[ad_1]
Giant language fashions (LLMs) fashions, designed to grasp and generate human language, have been utilized in numerous domains, akin to machine translation, sentiment evaluation, and conversational AI. LLMs, characterised by their in depth coaching information and billions of parameters, are notoriously computationally intensive, posing challenges to their growth and deployment. Regardless of their capabilities, coaching and deploying these fashions is resource-heavy, typically requiring in depth computational energy and huge datasets, resulting in substantial prices.
One of many major challenges on this space is the resource-intensive nature of coaching a number of variants of LLMs from scratch. Researchers purpose to create completely different mannequin sizes to go well with numerous deployment wants, however this course of calls for huge computational sources and huge coaching information. The excessive value related to this method makes it troublesome to scale and deploy these fashions effectively. The necessity to scale back these prices with out compromising mannequin efficiency has pushed researchers to discover different strategies.
Present approaches to mitigate these challenges embody numerous pruning methods and information distillation strategies. Pruning systematically removes much less vital weights or neurons from a pre-trained mannequin, decreasing its dimension and computational calls for. Alternatively, information distillation transfers information from a bigger, extra complicated mannequin (the instructor) to a smaller, less complicated mannequin (the coed), enhancing the coed mannequin’s efficiency whereas requiring fewer sources for coaching. Regardless of these methods, discovering a stability between mannequin dimension, coaching value, and efficiency stays a major problem.
Researchers at NVIDIA have launched a novel method to prune and retrain LLMs effectively. Their technique focuses on structured pruning, systematically eradicating complete neurons, layers, or consideration heads primarily based on their calculated significance. This method is mixed with a information distillation course of, permitting the pruned mannequin to be retrained utilizing a small fraction of the unique coaching information. This technique goals to retain the efficiency of the unique mannequin whereas considerably decreasing the coaching value and time. The researchers have developed the Minitron mannequin household and have open-sourced these fashions on Huggingface for public use.
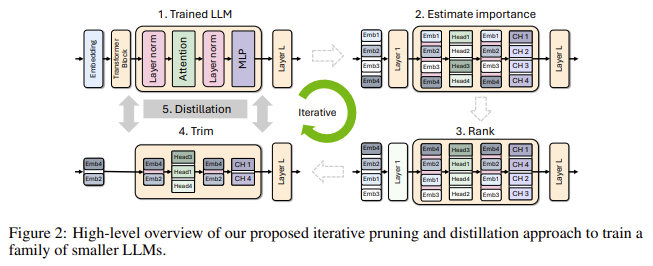
The proposed technique begins with an present giant mannequin and prunes it to create smaller, extra environment friendly variants. The significance of every part—neuron, head, layer—is calculated utilizing activation-based metrics throughout ahead propagation on a small calibration dataset of 1024 samples. Elements deemed much less vital are pruned. Following this, the pruned mannequin undergoes a information distillation-based retraining, which helps get better the mannequin’s accuracy. This course of leverages a considerably smaller dataset, making the retraining part a lot much less resource-intensive than conventional strategies.
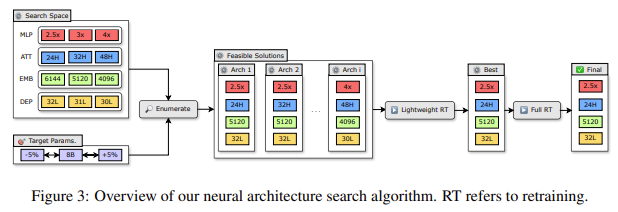
The efficiency of this technique was evaluated on the Nemotron-4 mannequin household. The researchers achieved a 2-4× discount in mannequin dimension whereas sustaining comparable efficiency ranges. Particularly, utilizing this technique, the 8B and 4B fashions derived from a 15B mannequin required as much as 40× fewer coaching tokens than coaching from scratch. This resulted in compute value financial savings of 1.8× for coaching your entire mannequin household (15B, 8B, and 4B). Notably, the 8B mannequin demonstrated a 16% enchancment in MMLU scores in comparison with fashions skilled from scratch. These fashions carried out comparably to different well-known neighborhood fashions, akin to Mistral 7B, Gemma 7B, and LLaMa-3 8B, outperforming state-of-the-art compression methods from present literature. The Minitron fashions have been made accessible on Huggingface for public use, offering the neighborhood entry to those optimized fashions.

In conclusion, the researchers at NVIDIA have demonstrated that structured pruning mixed with information distillation can scale back the associated fee and sources required to coach giant language fashions. By using activation-based metrics and a small calibration dataset for pruning, adopted by environment friendly retraining utilizing information distillation, they’ve proven that it’s doable to keep up and, in some circumstances, enhance mannequin efficiency whereas drastically chopping down on computational prices. This modern method paves the best way for extra accessible and environment friendly NLP functions, making it possible to deploy LLMs at numerous scales with out incurring prohibitive prices.
Try the Paper and Fashions. All credit score for this analysis goes to the researchers of this venture. Additionally, don’t neglect to comply with us on Twitter and be part of our Telegram Channel and LinkedIn Group. When you like our work, you’ll love our e-newsletter..
Don’t Neglect to affix our 47k+ ML SubReddit
Discover Upcoming AI Webinars right here
Asif Razzaq is the CEO of Marktechpost Media Inc.. As a visionary entrepreneur and engineer, Asif is dedicated to harnessing the potential of Synthetic Intelligence for social good. His most up-to-date endeavor is the launch of an Synthetic Intelligence Media Platform, Marktechpost, which stands out for its in-depth protection of machine studying and deep studying information that’s each technically sound and simply comprehensible by a large viewers. The platform boasts of over 2 million month-to-month views, illustrating its recognition amongst audiences.

[ad_2]