[ad_1]

Picture by Creator
LSTMs had been initially launched within the early Nineties by authors Sepp Hochreiter and Jurgen Schmidhuber. The unique mannequin was extraordinarily compute-expensive and it was within the mid-2010s when RNNs and LSTMs gained consideration. With extra knowledge and higher GPUs obtainable, LSTM networks grew to become the usual methodology for language modeling and so they grew to become the spine for the primary massive language mannequin. That was the case till the discharge of Consideration-Primarily based Transformer Structure in 2017. LSTMs had been regularly outdone by the Transformer structure which is now the usual for all current Giant Language Fashions together with ChatGPT, Mistral, and Llama.
Nevertheless, the current launch of the xLSTM paper by the unique LSTM creator Sepp Hochreiter has triggered a significant stir within the analysis neighborhood. The outcomes present comparative pre-training outcomes to the most recent LLMs and it has raised a query if LSTMs can as soon as once more take over Pure Language Processing.
Excessive-Stage Structure Overview
The unique LSTM community had some main limitations that restricted its usability for bigger contexts and deeper fashions. Specifically:
- LSTMs had been sequential fashions that made it onerous to parallelize coaching and inference.
- They’d restricted storage capabilities and all data needed to be compressed right into a single cell state.
The current xLSTM community introduces new sLSTM and mLSTM blocks to handle each these shortcomings. Allow us to take a birds-eye view of the mannequin structure and see the method utilized by the authors.
Quick Evaluate of Unique LSTM
The LSTM community used a hidden state and cell state to counter the vanishing gradient drawback within the vanilla RNN networks. In addition they added the neglect, enter and output sigmoid gates to manage the movement of knowledge. The equations are as follows:
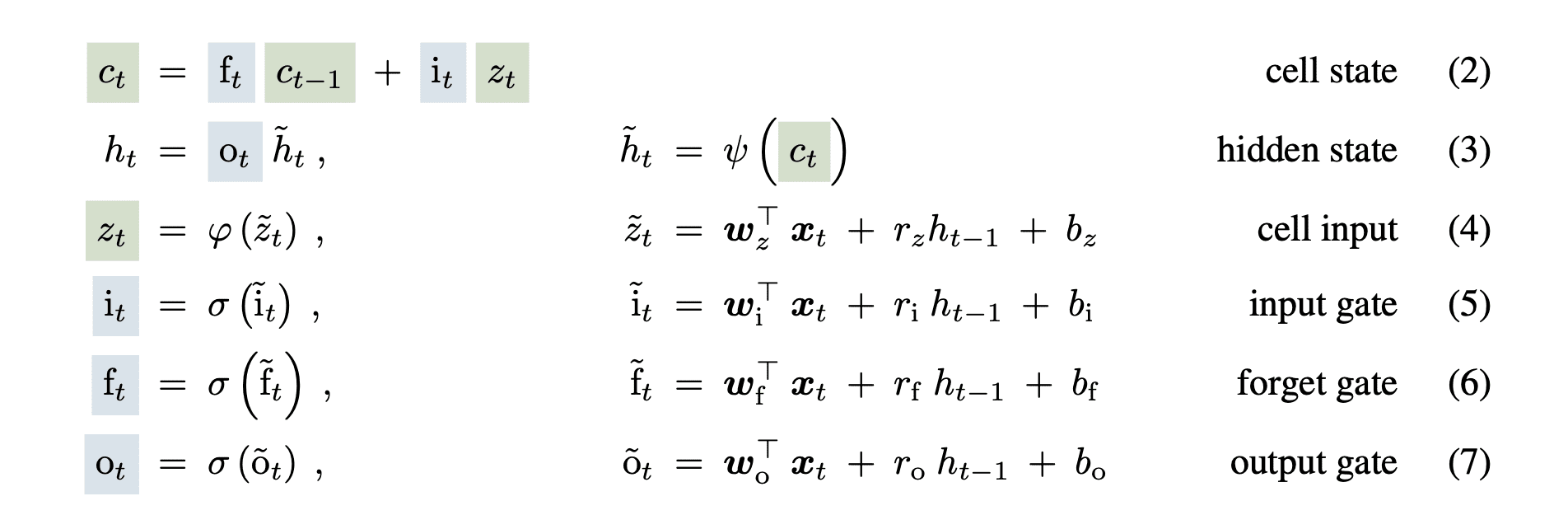
Picture from Paper
The cell state (ct) handed by way of the LSTM cell with minor linear transformations that helped protect the gradient throughout massive enter sequences.
The xLSTM mannequin modifies these equations within the new blocks to treatment the recognized limitations of the mannequin.
sLSTM Block
The block modifies the sigmoid gates and makes use of the exponential perform for the enter and neglect gate. As quoted by the authors, this will enhance the storage points in LSTM and nonetheless permit a number of reminiscence cells permitting reminiscence mixing inside every head however not throughout head. The modified sLSTM block equation is as follows:
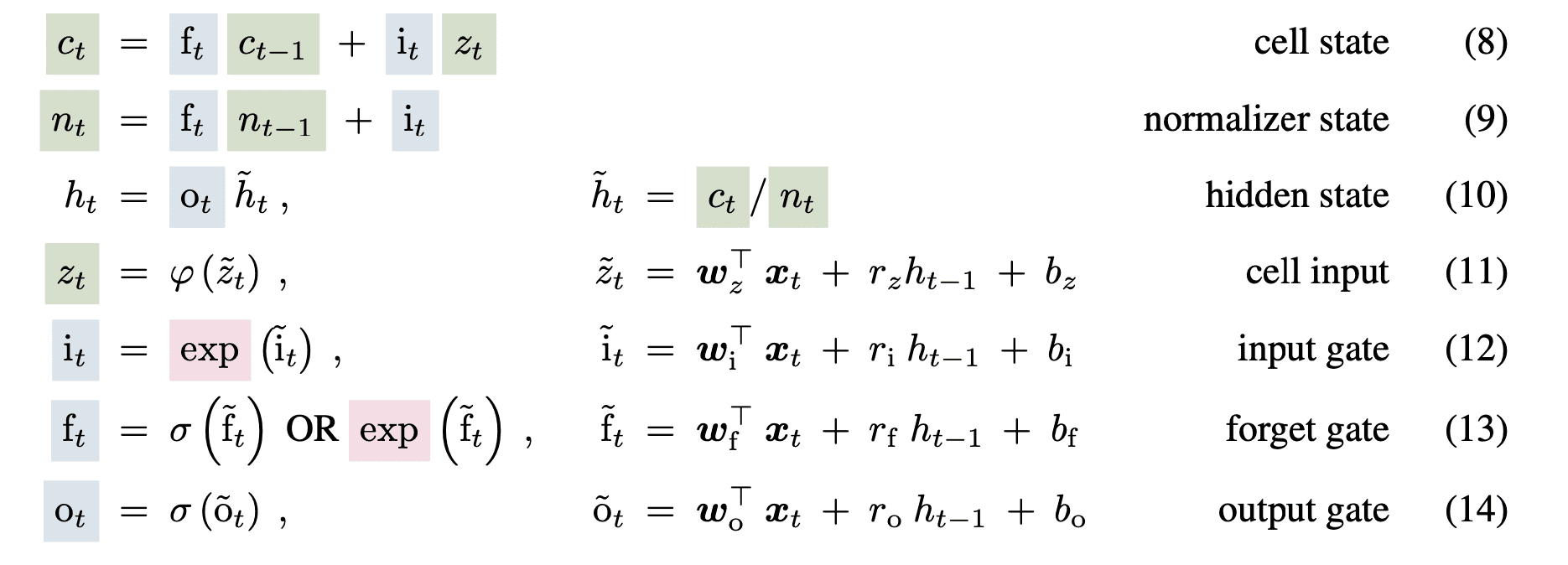
Picture from Paper
Furthermore, because the exponential perform could cause massive values, the gate values are normalized and stabilized utilizing log features.
mLSTM Block
To counter the parallelizability and storage points within the LSTM community, the xLSTM modifies the cell state from a 1-dimensional vector to a 2-dimensional sq. matrix. They retailer a decomposed model as key and worth vectors and use the identical exponential gating because the sLSTM block. The equations are as follows:
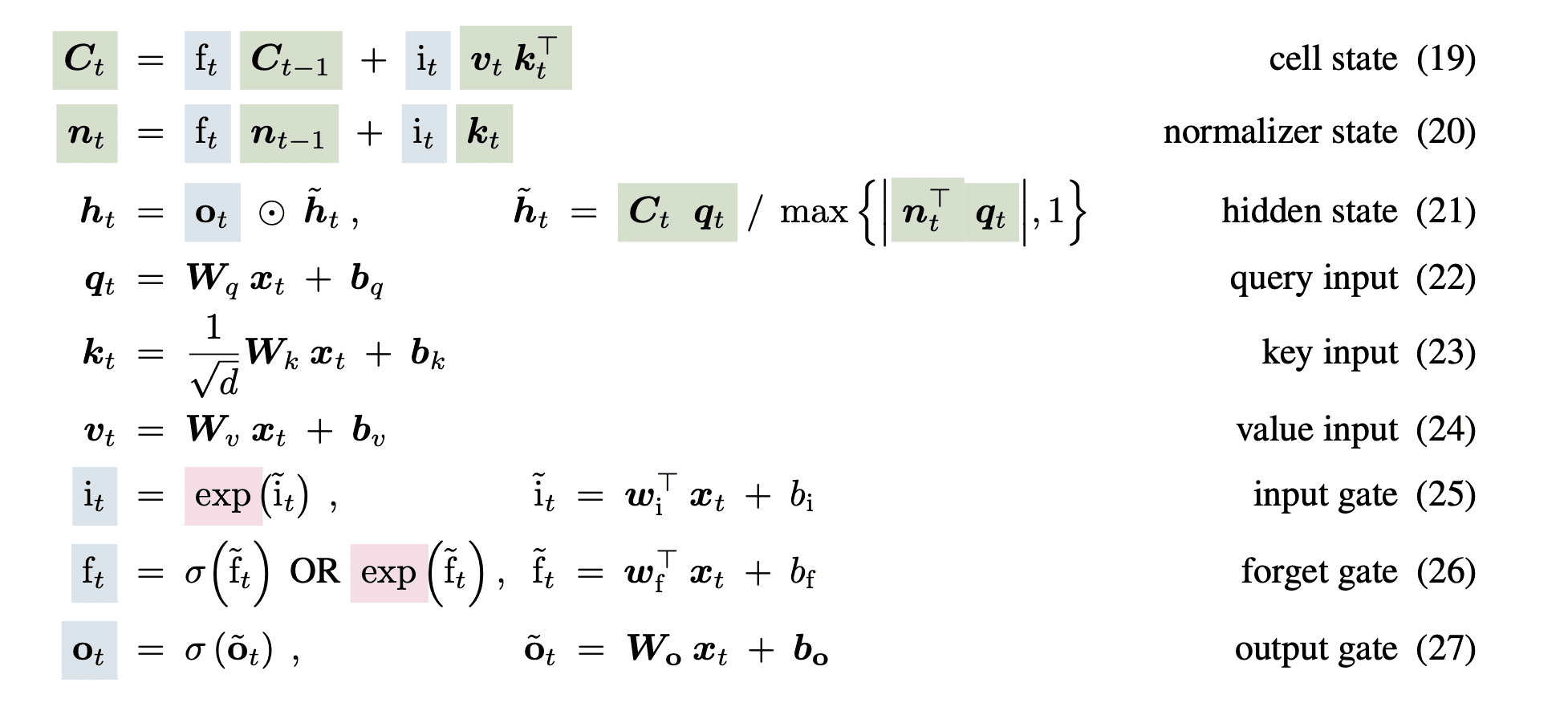
Picture from Paper
Structure Diagram
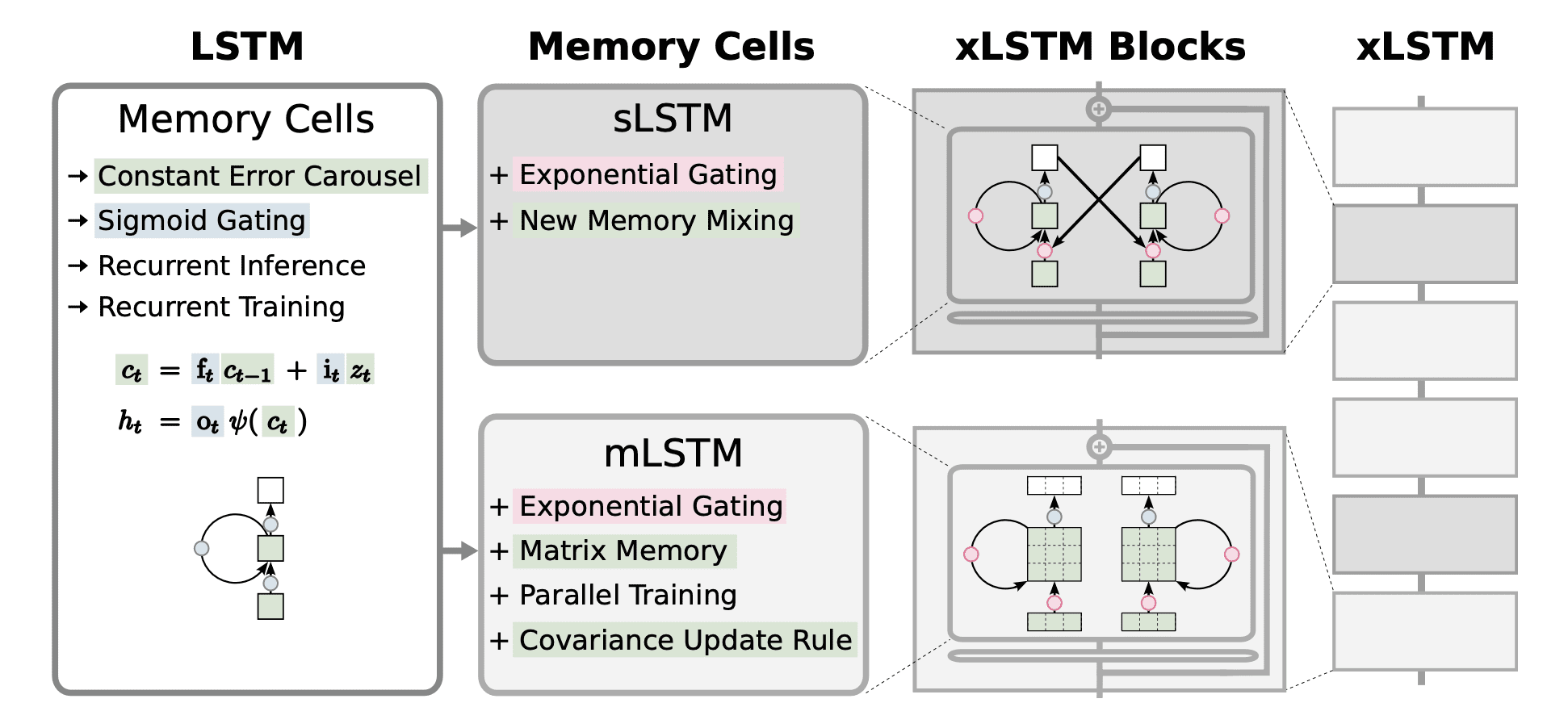
Picture from Paper
The general xLSTM structure is a sequential mixture of mLSTM and sLSTM blocks in numerous proportions. Because the diagram exhibits, the xLSTM block can have any reminiscence cell. The totally different blocks are stacked along with layer normalizations to kind a deep community of residual blocks.
Analysis Outcomes and Comparability
The authors prepare the xLSTM community on language mannequin duties and examine the perplexity (decrease is best) of the educated mannequin with the present Transformer-based LLMs.
The authors first prepare the fashions on 15B tokens from SlimPajama. The outcomes confirmed that xLSTM outperform all different fashions within the validation set with the bottom perplexity rating.
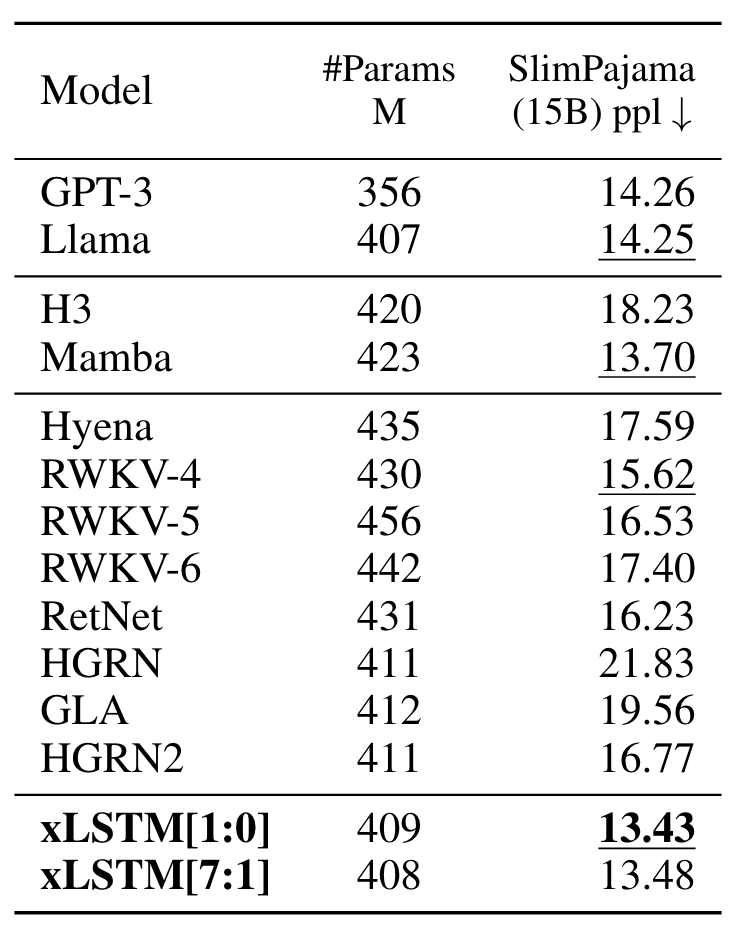
Picture from Paper
Sequence Size Extrapolation
The authors additionally analyze efficiency when the check time sequence size exceeds the context size the mannequin was educated on. They educated all fashions on a sequence size of 2048 and the beneath graph exhibits the validation perplexity with adjustments in token place:
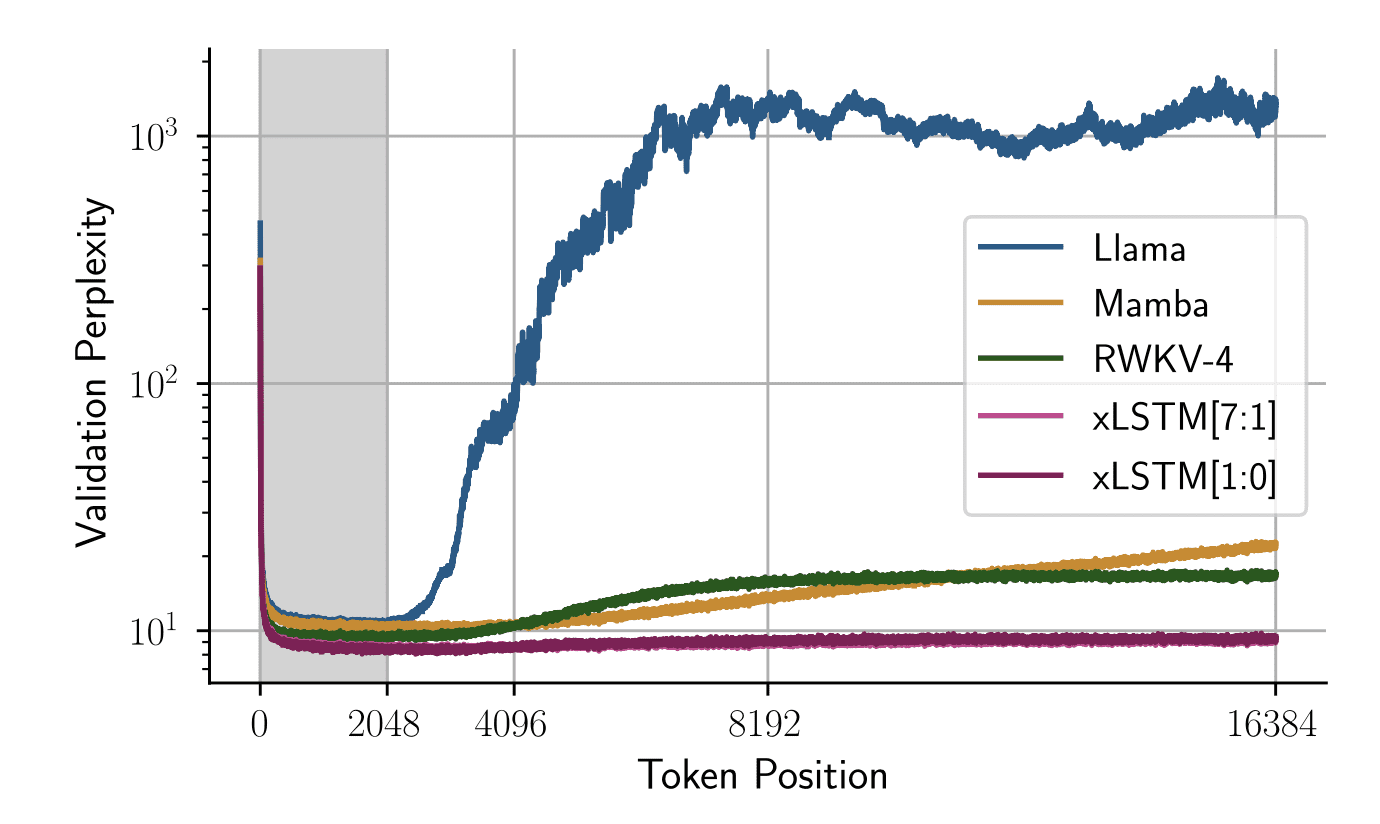
Picture from Paper
The graph exhibits that even for for much longer sequences, xLSTM networks keep a secure perplexity rating and carry out higher than every other mannequin for for much longer context lengths.
Scaling xLSMT to Bigger Mannequin Sizes
The authors additional prepare the mannequin on 300B tokens from the SlimPajama dataset. The outcomes present that even for bigger mannequin sizes, xLSTM scales higher than the present Transformer and Mamba structure.
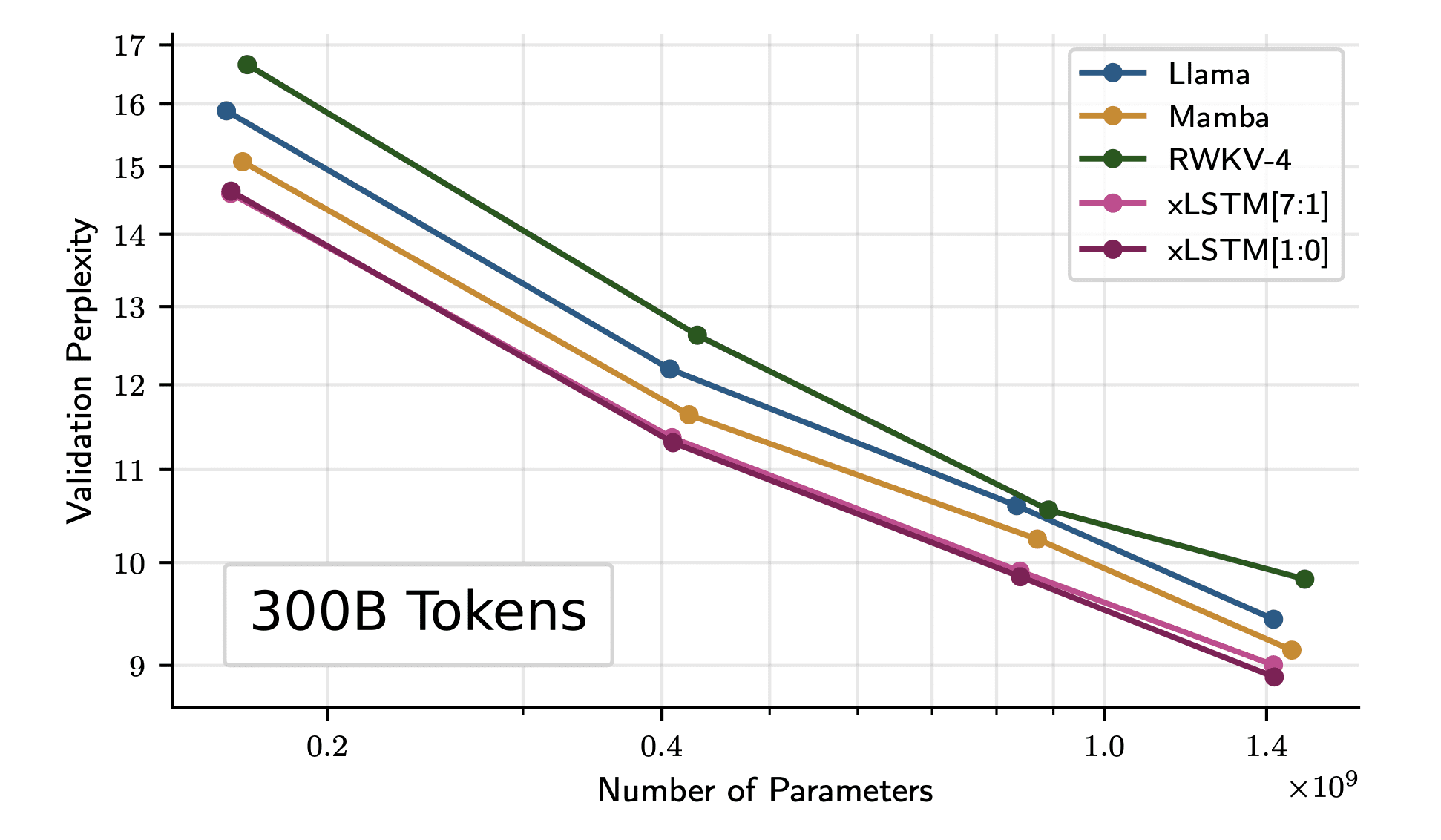
Picture from Paper
Wrapping Up
That may have been obscure and that’s okay! Nonetheless, it’s best to now perceive why this analysis paper has acquired all the eye not too long ago. It has been proven to carry out at the very least in addition to the current massive language fashions if not higher. It’s confirmed to be scalable for bigger fashions and could be a severe competitor for all current LLMs constructed on Transformers. Solely time will inform if LSTMs will regain their glory as soon as once more, however for now, we all know that the xLSTM structure is right here to problem the prevalence of the famend Transformers structure.
Kanwal Mehreen Kanwal is a machine studying engineer and a technical author with a profound ardour for knowledge science and the intersection of AI with drugs. She co-authored the e book “Maximizing Productiveness with ChatGPT”. As a Google Era Scholar 2022 for APAC, she champions range and tutorial excellence. She’s additionally acknowledged as a Teradata Range in Tech Scholar, Mitacs Globalink Analysis Scholar, and Harvard WeCode Scholar. Kanwal is an ardent advocate for change, having based FEMCodes to empower ladies in STEM fields.
[ad_2]