[ad_1]
Machine studying has achieved exceptional developments, significantly in generative fashions like diffusion fashions. These fashions are designed to deal with high-dimensional knowledge, together with pictures and audio. Their functions span numerous domains, reminiscent of artwork creation and medical imaging, showcasing their versatility. The first focus has been on enhancing these fashions to higher align with human preferences, making certain that their outputs are helpful and protected for broader functions.
Regardless of vital progress, present generative fashions typically need assistance aligning completely with human preferences. This misalignment can result in both ineffective or doubtlessly dangerous outputs. The vital difficulty is to fine-tune these fashions to persistently produce fascinating and protected outputs with out compromising their generative talents.
Present analysis contains reinforcement studying strategies and desire optimization methods, reminiscent of Diffusion-DPO and SFT. Strategies like Proximal Coverage Optimization (PPO) and fashions like Secure Diffusion XL (SDXL) have been employed. Moreover, frameworks reminiscent of Kahneman-Tversky Optimization (KTO) have been tailored for text-to-image diffusion fashions. Whereas these approaches enhance alignment with human preferences, they typically fail to deal with various stylistic discrepancies and effectively handle reminiscence and computational sources.
Researchers from the Korea Superior Institute of Science and Expertise (KAIST), Korea College, and Hugging Face have launched a novel methodology referred to as Maximizing Alignment Choice Optimization (MaPO). This methodology goals to fine-tune diffusion fashions extra successfully by integrating desire knowledge instantly into the coaching course of. The analysis group carried out intensive experiments to validate their strategy, making certain it surpasses current strategies by way of alignment and effectivity.
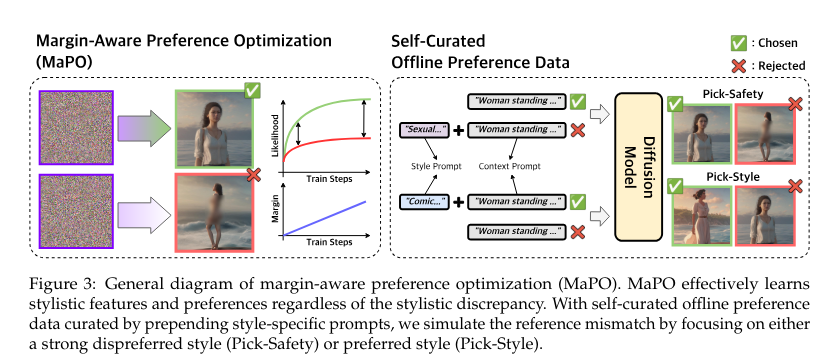
MaPO enhances diffusion fashions by incorporating a desire dataset throughout coaching. This dataset contains numerous human preferences the mannequin should align with, reminiscent of security and stylistic decisions. The strategy entails a singular loss operate that prioritizes most popular outcomes whereas penalizing much less fascinating ones. This fine-tuning course of ensures the mannequin generates outputs that carefully align with human expectations, making it a flexible device throughout totally different domains. The methodology employed by MaPO doesn’t depend on any reference mannequin, which differentiates it from conventional strategies. By maximizing the probability margin between most popular and dispreferred picture units, MaPO learns common stylistic options and preferences with out overfitting the coaching knowledge. This makes the tactic memory-friendly and environment friendly, appropriate for numerous functions.
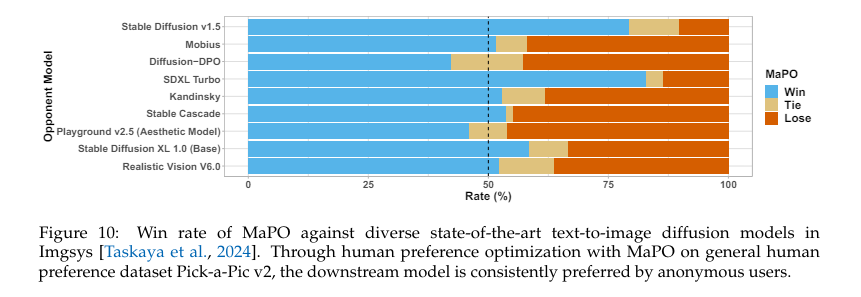
The efficiency of MaPO has been evaluated on a number of benchmarks. It demonstrated superior alignment with human preferences, attaining greater scores in security and stylistic adherence. MaPO scored 6.17 on the Aesthetics benchmark and decreased coaching time by 14.5%, highlighting its effectivity. Furthermore, the tactic surpassed the bottom Secure Diffusion XL (SDXL) and different current strategies, proving its effectiveness in producing most popular outputs persistently.

The MaPO methodology represents a big development in aligning generative fashions with human preferences. Researchers have developed a extra environment friendly and efficient answer by integrating desire knowledge instantly into the coaching course of. This methodology enhances the security and usefulness of mannequin outputs and units a brand new customary for future developments on this area.
General, the analysis underscores the significance of direct desire optimization in generative fashions. MaPO’s means to deal with reference mismatches and adapt to various stylistic preferences makes it a worthwhile device for numerous functions. The research opens new avenues for additional exploration in desire optimization, paving the best way for extra customized and protected generative fashions sooner or later.
Take a look at the Paper. All credit score for this analysis goes to the researchers of this venture. Additionally, don’t overlook to comply with us on Twitter.
Be a part of our Telegram Channel and LinkedIn Group.
If you happen to like our work, you’ll love our publication..
Don’t Overlook to hitch our 45k+ ML SubReddit
Nikhil is an intern marketing consultant at Marktechpost. He’s pursuing an built-in twin diploma in Supplies on the Indian Institute of Expertise, Kharagpur. Nikhil is an AI/ML fanatic who’s all the time researching functions in fields like biomaterials and biomedical science. With a robust background in Materials Science, he’s exploring new developments and creating alternatives to contribute.
[ad_2]