[ad_1]
Retrieval-augmented era (RAG) has emerged as a vital method for enhancing massive language fashions (LLMs) to deal with specialised information, present present data, and adapt to particular domains with out altering mannequin weights. Nevertheless, the present RAG pipeline faces vital challenges. LLMs battle with processing quite a few chunked contexts effectively, typically performing higher with a smaller set of extremely related contexts. Additionally, guaranteeing excessive recall of related content material inside a restricted variety of retrieved contexts poses difficulties. Whereas separate rating fashions can enhance context choice, their zero-shot generalization capabilities are sometimes restricted in comparison with versatile LLMs. These challenges spotlight the necessity for a more practical RAG strategy for balancing high-recall context extraction with high-quality content material era.
In prior research, researchers have made quite a few makes an attempt to deal with the challenges in RAG methods. Some approaches concentrate on aligning retrievers with LLM wants, whereas others discover multi-step retrieval processes or context-filtering strategies. Instruction-tuning methods have been developed to boost each search capabilities and the RAG efficiency of LLMs. Finish-to-end optimization of retrievers alongside LLMs has proven promise however introduces complexities in coaching and database upkeep.
Rating strategies have been employed as an middleman step to enhance data retrieval high quality in RAG pipelines. Nevertheless, these typically depend on extra fashions like BERT or T5, which can lack the mandatory capability to completely seize query-context relevance and battle with zero-shot generalization. Whereas current research have demonstrated LLMs’ robust rating skills, their integration into RAG methods stays underexplored.
Regardless of these developments, present strategies want to enhance in effectively balancing high-recall context extraction with high-quality content material era, particularly when coping with advanced queries or various information domains.
Researchers from NVIDIA and Georgia Tech launched an revolutionary framework RankRAG, designed to boost the capabilities of LLMs in RAG duties. This strategy uniquely instruction-tunes a single LLM to carry out each context rating and reply era inside the RAG framework. RankRAG expands on present instruction-tuning datasets by incorporating context-rich question-answering, retrieval-augmented QA, and rating datasets. This complete coaching strategy goals to enhance the LLM’s means to filter irrelevant contexts throughout each the retrieval and era phases.
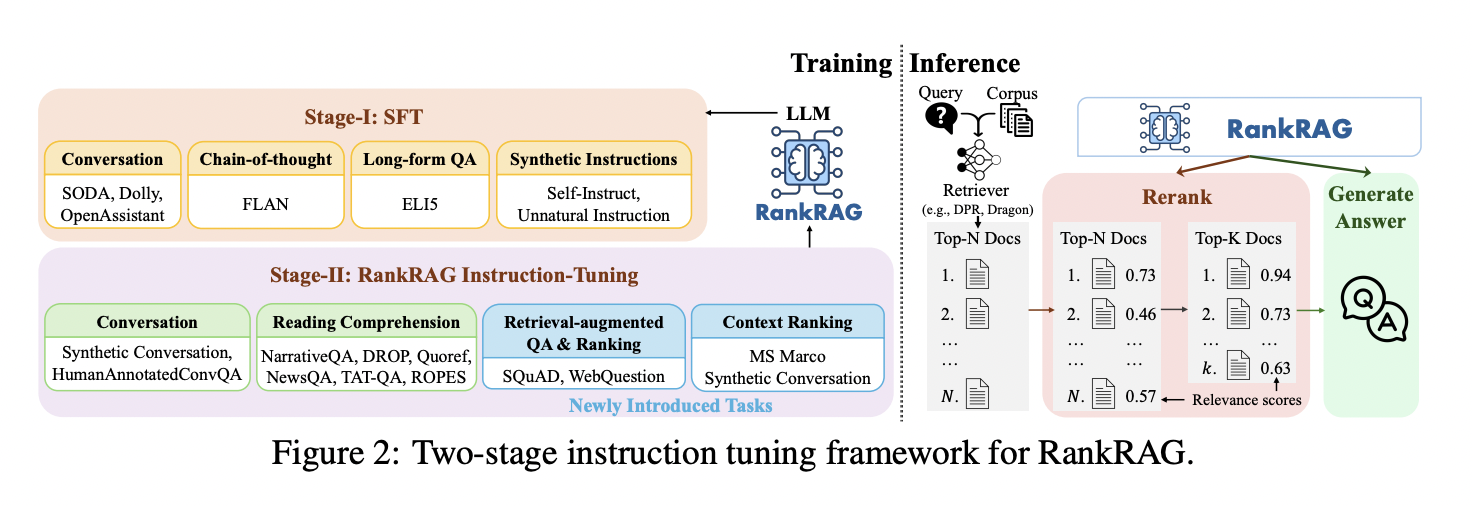
The framework introduces a specialised job that focuses on figuring out related contexts or passages for given questions. This job is structured for rating however framed as common question-answering with directions, aligning extra successfully with RAG duties. Throughout inference, the LLM first reranks retrieved contexts earlier than producing solutions primarily based on the refined top-k contexts. This versatile strategy might be utilized to a variety of knowledge-intensive pure language processing duties, providing a unified answer for enhancing RAG efficiency throughout various domains.
RankRAG enhances LLMs for retrieval-augmented era via a two-stage instruction tuning course of. The primary stage entails supervised fine-tuning on various instruction-following datasets. The second stage unifies rating and era duties, incorporating context-rich QA, retrieval-augmented QA, context rating, and retrieval-augmented rating information. All duties are standardized right into a (query, context, reply) format, facilitating information switch. Throughout inference, RankRAG employs a retrieve-rerank-generate pipeline: it retrieves top-N contexts, reranks them to pick probably the most related top-k, and generates solutions primarily based on these refined contexts. This strategy improves each context relevance evaluation and reply era capabilities inside a single LLM.
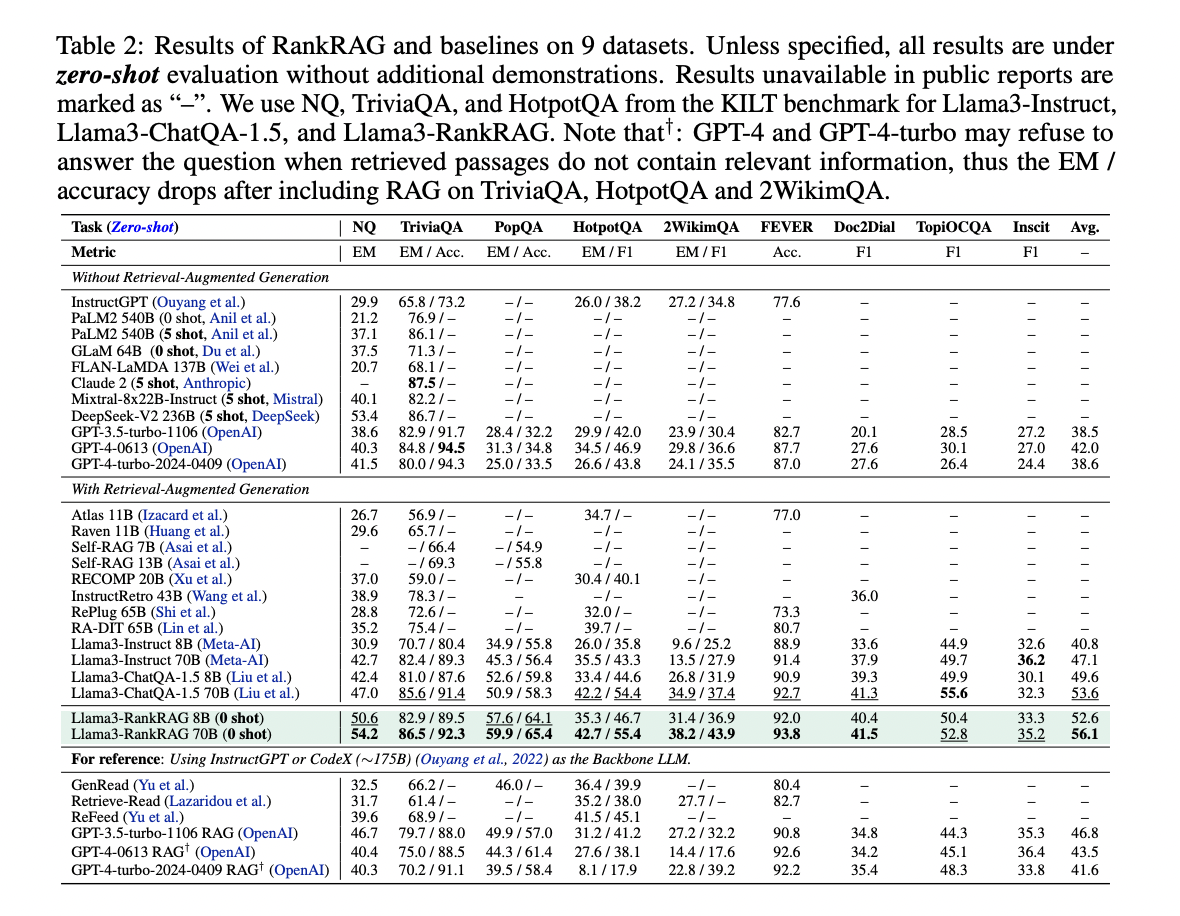
RankRAG demonstrates superior efficiency in retrieval-augmented era duties throughout numerous benchmarks. The 8B parameter model persistently outperforms ChatQA-1.5 8B and competes favorably with bigger fashions, together with these with 5-8 occasions extra parameters. RankRAG 70B surpasses the robust ChatQA-1.5 70B mannequin and considerably outperforms earlier RAG baselines utilizing InstructGPT.
RankRAG reveals extra substantial enhancements on difficult datasets, reminiscent of long-tailed QA (PopQA) and multi-hop QA (2WikimQA), with over 10% enchancment in comparison with ChatQA-1.5. These outcomes recommend that RankRAG’s context rating functionality is especially efficient in eventualities the place high retrieved paperwork are much less related to the reply, enhancing efficiency in advanced OpenQA duties.
This analysis presents RankRAG, representing a major development in RAG methods. This revolutionary framework instruction-tunes a single LLM to carry out each context rating and reply era duties concurrently. By incorporating a small quantity of rating information into the coaching mix, RankRAG allows LLMs to surpass the efficiency of present professional rating fashions. The framework’s effectiveness has been extensively validated via complete evaluations on knowledge-intensive benchmarks. RankRAG demonstrates superior efficiency throughout 9 general-domain and 5 biomedical RAG benchmarks, considerably outperforming state-of-the-art RAG fashions. This unified strategy to rating and era inside a single LLM represents a promising route for enhancing the capabilities of RAG methods in numerous domains.
Try the Paper. All credit score for this analysis goes to the researchers of this undertaking. Additionally, don’t overlook to comply with us on Twitter and be a part of our 46k+ ML SubReddit, 26k+ AI Publication, Telegram Channel, and LinkedIn Group.
If You have an interest in a promotional partnership (content material/advert/publication), please fill out this kind.
Asjad is an intern advisor at Marktechpost. He’s persuing B.Tech in mechanical engineering on the Indian Institute of Expertise, Kharagpur. Asjad is a Machine studying and deep studying fanatic who’s all the time researching the functions of machine studying in healthcare.
[ad_2]