stems from two key components: the restricted enter sizes of downstream Giant Language Fashions (LLMs) and the priority that essential contextual data could also be diluted when compressing prolonged passages right into a single vector illustration. These limitations have prompted many to query the sensible worth of coaching fashions with intensive context lengths, corresponding to 8192 tokens.
Nonetheless, dismissing long-context fashions fully can be untimely. Whereas the business might predominantly require embedding fashions with a 512-token context size, there are nonetheless compelling causes to discover and develop fashions with better capability. This text goals to handle this necessary, albeit uncomfortable, query by analyzing the constraints of the standard chunking-embedding pipeline utilized in RAG methods. In doing so, the researchers introduce a singular strategy referred to as “Late Chunking.“
“The implementation of late chunking might be discovered within the Google Colab hyperlink”
The Late Chunking methodology represents a major development in using the wealthy contextual data offered by 8192-length embedding fashions. This revolutionary method provides a more practical solution to embed chunks, probably bridging the hole between the capabilities of long-context fashions and the sensible wants of varied functions. By exploring this strategy, researchers search to display the untapped potential of prolonged context lengths in embedding fashions.
The standard RAG pipeline, which entails chunking, embedding, retrieving, and producing, faces important challenges. One of the crucial urgent points is the destruction of long-distance contextual dependencies. This downside arises when related data is distributed throughout a number of chunks, inflicting textual content segments to lose their context and turn into ineffective when taken in isolation.
A chief instance of this challenge might be noticed within the chunking of a Wikipedia article about Berlin. When cut up into sentence-length chunks, essential references like “its” and “town” turn into disconnected from their antecedent, “Berlin,” which seems solely within the first sentence. This separation makes it troublesome for the embedding mannequin to create correct vector representations that preserve these necessary connections.
The results of this contextual fragmentation turn into obvious when contemplating a question like “What’s the inhabitants of Berlin?” In a RAG system utilizing sentence-length chunks, answering this query turns into problematic. The town title and its inhabitants information might by no means seem collectively in a single chunk, and with out broader doc context, an LLM struggles to resolve anaphoric references corresponding to “it” or “town.”
Whereas numerous heuristics have been developed to handle this challenge, together with resampling with sliding home windows, utilizing a number of context window lengths, and performing multi-pass doc scans, these options stay imperfect. Like all heuristics, their effectiveness is inconsistent and lacks theoretical ensures. This limitation highlights the necessity for extra strong approaches to keep up contextual integrity in RAG methods.

The naive encoding strategy, generally utilized in many RAG methods, employs an easy however probably problematic methodology for processing lengthy texts. This strategy, illustrated on the left aspect of the referenced picture, begins by splitting the textual content into smaller items earlier than any encoding. These items are usually outlined by sentences, paragraphs, or predetermined most size limits.
As soon as the textual content is split into these chunks, an embedding mannequin is utilized repeatedly to every section. This course of generates token-level embeddings for each phrase or subword inside every chunk. To create a single, consultant embedding for your entire chunk, many embedding fashions make the most of a way referred to as imply pooling. This methodology entails calculating the typical of all token-level embeddings throughout the chunk, leading to a single embedding vector.
Whereas this strategy is computationally environment friendly and straightforward to implement, it has important drawbacks. By splitting the textual content earlier than encoding, dangers shedding necessary contextual data that spans throughout chunk boundaries. Additionally, the imply pooling method, whereas easy, might not at all times seize the nuanced relationships between completely different elements of the textual content successfully, probably resulting in the lack of semantic data.
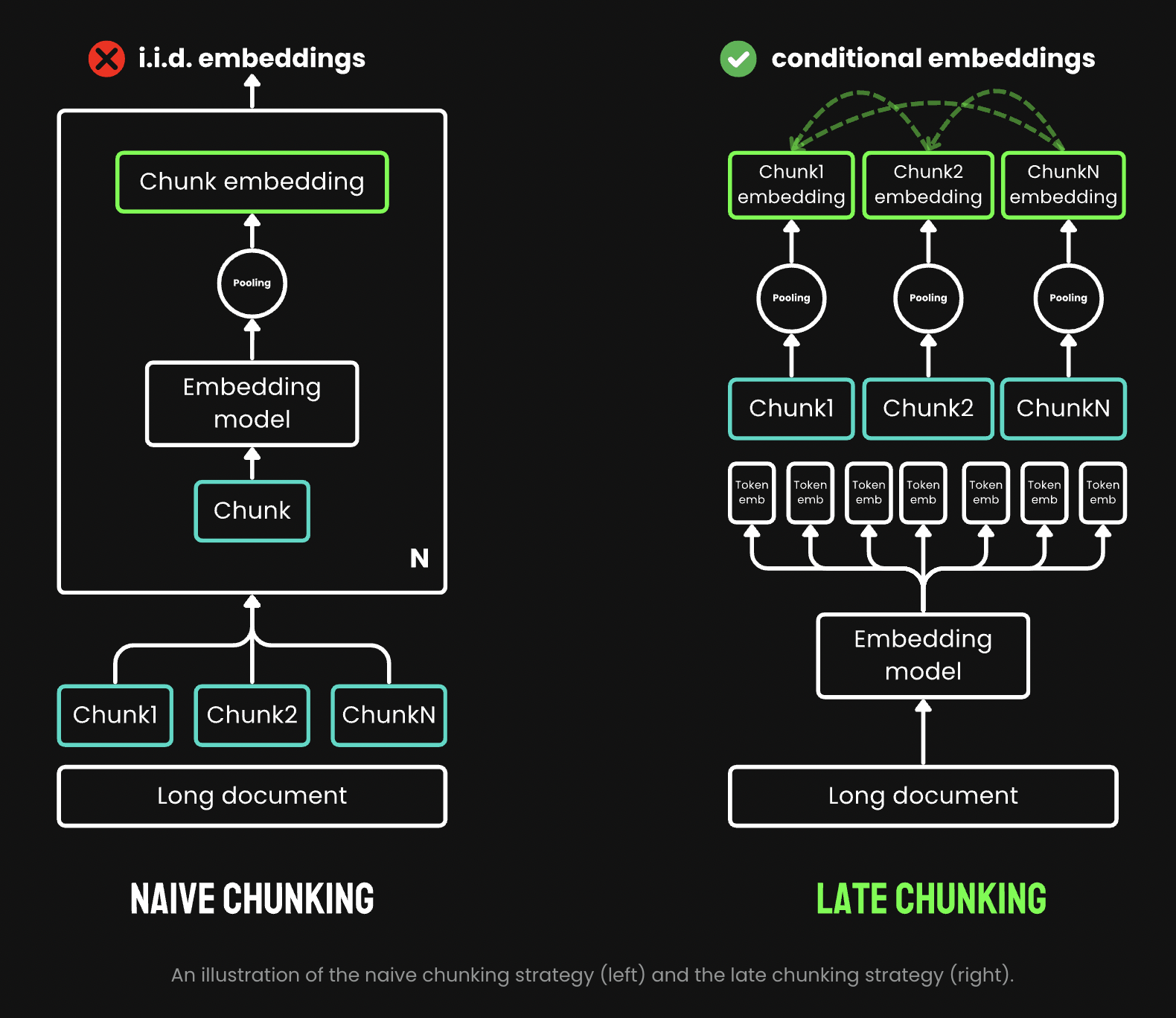
The “Late Chunking” strategy represents a major development in textual content processing for RAG methods. Not like the naive methodology, it applies the transformer layer to your entire textual content first, producing token vectors that seize full contextual data. Imply pooling is then utilized to chunks of those vectors, creating embeddings that think about your entire textual content’s context. This methodology produces chunk embeddings which are “conditioned on” earlier ones, encoding extra contextual data than the impartial embeddings of the naive strategy. Implementing late chunking requires long-context embedding fashions like jina-embeddings-v2-base-en, which may deal with as much as 8192 tokens. Whereas boundary cues are nonetheless crucial, they’re utilized after acquiring token-level embeddings, preserving extra contextual integrity.
To validate the effectiveness of late chunking, researchers carried out assessments utilizing retrieval benchmarks from BeIR. These assessments concerned question units, textual content doc corpora, and QRels information containing details about related paperwork for every question. The outcomes constantly confirmed improved scores for late chunking in comparison with the naive strategy. In some instances, late chunking even outperformed single-embedding encoding of complete paperwork. Additionally, a correlation emerged between doc size and the efficiency enchancment achieved by means of late chunking. As doc size elevated, the effectiveness of the late chunking technique turned extra pronounced, demonstrating its specific worth for processing longer texts in retrieval duties.
This research launched “late chunking,” an revolutionary strategy that makes use of long-context embedding fashions to boost textual content processing in RAG methods. By making use of the transformer layer to complete texts earlier than chunking, this methodology preserves essential contextual data typically misplaced in conventional i.i.d. chunk embedding. Late chunking’s effectiveness will increase with doc size, highlighting the significance of superior fashions like jina-embeddings-v2-base-en that may deal with intensive contexts. This analysis not solely validates the importance of long-context embedding fashions but additionally opens avenues for additional exploration in sustaining contextual integrity in textual content processing and retrieval duties.
Take a look at the Particulars and Colab Pocket book. All credit score for this analysis goes to the researchers of this mission. Additionally, don’t neglect to comply with us on Twitter and be part of our Telegram Channel and LinkedIn Group. If you happen to like our work, you’ll love our publication..
Don’t Neglect to affix our 50k+ ML SubReddit
Here’s a extremely beneficial webinar from our sponsor: ‘Constructing Performant AI Purposes with NVIDIA NIMs and Haystack’
Asjad is an intern marketing consultant at Marktechpost. He’s persuing B.Tech in mechanical engineering on the Indian Institute of Expertise, Kharagpur. Asjad is a Machine studying and deep studying fanatic who’s at all times researching the functions of machine studying in healthcare.

[ad_2]