[ad_1]
Introduction
In our earlier articles, we’ve mentioned loading various kinds of information and alternative ways of splitting that information. The information is break up to seek out the related content material to the question from all the info. Now, we’re leaping into the way forward for information retrieval. This text will discover the cutting-edge strategy of utilizing vector embeddings with LangChain to seek out content material that carefully matches your question effectively. Be a part of us as we uncover how this highly effective strategy transforms information dealing with, making searches quicker, extra correct, and intuitive.

Overview
- Study the basics of textual content embeddings, together with representing phrases and sentences as numerical vectors to seize semantic meanings.
- Achieve sensible expertise utilizing LangChain’s and hugging face embedding fashions to compute and examine sentence embeddings.
- Discover tips on how to effectively retailer and retrieve related paperwork utilizing vector databases utilizing Approximate Nearest Neighbor algorithms.
- Perceive LangChain’s indexing modes and be taught to successfully handle doc updates and deletions to take care of an optimum vector database.
Sentence Embeddings
Earlier than utilizing embedding fashions from LangChain, let’s briefly evaluate what embeddings are within the context of textual content.
To carry out any computation with the textual content, we have to convert it into numerical kind. Since all phrases are inherently associated to one another, we will symbolize them as vectors of numbers that seize their semantic meanings. For instance, the gap between the vectors representing two synonyms is smaller for synonyms and better for antonyms. That is sometimes completed utilizing fashions like BERT.
Because the variety of sentences is vastly increased than the variety of phrases, we will’t calculate the embeddings for every sentence in the way in which we calculate the phrase embeddings. Sentence embeddings are calculated utilizing SentenceBERT fashions, which use the Siamese community. For extra particulars, learn Sentence Embedding.
Let’s Create LangChain Paperwork
Necessities
Set up langchain_openai, langchain-huggingface, and langchain-chroma packages utilizing pip along with langchain and langchain_community libraries. Be certain that so as to add the OpenAI API key to make use of OpenAI embedding fashions.
pip set up langchain_openai langchain-huggingface langchain-chroma langchain langchain_communityInstance: Creating LangChain Paperwork
I’m utilizing just a few instance sentences and a question sentence to elucidate the subjects on this article. Later, allow us to additionally create LangChain paperwork utilizing the sentences and classes.
from langchain_core.paperwork import Doc
sentences = [
"The Milky Way galaxy contains billions of stars, each potentially hosting its own planetary system.",
"Photosynthesis is a process used by plants to convert light energy into chemical energy.",
"The principles of supply and demand are fundamental to understanding market economies.",
"In calculus, the derivative represents the rate of change of a function with respect to a variable.",
"Quantum mechanics explores the behavior of particles at the smallest scales, where classical physics no longer applies.",
"Enzymes are biological catalysts that speed up chemical reactions in living organisms.",
"Game theory is a mathematical framework used for analyzing strategic interactions between rational decision-makers.",
"The double helix structure of DNA was discovered by Watson and Crick in 1953, revolutionizing biology."
]
classes = ["Astronomy", "Biology", "Economics", "Mathematics", "Physics", "Biochemistry", "Mathematics", "Biology"]
question = 'Crops use daylight to create power via a course of referred to as photosynthesis.'
paperwork = []
for i, sentence in enumerate(sentences):
paperwork.append(Doc(page_content=sentence, metadata={'supply': classes[i]}))
# creating Paperwork with metadata the place 'supply' is the class
# The paperwork might be as follows
Embeddings with LangChain
Allow us to initialize the embedding mannequin and embed the sentences.
import os
from dotenv import load_dotenv
load_dotenv(api_keys.env)
from langchain_openai import OpenAIEmbeddings
embedding_model = OpenAIEmbeddings(mannequin="text-embedding-3-small", show_progress_bar=True)
embeddings = embedding_model.embed_documents(sentences)
# verify the overall variety of embeddings and embedding dimension
len(embeddings)
>>> 8
len(embeddings[0])
>>> 1536Now, let’s calculate the cosine similarity of sentences with one another and plot them as warmth maps.
import numpy as np
import seaborn as sns
from sklearn.metrics.pairwise import cosine_similarity
similarities = cosine_similarity(embeddings)
sns.heatmap(similarities, cmap='magma', middle=None, annot=True, fmt=".2f", yticklabels=sentences)
As we will see, sentences that belong to the identical class and are related to one another have the next correlation to one another than with others.
Let’s compute the cosine similarities of those sentences w.r.t. the question sentence. We are able to discover probably the most related sentence to the question sentence.
query_embedding = embedding_model.embed_query(question)
query_similarities = cosine_similarity(X=[query_embedding], Y=embeddings)
#prepare the sentences within the descending order of their similarity with question sentence
for i in np.argsort(similarities[0])[::-1]:
print(format(query_similarities[0][i], '.3f'), sentences[i])
"0.711 Photosynthesis is a course of utilized by crops to transform mild power into chemical power.
0.206 Enzymes are organic catalysts that pace up chemical reactions in dwelling organisms.
0.172 The Milky Means galaxy accommodates billions of stars, every probably internet hosting its personal planetary system.
0.104 The double helix construction of DNA was found by Watson and Crick in 1953, revolutionizing biology.
0.100 Quantum mechanics explores the conduct of particles on the smallest scales, the place classical physics now not applies.
0.098 The ideas of provide and demand are elementary to understanding market economies.
0.067 Sport principle is a mathematical framework used for analyzing strategic interactions between rational decision-makers.
0.053 In calculus, the spinoff represents the speed of change of a perform with respect to a variable.""We are able to run them domestically as a result of embedding fashions require a lot much less computing energy than LLMs. Let’s run an open-source embedding mannequin. We are able to examine and select fashions from Huggingface.
from langchain_huggingface import HuggingFaceEmbeddings
hf_embedding_model = HuggingFaceEmbeddings(model_name="Snowflake/snowflake-arctic-embed-m")
embeddings = hf_embedding_model.embed_documents(sentences)
len(embeddings)
>>> 8
len(embeddings[0])
>>> 768We are able to calculate the question embeddings and compute similarities with sentences as we’ve completed above.
An necessary factor to notice is every embedding mannequin is probably going skilled on totally different information, so the vector embeddings of every mannequin are doubtless in several vector areas. So, if we embed the sentences and question with totally different embedding fashions, the outcomes could be inaccurate even when the embedding dimensions are the identical.
Utilizing Vector Retailer
Within the above instance of discovering related sentences, we’ve in contrast the question embedding with every sentence embedding. Nevertheless, if we’ve to seek out related paperwork from thousands and thousands of paperwork, evaluating question embedding with every will take loads of time. We are able to use approximate nearest neighbors algorithms utilizing a vector database to seek out probably the most environment friendly resolution. To learn how these algorithms work, please consult with ANN Algorithms in Vector Databases.
Allow us to retailer the above instance sentences within the vector retailer.
from langchain_chroma import Chroma
db = Chroma.from_texts(texts=sentences, embedding=embedding_model, persist_directory='./sentences_db',
collection_name="instance", collection_metadata={"hnsw:area": "cosine"}) Code rationalization
- Chroma.from_texts: That is to create a database utilizing texts. Chroma.from_documents can be utilized to make use of LangChain paperwork.
- embedding: That is an embedding mannequin loaded via LangChain.
- persist_directory: By including a location, we will save the database to load it later and keep away from computing embeddings once more.
- collection_name: Identify for the gathering of paperwork we’re storing. Be certain that the listing title and assortment title are totally different.
- collection_metadata: This specifies the gap metric used for evaluating embeddings. Different choices are ‘l2’ (l2 norm) and ‘ip’ (interior product)
A number of the strategies we will use on the database are as follows
# it will get the ids of the paperwork
ids = db.get()['ids']
# can used to get different information concerning the paperwork
db.get(embody=['embeddings', 'metadatas', 'documents'])
# this can be utilized to delete paperwork by id.
db._collection.delete(ids=ids)
# that is to delete the gathering
db.delete_collection()Now, we will search the database with the question and get the gap between the question embedding and sentences.
db.similarity_search_with_score(question=question, okay=3)
# the above will get the paperwork with distance metric.
# If we wish similarity scores we will use
db.similarity_search_with_relevance_scores(question=question, okay=3)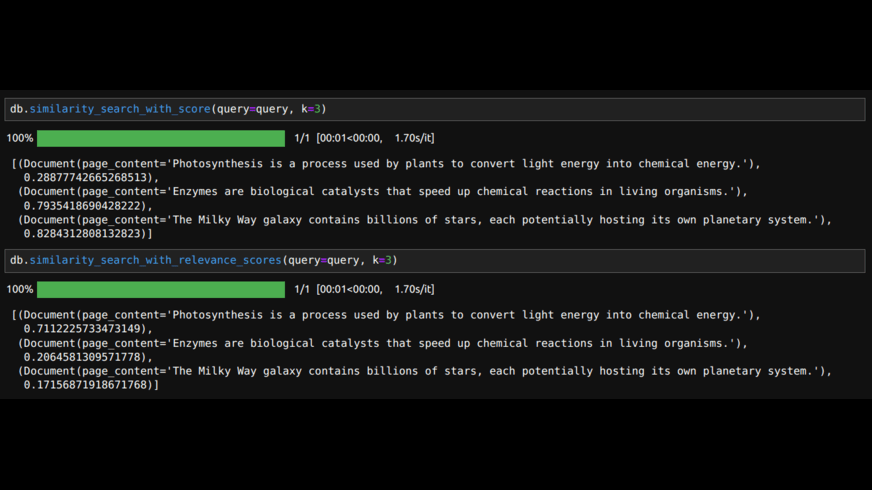
To get the relevance scores inside 0 to 1 for the ‘l2’ distance metric, we have to cross the relevance_score_fn
db = Chroma.from_texts(texts=sentences, embedding=embedding_model, relevance_score_fn=lambda distance: 1.0 - distance / 2,
collection_name="sentences", collection_metadata={"hnsw:area": "l2"})Within the above code, we’ve solely used the LangChain library. We are able to additionally straight use chromadb as follows:
import chromadb
from chromadb.utils.embedding_functions import OpenAIEmbeddingFunction
embedding_function = OpenAIEmbeddingFunction(api_key=os.environ.get('OPENAI_API_KEY'), model_name="text-embedding-3-small")
# initialize the shopper
shopper = chromadb.PersistentClient('./sentence_db')
# create a set if it did not exist in any other case load it
assortment = shopper.get_or_create_collection('instance', metadata={'hnsw:area': 'cosine'}, embedding_function=embedding_function)
# add sentences with any ids
assortment.add(ids=ids, paperwork=sentences)
# now initialize the database assortment to question
db = Chroma(shopper=shopper, collection_name="instance", embedding_function=embedding_model)
# word that the embedding_function parameter right here wants the embedding mannequin loaded utilizing langchainLoading the vector database from a saved listing is as follows:
db2 = Chroma(persist_directory="./sentences_db/", collection_name="instance", embedding_function=embedding_model)
# be sure you point out the gathering title that you've used whereas creating the database.
# we will search this database as we've beforehand.Typically, we might by accident run the add paperwork code once more, which is able to add the identical paperwork to the database, creating pointless duplicates. We may additionally have to replace some paperwork and delete all however just a few.
For all of that, we will use Indexing API from LangChain
Indexing
LangChain indexing makes use of a File Supervisor to trace doc entries within the vector retailer. Subsequently, we will’t use Indexing for an current database, because the file supervisor doesn’t observe the database’s current content material.
When content material is listed, hashes are computed for every doc, and the next info is saved within the File Supervisor.
- Doc Hash: A hash of each the web page content material and its metadata.
- Write Time: The timestamp when the doc was written.
- Supply ID: Metadata that features info to establish the final word supply of the doc.
Utilizing these, we will keep away from re-writing and re-computing embeddings over unchanged content material. There are three modes of Indexing. None, Incremental, Full:
- None mode avoids writing duplicate content material to the vector retailer and doesn’t replace or delete something.
- Incremental mode updates the database with new content material and deletes outdated content material for a given supply.
- Full mode deletes any content material not discovered within the at the moment listed content material.
The classes we added as sources within the metadata when creating paperwork might be helpful right here.
from langchain.indexes import SQLRecordManager, index
# initialize the database
db = Chroma(persist_directory='./sentence_db', collection_name="instance",
embedding_function=embedding_model, collection_metadata={"hnsw:area": "cosine"})
# title a namespace that signifies database and assortment
namespace = f"db/instance"
record_manager = SQLRecordManager(namespace, db_url="sqlite:///record_manager.sql")
record_manager.create_schema()
# load and index the paperwork
index(docs_source=paperwork, record_manager=record_manager, vector_store=db, cleanup=None)
>>> {'num_added': 8, 'num_updated': 0, 'num_skipped': 0, 'num_deleted': 0}If we run the final line of code once more, we are going to see num_skipped as 8 and all others as 0.
doc1 = Doc(page_content="The human immune system protects the physique from infections by figuring out and destroying pathogens",
metadata={"supply": "Biology"})
doc2 = Doc(page_content="Genetic mutations can result in variations in traits, which can be helpful, impartial, or dangerous",
metadata={"supply": "Biology"})
# add these docs to the database in incremental mode
index(docs_source=[doc1, doc2], record_manager=record_manager, vector_store=db, cleanup='incremental', source_id_key='supply')
>>> {'num_added': 2, 'num_updated': 0, 'num_skipped': 0, 'num_deleted': 0}With the above code, each are added, and none are deleted, because the earlier 8 paperwork are usually not added in incremental mode. If the earlier 8 have been added in incremental mode, then 2 paperwork can be deleted, and a couple of can be added.
If we barely change doc2 and rerun the indexing code, doc1 might be skipped as it isn’t modified, the prevailing doc2 might be deleted from the database, and the modified doc2 might be added. That is denoted as {‘num_added’: 1, ‘num_updated’: 0, ‘num_skipped’: 1, ‘num_deleted’: 1}
Within the full mode, if we don’t point out any docs whereas indexing, all the prevailing docs might be deleted.
index([], record_manager=record_manager, vector_store=db, cleanup="full", source_id_key="supply")
>>> {'num_added': 0, 'num_updated': 0, 'num_skipped': 0, 'num_deleted': 10}
# it will delete all of the paperwork in databaseSo, through the use of totally different modes, we will effectively handle what information to maintain and what to replace and delete. Apply this indexing with totally different combos of modes to grasp it higher.
Conclusion
Right here, we’ve demonstrated tips on how to effectively discover content material much like a question utilizing vector embeddings with LangChain. We are able to obtain correct and scalable content material retrieval by leveraging embedding fashions and vector databases. Moreover, LangChain’s indexing capabilities permit for efficient administration of doc updates and deletions, making certain optimum database efficiency and relevance.
Within the subsequent article, we are going to focus on alternative ways of retrieving the content material to ship to the LLM.
Ceaselessly Requested Questions
Ans. Textual content embeddings are numerical representations of textual content that seize semantic meanings. They’re necessary as a result of they permit us to carry out computations with textual content, equivalent to discovering related sentences or phrases based mostly on their meanings.
Ans. LangChain offers instruments to initialize embedding fashions and compute embeddings for sentences. It additionally facilitates evaluating these embeddings utilizing similarity measures like cosine similarity, enabling environment friendly content material retrieval.
Ans. Vector databases retailer embeddings and use Approximate Nearest Neighbors (ANN) algorithms to rapidly discover related paperwork from a big dataset. This makes the retrieval course of a lot quicker and scalable.
Ans. LangChain’s indexing function makes use of a File Supervisor to trace doc entries and handle updates and deletions. It affords totally different modes (None, Incremental, Full) to deal with duplicate content material, updates, and clean-ups effectively, making certain the database stays correct and up-to-date.
[ad_2]