[ad_1]
The sphere of analysis focuses on enhancing giant multimodal fashions (LMMs) to course of and perceive extraordinarily lengthy video sequences. Video sequences supply beneficial temporal data, however present LMMs need assistance to grasp exceptionally lengthy movies. This difficulty stems from the sheer quantity of visible tokens generated by the imaginative and prescient encoders, making it difficult for current fashions to deal with them effectively.
One important drawback this analysis addresses is the necessity for present LMMs to successfully course of and perceive lengthy movies. This problem arises because of the extreme variety of visible tokens produced by imaginative and prescient encoders. As an illustration, fashions like LLaVA-1.6 generate between 576 and 2880 visible tokens for a single picture, which escalates considerably with extra frames. This creates a bottleneck in processing and understanding lengthy video sequences, necessitating revolutionary options.
Current strategies to deal with this drawback embrace visible resamplers to cut back the variety of visible tokens and heuristic methods to prune or merge visible options. Regardless of these efforts, most LMMs nonetheless need assistance to course of many frames successfully. Present strategies just like the visible resampler utilized by fashions similar to MPLUG-Owl-video and MovieChat try to compress the visible options however should catch up when coping with in depth video knowledge.
Researchers from the LMMs-Lab Group, NTU, and SUTD in Singapore have launched an revolutionary strategy referred to as Lengthy Context Switch to deal with this problem. This strategy extends the context size of the language mannequin spine, enabling it to course of a considerably bigger variety of visible tokens. This technique is exclusive as a result of it doesn’t require extra video coaching. As a substitute, it leverages the prolonged context size of the language mannequin, permitting LMMs to understand orders of magnitude extra visible tokens. This analysis was performed by the LMMs-Lab crew.
The proposed mannequin, Lengthy Video Assistant (LongVA), extends the context size of the language mannequin by coaching it on longer textual content knowledge. This context-extended language mannequin is then aligned with visible inputs, permitting the mannequin to course of lengthy movies successfully with out extra complexity. The UniRes encoding scheme, which unifies the illustration of photographs and movies, performs a vital position on this course of. LongVA can deal with movies as prolonged photographs throughout inference, considerably enhancing its means to course of lengthy video sequences.
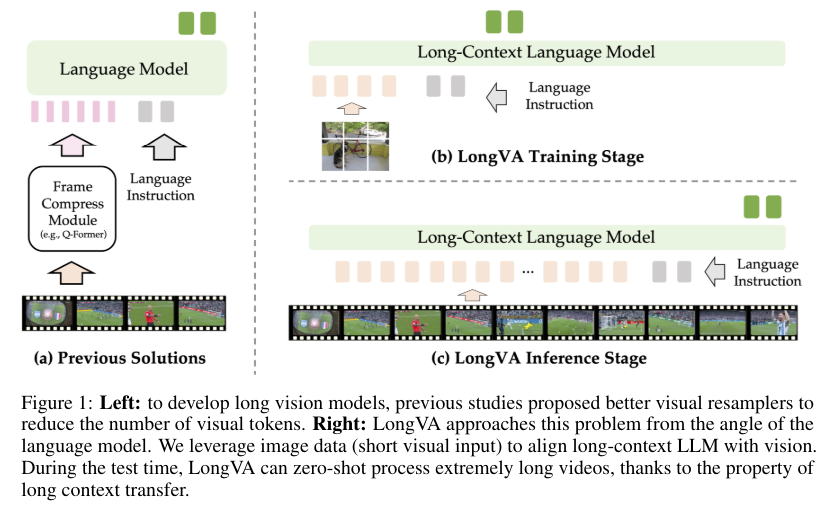
LongVA’s efficiency on the Video-MME dataset demonstrates its functionality to deal with lengthy movies. It will probably course of as much as 2000 frames or over 200,000 visible tokens, setting a brand new benchmark on this space. The Visible Needle-In-A-Haystack (V-NIAH) benchmark was developed to measure LMMs’ means to find and retrieve visible data over lengthy contexts. LongVA confirmed superior efficiency in these evaluations, retrieving visible data precisely from as much as 3000 frames.
Experiments confirmed that LongVA might successfully course of and perceive lengthy movies, reaching state-of-the-art efficiency amongst 7B-scale fashions. The mannequin was educated on a context size of 224K tokens, equal to 1555 frames, and it generalizes nicely past that, sustaining efficiency inside 3000 frames. This demonstrates the effectiveness of the lengthy context switch phenomenon, the place the prolonged context of the language mannequin enhances the visible processing capabilities of the LMMs.
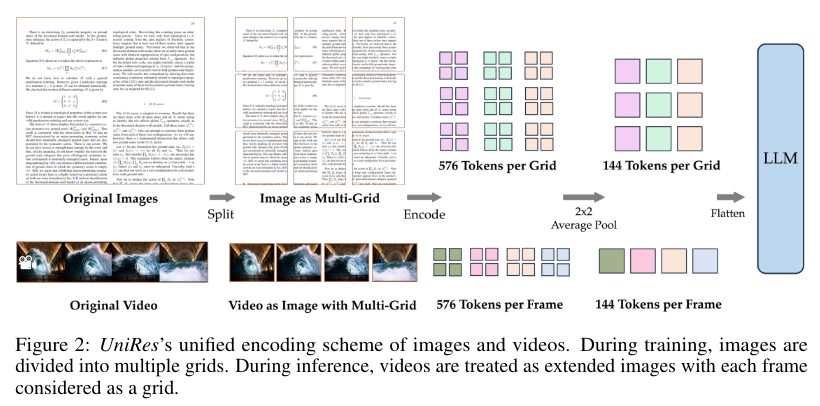
The researchers performed detailed experiments to validate their strategy. They used Qwen2-7B-Instruct because the spine language mannequin and carried out continued pretraining with a context size of 224K over 900 million tokens. The coaching framework was designed to be reminiscence environment friendly and preserve excessive GPU occupancy. The lengthy context coaching was accomplished in simply two days utilizing eight A100 GPUs, showcasing the feasibility of this strategy inside tutorial budgets.

In conclusion, this analysis addresses the vital drawback of processing and understanding lengthy video sequences in giant multimodal fashions. By extending the context size of the language mannequin and aligning it with visible inputs, the researchers considerably improved the LMMs’ functionality to deal with lengthy movies. The proposed LongVA mannequin demonstrates substantial efficiency enhancements, processing as much as 2000 frames or over 200,000 visible tokens and setting a brand new normal for LMMs on this area. This work highlights the potential of lengthy context switch to reinforce the capabilities of LMMs for lengthy video processing.
Take a look at the Paper, Challenge, and Demo. All credit score for this analysis goes to the researchers of this challenge. Additionally, don’t neglect to observe us on Twitter.
Be a part of our Telegram Channel and LinkedIn Group.
For those who like our work, you’ll love our e-newsletter..
Don’t Neglect to affix our 45k+ ML SubReddit
🚀 Create, edit, and increase tabular knowledge with the primary compound AI system, Gretel Navigator, now typically accessible! [Advertisement]
Sana Hassan, a consulting intern at Marktechpost and dual-degree pupil at IIT Madras, is enthusiastic about making use of know-how and AI to deal with real-world challenges. With a eager curiosity in fixing sensible issues, he brings a contemporary perspective to the intersection of AI and real-life options.
[ad_2]