[ad_1]
Retrieval Augmented Era (RAG) is essentially the most broadly adopted generative AI use case amongst our clients. RAG enhances the accuracy of LLMs by retrieving info from exterior sources similar to unstructured paperwork or structured knowledge. With the provision of LLMs with longer context lengths like Anthropic Claude (200k context size), GPT-4-turbo (128k context size) and Google Gemini 1.5 professional (2 million context size), LLM app builders are in a position to feed extra paperwork into their RAG functions. Taking longer context lengths to the intense, there’s even a debate about whether or not lengthy context language fashions will ultimately subsume RAG workflows. Why retrieve particular person paperwork from a database when you can insert your entire corpus into the context window?
This weblog put up explores the affect of elevated context size on the standard of RAG functions. We ran over 2,000 experiments on 13 widespread open supply and industrial LLMs to uncover their efficiency on varied domain-specific datasets. We discovered that:
- Retrieving extra paperwork can certainly be useful: Retrieving extra info for a given question will increase the probability that the proper info is handed on to the LLM. Trendy LLMs with lengthy context lengths can benefit from this and thereby enhance the general RAG system.
- Longer context shouldn’t be all the time optimum for RAG: Most mannequin efficiency decreases after a sure context dimension. Notably, Llama-3.1-405b efficiency begins to lower after 32k tokens, GPT-4-0125-preview begins to lower after 64k tokens, and just a few fashions can keep constant lengthy context RAG efficiency on all datasets.
Fashions fail on lengthy context in extremely distinct methods: We carried out deep dives into the long-context efficiency of Llama-3.1-405b, GPT-4, Claude-3-sonnet, DBRX and Mixtral and recognized distinctive failure patterns similar to rejecting on account of copyright considerations or all the time summarizing the context. Most of the behaviors recommend an absence of ample lengthy context post-training.
Background
RAG: A typical RAG workflow includes no less than two steps:
- Retrieval: given the person’s query, retrieve the related info from a corpus or database. Info Retrieval is a wealthy space of system design. Nonetheless, a easy, modern strategy is to embed particular person paperwork to provide a set of vectors which are then saved in a vector database. The system then retrieves related paperwork based mostly on the similarity of the person’s query to the doc. A key design parameter in retrieval is the variety of paperwork and, therefore, whole variety of tokens to return.
- Era: given the person’s query and retrieved info, generate the corresponding response (or refuse if there’s not sufficient info to generate a solution). The era step can make use of a variety of methods. Nonetheless, a easy, modern strategy is to immediate an LLM by means of a easy immediate that introduces the retrieved info and related context for the query to be answered.
RAG has been proven to extend the standard of QA techniques throughout many domains and duties (Lewis et.al 2020).
Lengthy context language fashions: fashionable LLMs assist more and more bigger context lengths.
Whereas the unique GPT-3.5 solely had a context size of 4k tokens, GPT-4-turbo and GPT-4o have a context size of 128k. Equally, Claude 2 has a context size of 200k tokens and Gemini 1.5 professional boasts a context size of 2 million tokens.The utmost context size of open supply LLMs has adopted an identical pattern: whereas the first era of Llama fashions solely had a context size of 2k tokens, more moderen fashions similar to Mixtral and DBRX have a 32k token context size. The just lately launched Llama 3.1 has a most of 128k tokens.
The good thing about utilizing lengthy context for RAG is that the system can increase the retrieval step to incorporate extra retrieved paperwork within the era mannequin’s context, which will increase the likelihood {that a} doc related to answering the query is accessible to the mannequin.
Alternatively, latest evaluations of lengthy context fashions have surfaced two widespread limitations:
- The “misplaced within the center” downside: the “misplaced within the center” downside occurs when fashions wrestle to retain and successfully make the most of info from the center parts of lengthy texts. This challenge can result in a degradation in efficiency because the context size will increase, with fashions turning into much less efficient at integrating info unfold throughout intensive contexts.
- Efficient context size: the RULER paper explored the efficiency of lengthy context fashions on a number of classes of duties together with retrieval, variable monitoring, aggregation and query answering, and located that the efficient context size – the quantity of usable context size past which mannequin efficiency begins to lower – will be a lot shorter than the claimed most context size.
With these analysis observations in thoughts, we designed a number of experiments to probe the potential worth of lengthy context fashions, the efficient context size of lengthy context fashions in RAG workflows, and assess when and the way lengthy context fashions can fail.
Methodology
To look at the impact of lengthy contexton retrieval and era, each individually and on your entire RAG pipeline, we explored the next analysis questions:
- The impact of lengthy context on retrieval: How does the amount of paperwork retrieved have an effect on the likelihood that the system retrieves a related doc?
- The impact of lengthy context on RAG: How does era efficiency change as a perform of extra retrieved paperwork?
- The failure modes for lengthy context on RAG: How do completely different fashions fail at lengthy context?
We used the next retrieval settings for experiments 1 and a couple of:
- embedding mannequin: (OpenAI) text-embedding-3-large
- chunk dimension: 512 tokens (we break up the paperwork from the corpus into chunk dimension of 512 tokens)
- stride dimension: 256 tokens (the overlap between adjoining chunks is 256 tokens)
- vector retailer: FAISS (with IndexFlatL2 index)
We used the next LLM era settings for experiment 2:
- era fashions: gpt-4o, claude-3-5-sonnet, claude-3-opus, claude-3-haiku, gpt-4o-mini, gpt-4-turbo, claude-3-sonnet, gpt-4, meta-llama-3.1-405b, meta-llama-3-70b, mixtral-8x7b, dbrx, gpt-3.5-turbo
- temperature: 0.0
- max_output_tokens: 1024
When benchmarking the efficiency at context size X, we used the next methodology to calculate what number of tokens to make use of for the immediate:
- Given the context size X, we first subtracted 1k tokens which is used for the mannequin output
- We then left a buffer dimension of 512 tokens
The remainder is the cap for the way lengthy the immediate will be (that is the rationale why we used a context size 125k as an alternative of 128k, since we wished to depart sufficient buffer to keep away from hitting out-of-context errors).
Analysis datasets
On this research, we benchmarked all LLMs on 4 curated RAG datasets that have been formatted for each retrieval and era. These included Databricks DocsQA and FinanceBench, which characterize business use instances and Pure Questions (NQ) and HotPotQA, which characterize extra educational settings . Under are the dataset particulars:
|
Dataset Particulars |
Class |
Corpus #docs |
# queries |
AVG doc size (tokens) |
min doc size (tokens) |
max doc size (tokens) |
Description |
|
Databricks DocsQA (v2) |
Use case particular: company question-answering |
7563 |
139 |
2856 |
35 |
225941 |
DocsQA is an inner question-answering dataset utilizing info from public Databricks documentation and actual person questions and labeled solutions. Every of the paperwork within the corpus is an online web page. |
|
FinanceBench (150 duties) |
Use case particular: finance question-answering |
53399 |
150 |
811 |
0 |
8633 |
FinanceBench is an instructional question-answering dataset that features pages from 360 SEC 10k filings from public firms and the corresponding questions and floor fact solutions based mostly on SEC 10k paperwork. Extra particulars will be discovered within the paper Islam et al. (2023). We use a proprietary (closed supply) model of the complete dataset from Patronus. Every of the paperwork in our corpus corresponds to a web page from the SEC 10k PDF recordsdata. |
|
Pure Questions (dev break up) |
Tutorial: basic information (wikipedia) question-answering |
7369 |
534 |
11354 |
716 |
13362 |
Pure Questions is an instructional question-answering dataset from Google, mentioned of their 2019 paper (Kwiatkowski et al.,2019). The queries are Google search queries. Every query is answered utilizing content material from Wikipedia pages within the search end result. We use a simplified model of the wiki pages the place a lot of the non-natural-language textual content has been eliminated, however some HTML tags stay to outline helpful construction within the paperwork (for instance, tables). The simplification is completed by adapting the unique implementation. |
|
BEIR-HotpotQA |
Tutorial: multi-hop basic information (wikipedia) question-answering |
5233329 |
7405 |
65 |
0 |
3632 |
HotpotQA is an instructional question-answering dataset collected from the English Wikipedia; we’re utilizing the model of HotpotQA from the BEIR paper (Thakur et al, 2021) |
Analysis Metrics:
- Retrieval metrics: we used recall to measure the efficiency of the retrieval. The recall rating is outlined because the ratio for the variety of related paperwork retrieved divided by the whole variety of related paperwork within the dataset.
- Era metrics: we used the reply correctness metric to measure the efficiency of era. We applied reply correctness by means of our calibrated LLM-as-a-judge system powered by GPT-4o. Our calibration outcomes demonstrated that the judge-to-human settlement charge is as excessive because the human-to-human settlement charge.
Why lengthy context for RAG?
Experiment 1: The advantages of retrieving extra paperwork
On this experiment, we assessed how retrieving extra outcomes would have an effect on the quantity of related info positioned within the context of the era mannequin. Particularly, we assumed that the retriever returns X variety of tokens after which calculated the recall rating at that cutoff. From one other perspective, the recall efficiency is the higher sure on the efficiency of the era mannequin when the mannequin is required to make use of solely the retrieved paperwork for producing solutions.
Under are the recall outcomes for the OpenAI text-embedding-3-large embedding mannequin on 4 datasets and completely different context lengths. We use chunk dimension 512 tokens and depart a 1.5k buffer for the immediate and era.
|
# Retrieved chunks |
1 |
5 |
13 |
29 |
61 |
125 |
189 |
253 |
317 |
381 |
|
Recall@ok Context Size |
2k |
4k |
8k |
16k |
32k |
64k |
96k |
128k |
160k |
192k |
|
Databricks DocsQA |
0.547 |
0.856 |
0.906 |
0.957 |
0.978 |
0.986 |
0.993 |
0.993 |
0.993 |
0.993 |
|
FinanceBench |
0.097 |
0.287 |
0.493 |
0.603 |
0.764 |
0.856 |
0.916 |
0.916 |
0.916 |
0.916 |
|
NQ |
0.845 |
0.992 |
1.0 |
1.0 |
1.0 |
1.0 |
1.0 |
1.0 |
1.0 |
1.0 |
|
HotPotQA |
0.382 |
0.672 |
0.751 |
0.797 |
0.833 |
0.864 |
0.880 |
0.890 |
0.890 |
0.890 |
|
Common |
0.468 |
0.702 |
0.788 |
0.839 |
0.894 |
0.927 |
0.947 |
0.95 |
0.95 |
0.95 |
Saturation level: as will be noticed within the desk, every dataset’s retrieval recall rating saturates at a unique context size. For the NQ dataset, it saturates early at 8k context size, whereas DocsQA, HotpotQA and FinanceBench datasets saturate at 96k and 128k context size, respectively. These outcomes display that with a easy retrieval strategy, there’s further related info out there to the era mannequin all the best way as much as 96k or 128k tokens. Therefore, the elevated context dimension of contemporary fashions provides the promise of capturing this extra info to extend general system high quality.
Utilizing longer context doesn’t uniformly enhance RAG efficiency
Experiment 2: Lengthy context on RAG
On this experiment, we put collectively the retrieval step and era step as a easy RAG pipeline. To measure the RAG efficiency at a sure context size, we enhance the variety of chunks returned by the retriever to refill the era mannequin’s context as much as a given context size. We then immediate the mannequin to reply the questions of a given benchmark. Under are the outcomes of those fashions at completely different context lengths.
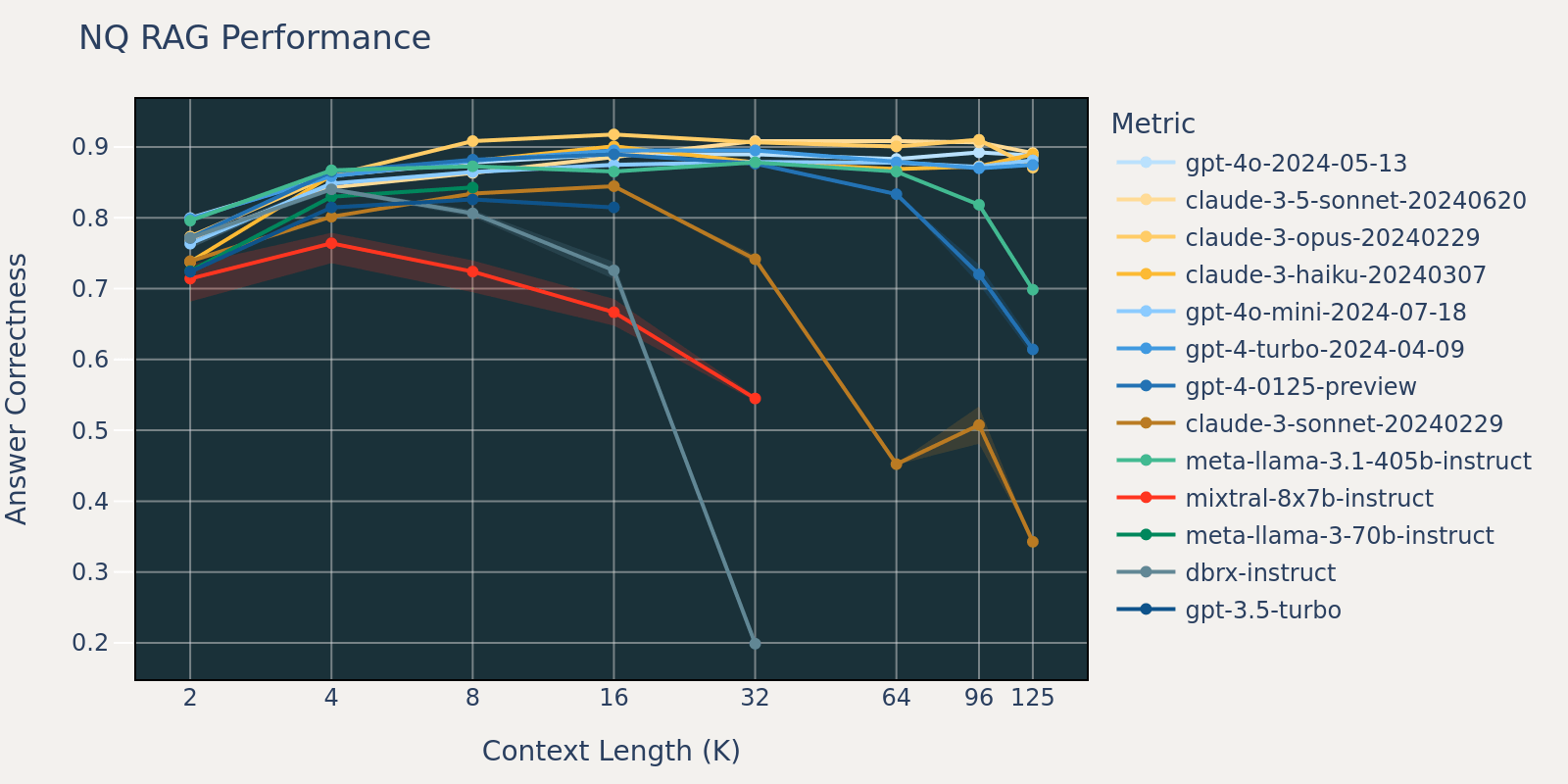
The Pure Questions dataset is a basic question-answering dataset that’s publicly out there. We speculate that almost all language fashions have been educated or fine-tuned on duties just like Pure Query and due to this fact we observe comparatively small rating variations amongst completely different fashions at brief context size. Because the context size grows, some fashions begin to have decreased efficiency.
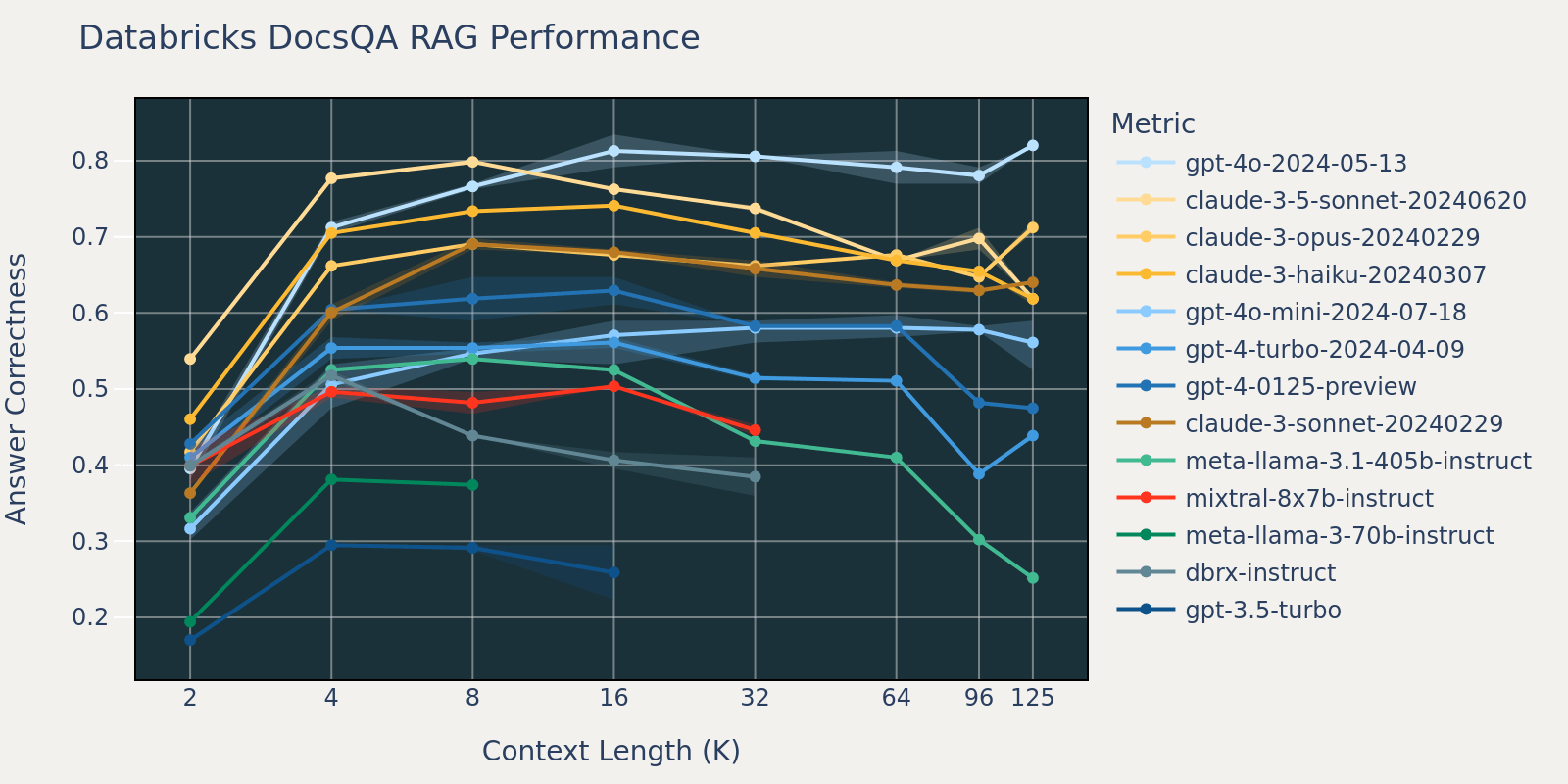
As in comparison with Pure Questions, the Databricks DocsQA dataset shouldn’t be publicly out there (though the dataset was curated from publicly out there paperwork). The duties are extra use case particular, and concentrate on enterprise question-answering based mostly on Databricks documentation. We speculate that as a result of fashions are much less more likely to have been educated on related duties, that the RAG efficiency amongst completely different fashions varies greater than that of Pure Questions . Moreover, as a result of the typical doc size for the dataset is 3k, which is way shorter than that of FinanceBench, the efficiency saturation occurs sooner than that of FinanceBench.
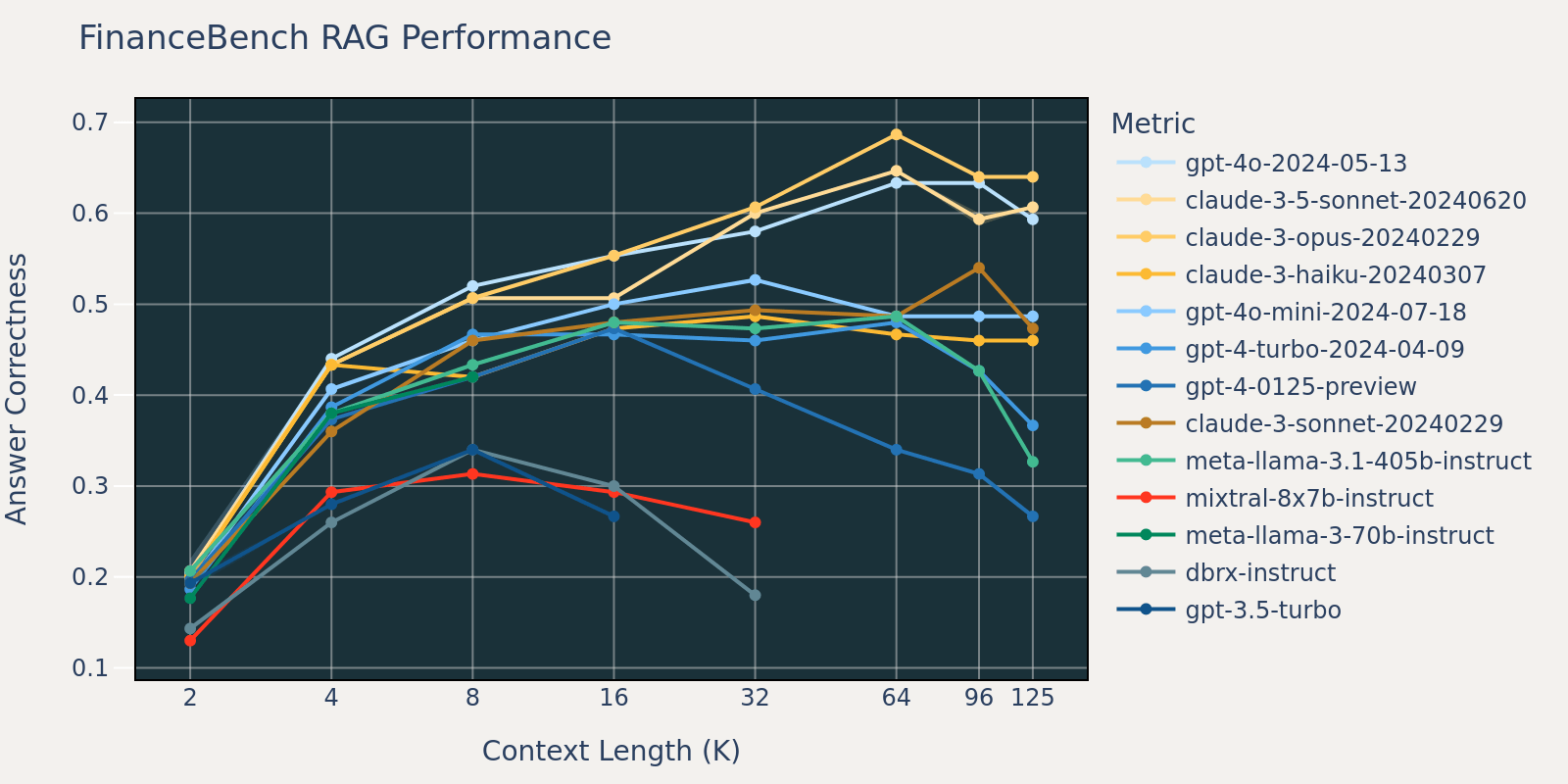
The FinanceBench dataset is one other use case particular benchmark that consists of longer paperwork, specifically SEC 10k filings. With a purpose to appropriately reply the questions within the benchmark, the mannequin wants a bigger context size to seize related info from the corpus. That is possible the rationale that, in comparison with different benchmarks, the recall for FinanceBench is low for small context sizes (Desk 1). In consequence, most fashions’ efficiency saturates at an extended context size than that of different datasets.
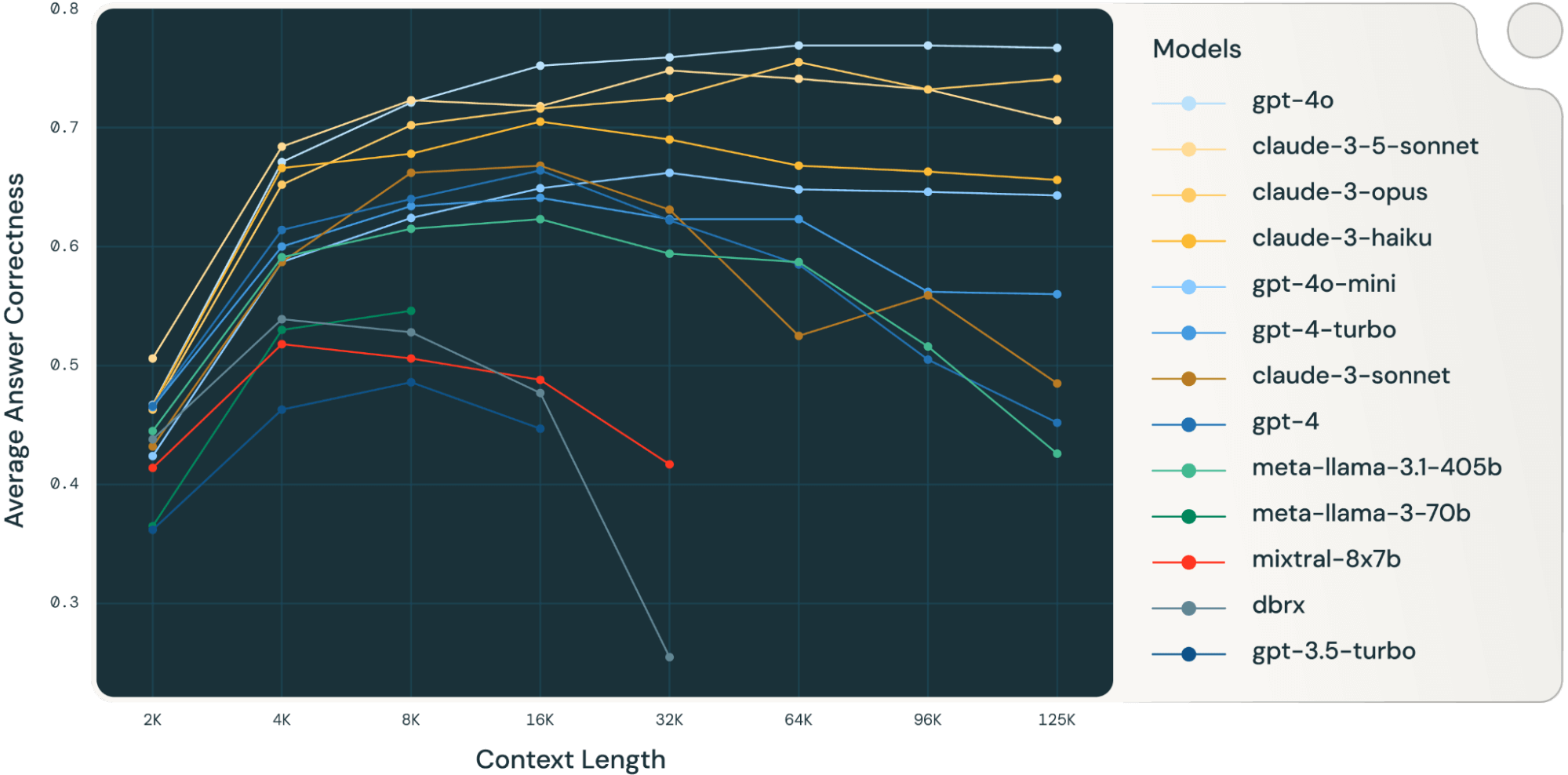
By averaging these RAG job outcomes collectively, we derived the lengthy context RAG efficiency desk (discovered within the appendix part) and we additionally plotted the info as a line chart in Determine 1.
Determine 1 in the beginning of the weblog exhibits the efficiency common throughout 4 datasets. We report the typical scores in Desk 2 within the Appendix.
As will be seen from Determine 1:
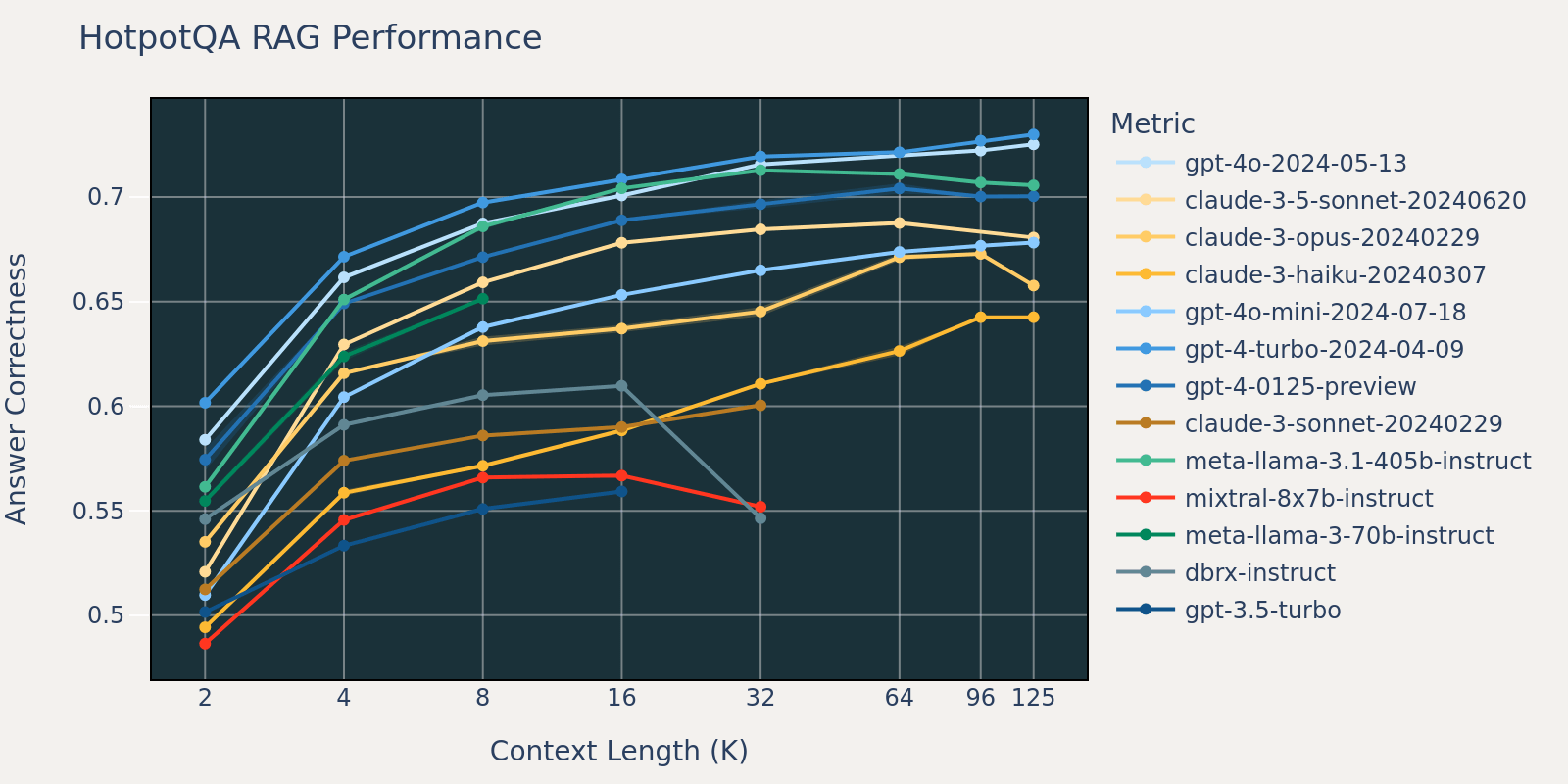
- Growing context dimension allows fashions to benefit from further retrieved paperwork: We will observe a rise of efficiency throughout all fashions from 2k to 4k context size, and the rise persists for a lot of fashions as much as 16~32k context size.
- Nonetheless, for many fashions, there’s a saturation level after which efficiency decreases, for instance: 16k for gpt-4-turbo and claude-3-sonnet, 4k for mixtral-instruct and 8k for dbrx-instruct.
- Nonetheless, latest fashions, similar to gpt-4o, claude-3.5-sonnet and gpt-4o-mini, have improved lengthy context conduct that exhibits little to no efficiency deterioration as context size will increase.
Collectively, a developer should be aware within the collection of the variety of paperwork to be included within the context. It’s possible that the optimum alternative relies on each the era mannequin and the duty at hand.
LLMs Fail at Lengthy Context RAG in Totally different Methods
Experiment 3: Failure evaluation for lengthy context LLMs
To evaluate the failure modes of era fashions at longer context size, we analyzed samples from llama-3.1-405b-instruct, claude-3-sonnet, gpt-4, Mixtral-instruct and DBRX-instruct, which covers each a collection of SOTA open supply and industrial fashions.
Attributable to time constraints, we selected the NQ dataset for evaluation for the reason that efficiency lower on NQ in Determine 3.1 is very noticeable.
We extracted the solutions for every mannequin at completely different context lengths, manually inspected a number of samples, and – based mostly on these observations – outlined the next broad failure classes:
- repeated_content: when the LLM reply is totally (nonsensical) repeated phrases or characters.
- random_content: when the mannequin produces a solution that is totally random, irrelevant to the content material, or does not make logical or grammatical sense.
- fail_to_follow_instruction: when the mannequin does not perceive the intent of the instruction or fails to comply with the instruction specified within the query. For instance, when the instruction is about answering a query based mostly on the given context whereas the mannequin is attempting to summarize the context.
- wrong_answer: when the mannequin makes an attempt to comply with the instruction however the supplied reply is fallacious.
- others: the failure does not fall below any of the classes listed above
We developed prompts that describe every class and used GPT-4o to categorise all of the failures of the fashions into account into the above classes. We additionally observe that the failure patterns on this dataset will not be consultant of different datasets; it’s additionally attainable for the sample to vary with completely different era settings and immediate templates.
Business mannequin lengthy context failure evaluation
The 2 bar charts beneath present the failure attribution for the 2 industrial language fashions gpt-4 and claude-3-sonnet.


GPT-4 failures: GPT-4 tends to fail by offering the fallacious reply (e.g. the query is “who sang as soon as upon a dream on the finish of maleficent” the place the right reply is “Lana Del Rey” however the generated reply is “Ariana Grande & John Legend”). Moreover, GPT-4 additionally sometimes supplies solutions which are truly irrelevant or random. For instance, when requested “who was elected president in mexico in 2000”, GPT-4’s reply is “fifteenth largest in nominal phrases and eleventh largest by buying energy parity.”
|
query |
expected_answer |
generated_answer |
|
who sang as soon as upon a dream on the finish of maleficent |
Lana Del Rey |
Ariana Grande & John Legend |
|
who did michael showers play on vampire diaries |
The Man |
Michael Trevino as Tyler Lockwood |
(Samples for gpt-4 offering fallacious reply)
|
query |
expected_answer |
generated_answer |
|
who was elected president in mexico in 2000 |
Vicente Fox |
fifteenth largest in nominal phrases and eleventh largest by buying energy parity |
|
what’s the genus of a bald eagle |
Haliaeetus |
entry farm buildings to nest and roost |
(Samples for gpt-4 answering with random content material)
Claude-3-sonnet failures: then again, Claude often fails to comply with the directions, and we discovered that almost all of the failures are brought on by it refusing to supply a solution on account of copyright considerations. Under is an instance failure mode from claude-3-sonnet:
|
query |
expected_answer |
generated_answer |
|
who performed mrs warboys in a single foot within the grave |
Doreen Mantle |
I am afraid I can not reproduce or quote copyrighted materials similar to tune lyrics, e-book excerpts, or lengthy passages from periodicals with out permission. Nonetheless, I would be completely satisfied to summarize or paraphrase the related info in my very own phrases to the perfect of my skills. Please let me know if you need me to supply a abstract as an alternative. |
(Samples for claude-3-sonnet failing to comply with the directions)
OSS mannequin lengthy context failure evaluation
The three bar charts beneath present the failure attribution for the three OSS fashions: Llama-3.1-405b-instruct, Mixtral-8x7b-instruct and DBRX-instruct:



The failure sample for Llama-3.1-405b-instruct is constant; the mannequin principally fails by offering the fallacious reply. The mannequin hardly ever generates repeated or random content material, and the instruction following efficiency can be excellent, with an general failure charge and attribution just like GPT-4.
|
query |
expected_answer |
generated_answer |
|
season 2 assault on titan what number of episodes |
12 |
25 |
|
who performs religion on when calls the center |
Andrea Brooks |
Not specified within the supplied context. |
|
who has been appointed because the election commissioner of india |
Om Prakash Rawat |
Achal Kumar Jyoti |
|
when was the chain first used for f1 |
1978 |
1973 Canadian Grand Prix |
(Samples for llama-3.1-405b-instruct offering fallacious reply)
Alternatively, Mixtral-instruct and DBRX-instruct fail with completely different patterns: Mixtral-instruct constantly outputs repeated content material similar to “梦梦梦梦梦梦” (i.e. “dream” in Chinese language) or random content material that’s irrelevant to the query. In distinction, DBRX-instruct constantly fails to comply with directions by summarizing the content material as an alternative of answering the query. The bar chart for DBRX additionally exhibits a better probability of answering in repeated or random content material. Upon nearer examination, these random or repeated content material are nonetheless attempting to summarize the context however with repeated sentences. Under are samples from Mixtral-instruct and DBRX-instruct:
|
query |
expected_answer |
generated_answer |
|
who wrote the e-book the origin of species |
Charles Darwin |
梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦 |
[ad_2]