[ad_1]
Multimodal massive language fashions (MLLMs) have develop into distinguished in synthetic intelligence (AI) analysis. They combine sensory inputs like imaginative and prescient and language to create extra complete techniques. These fashions are essential in functions akin to autonomous autos, healthcare, and interactive AI assistants, the place understanding and processing data from various sources is important. Nevertheless, a major problem in creating MLLMs is successfully integrating and processing visible information alongside textual particulars. Present fashions typically prioritize language understanding, resulting in insufficient sensory grounding and subpar efficiency in real-world situations.
Historically, visible representations in AI are evaluated utilizing benchmarks akin to ImageNet for picture classification or COCO for object detection. These strategies give attention to particular duties, and the built-in capabilities of MLLMs in combining visible and textual information have to be totally assessed. Researchers launched Cambrian-1, a vision-centric MLLM designed to reinforce the mixing of visible options with language fashions to handle the above considerations. This mannequin consists of contributions from New York College and incorporates varied imaginative and prescient encoders and a singular connector known as the Spatial Imaginative and prescient Aggregator (SVA).
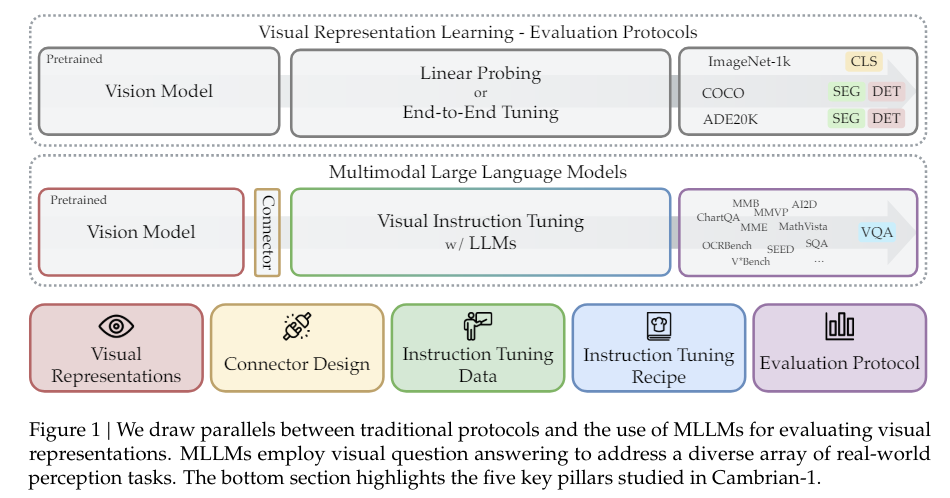
The Cambrian-1 mannequin employs the SVA to dynamically join high-resolution visible options with language fashions, lowering token depend and enhancing visible grounding. Moreover, the mannequin makes use of a newly curated visible instruction-tuning dataset, CV-Bench, which transforms conventional imaginative and prescient benchmarks into a visible question-answering format. This strategy permits for a complete analysis & coaching of visible representations inside the MLLM framework.
Cambrian-1 demonstrates state-of-the-art efficiency throughout a number of benchmarks, notably in duties requiring robust visible grounding. For instance, it makes use of over 20 imaginative and prescient encoders and critically examines present MLLM benchmarks, addressing difficulties in consolidating and decoding outcomes from varied duties. The mannequin introduces CV-Bench, a vision-centric benchmark with 2,638 manually inspected examples, considerably greater than different vision-centric MLLM benchmarks. This in depth analysis framework allows Cambrian-1 to attain high scores in visual-centric duties, outperforming present MLLMs in these areas.
Researchers additionally proposed the Spatial Imaginative and prescient Aggregator (SVA), a brand new connector design that integrates high-resolution imaginative and prescient options with LLMs whereas lowering the variety of tokens. This dynamic and spatially conscious connector preserves the spatial construction of visible information throughout aggregation, permitting for extra environment friendly processing of high-resolution photos. Cambrian-1’s potential to successfully combine and course of visible information is additional enhanced by curating high-quality visible instruction-tuning information from public sources, emphasizing the significance of knowledge supply balancing and distribution ratio.
By way of efficiency, Cambrian-1 excels in varied benchmarks, attaining notable outcomes highlighting its robust visible grounding capabilities. For example, the mannequin surpasses high efficiency throughout various benchmarks, together with these requiring processing ultra-high-resolution photos. That is achieved by using a average variety of visible tokens and avoiding methods that enhance token depend excessively, which may hinder efficiency.
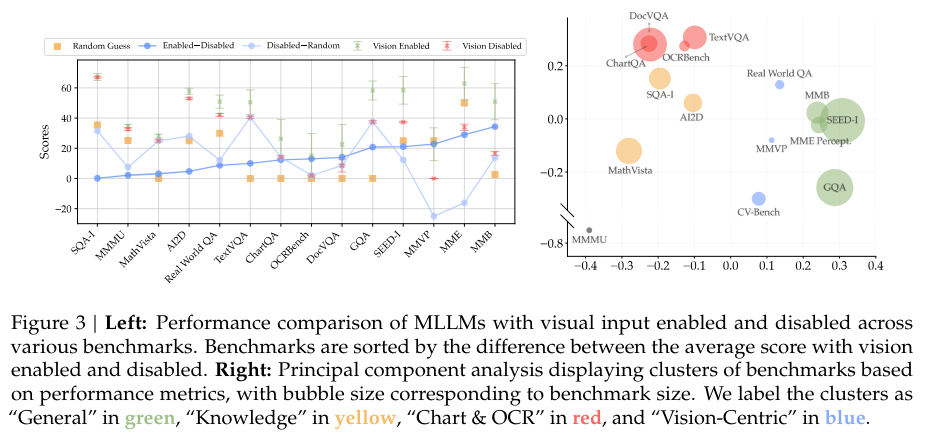
Cambrian-1 excels in benchmark efficiency and demonstrates spectacular talents in sensible functions, akin to visible intersection and instruction-following. The mannequin can deal with advanced visible duties, generate detailed and correct responses, and even comply with particular directions, showcasing its potential for real-world use. Moreover, the mannequin’s design and coaching course of rigorously balances varied information varieties and sources, making certain a sturdy and versatile efficiency throughout totally different duties.

To conclude, Cambrian-1 introduces a household of state-of-the-art MLLM fashions that obtain high efficiency throughout various benchmarks and excel in visual-centric duties. By integrating progressive strategies for connecting visible and textual information, the Cambrian-1 mannequin addresses the important situation of sensory grounding in MLLMs, providing a complete resolution that considerably improves efficiency in real-world functions. This development underscores the significance of balanced sensory grounding in AI growth and units a brand new customary for future analysis in visible illustration studying and multimodal techniques.
Try the Paper, Mission, HF Web page, and GitHub Web page. All credit score for this analysis goes to the researchers of this venture. Additionally, don’t neglect to comply with us on Twitter.
Be a part of our Telegram Channel and LinkedIn Group.
In case you like our work, you’ll love our publication..
Don’t Neglect to affix our 45k+ ML SubReddit
🚀 Create, edit, and increase tabular information with the primary compound AI system, Gretel Navigator, now typically obtainable! [Advertisement]
Asif Razzaq is the CEO of Marktechpost Media Inc.. As a visionary entrepreneur and engineer, Asif is dedicated to harnessing the potential of Synthetic Intelligence for social good. His most up-to-date endeavor is the launch of an Synthetic Intelligence Media Platform, Marktechpost, which stands out for its in-depth protection of machine studying and deep studying information that’s each technically sound and simply comprehensible by a large viewers. The platform boasts of over 2 million month-to-month views, illustrating its recognition amongst audiences.
[ad_2]