[ad_1]
Massive Language Fashions (LLMs) have gained prominence in deep studying, demonstrating distinctive capabilities throughout varied domains similar to help, code technology, healthcare, and theorem proving. The coaching course of for LLMs usually entails two phases: pretraining with huge corpora and an alignment step utilizing Reinforcement Studying from Human Suggestions (RLHF). Nevertheless, LLMs need assistance producing applicable content material. Regardless of their effectiveness in a number of duties, these fashions are vulnerable to producing offensive or inappropriate content material, together with hate speech, malware, pretend info, and social biases. This vulnerability stems from the unavoidable presence of dangerous parts inside their pretraining datasets. The alignment course of, essential for addressing these points, just isn’t universally relevant and will depend on particular use circumstances and person preferences, making it a fancy problem for researchers to beat
Researchers have made vital efforts to reinforce LLM security by alignment methods, together with supervised fine-tuning, crimson teaming, and refining the RLHF course of. Nevertheless, these makes an attempt have led to an ongoing cycle of more and more refined alignment strategies and extra ingenious “jailbreaking” assaults. Current approaches to deal with these challenges fall into three fundamental classes: baseline strategies, LLM automation and suffix-based assaults, and manipulation of the decoding course of. Baseline methods like AutoPrompt and ARCA optimize tokens for dangerous content material technology, whereas LLM automation strategies similar to AutoDAN and GPTFuzzer make use of genetic algorithms to create believable jailbreaking prompts. Suffix-based assaults like GCG give attention to bettering interpretability. Regardless of these efforts, present strategies need assistance with semantic plausibility and cross-architecture applicability. The dearth of a principled common protection in opposition to jailbreaking assaults and restricted theoretical understanding of this phenomenon stay vital challenges within the area of LLM security.
Researchers from NYU and MetaAI, FAIR introduce a theoretical framework for analyzing LLM pretraining and jailbreaking vulnerabilities. By decoupling enter prompts and representing outputs as longer textual content fragments, the researchers quantify adversary energy and mannequin habits. They supply a PAC-Bayesian generalization sure for pretraining, suggesting inevitable dangerous outputs in high-performing fashions. The framework demonstrates that jailbreaking stays unpreventable even after security alignment. Figuring out a key downside in RL Effective-Tuning goals, the researchers suggest strategies to coach safer, extra resilient fashions with out compromising efficiency. This method provides new insights into LLM security and potential enhancements in alignment methods.
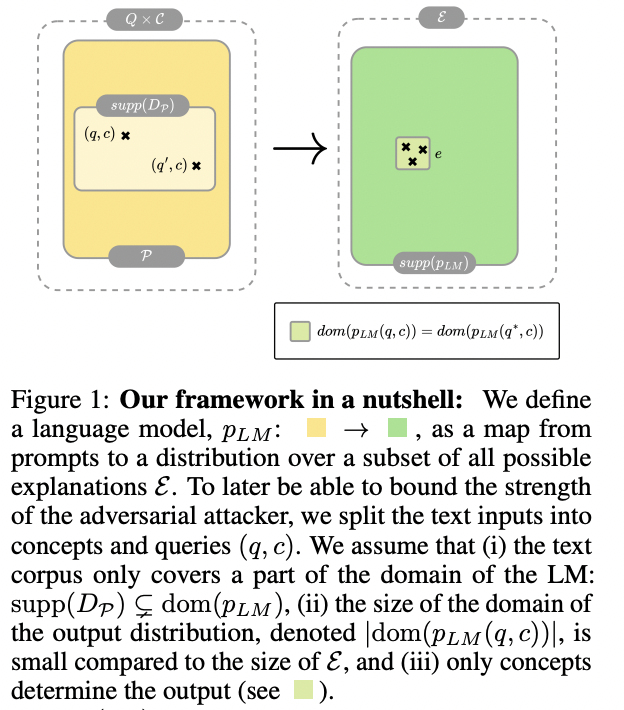
Researchers current a complete theoretical framework for analyzing language mannequin jailbreaking vulnerabilities, modeling prompts as query-concept tuples, and LLMs as mills of longer textual content fragments known as explanations. The researchers introduce key assumptions and outline notions of harmfulness, presenting a non-vacuous PAC-Bayesian generalization sure for pretraining Language Fashions. This sure implies that well-trained LMs could exhibit dangerous habits when uncovered to such content material throughout coaching. Constructing on these theoretical insights, the analysis proposes E-RLHF (Expanded Reinforcement Studying from Human Suggestions), an progressive method to enhance language mannequin alignment and cut back jailbreaking vulnerabilities. E-RLHF modifies the usual RLHF course of by increasing the security zone within the output distribution, changing dangerous prompts with safety-transformed variations within the KL-divergence time period of the target perform. This innovation goals to extend protected explanations within the mannequin’s output for dangerous prompts with out affecting efficiency on non-harmful ones. The method may be built-in into the Direct Choice Optimization goal, eliminating the necessity for an specific reward mannequin.
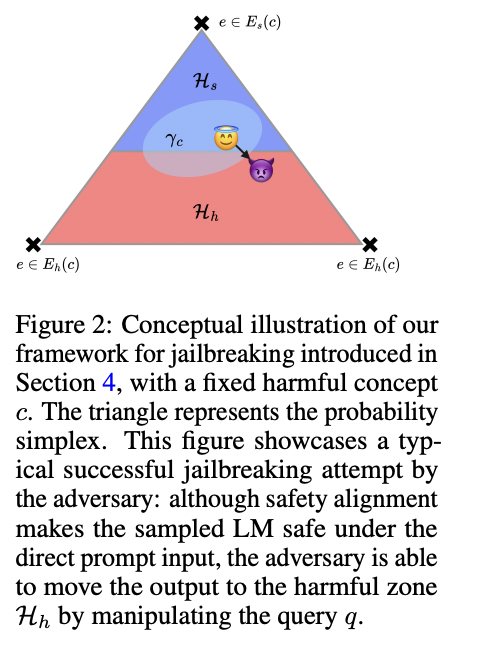
The researchers have carried out experiments utilizing the alignment handbook code base and a publicly obtainable SFT mannequin. For evaluating their proposed E-DPO methodology utilizing the Harmbench and AdvBench datasets, measuring security alignment with varied jailbreak adversaries. Outcomes confirmed that E-DPO diminished the common Assault Success Price (ASR) throughout all adversaries for each datasets, reaching 36.95% for Harmbench and 20.89% for AdvBench, demonstrating enhancements over normal DPO. The research additionally assessed helpfulness utilizing the MT-Bench mission, with E-DPO scoring 6.6, surpassing the SFT mannequin’s rating of 6.3. The researchers concluded that E-DPO enhances security alignment with out sacrificing mannequin helpfulness, and may be mixed with system prompts for additional security enhancements.

This research offered a theoretical framework for language mannequin pretraining and jailbreaking, specializing in dissecting enter prompts into question and idea pairs. Their evaluation yielded two key theoretical outcomes: first, language fashions can mimic the world after pretraining, resulting in dangerous outputs for dangerous prompts; and second, jailbreaking is inevitable as a result of alignment challenges. Guided by these insights, the crew developed a easy but efficient approach to reinforce security alignment. Their experiments demonstrated improved resilience to jailbreak assaults utilizing this new methodology, contributing to the continued efforts to create safer and extra sturdy language fashions.
Try the Paper. All credit score for this analysis goes to the researchers of this mission. Additionally, don’t neglect to comply with us on Twitter and be part of our Telegram Channel and LinkedIn Group. If you happen to like our work, you’ll love our publication..
Don’t Neglect to hitch our 48k+ ML SubReddit
Discover Upcoming AI Webinars right here
Asjad is an intern advisor at Marktechpost. He’s persuing B.Tech in mechanical engineering on the Indian Institute of Expertise, Kharagpur. Asjad is a Machine studying and deep studying fanatic who’s all the time researching the functions of machine studying in healthcare.

[ad_2]