[ad_1]
In fixing real-world knowledge science issues, mannequin choice is essential. Tree ensemble fashions like XGBoost are historically favored for classification and regression for tabular knowledge. Regardless of their success, deep studying fashions have not too long ago emerged, claiming superior efficiency on sure tabular datasets. Whereas deep neural networks excel in fields like picture, audio, and textual content processing, their software to tabular knowledge presents challenges because of knowledge sparsity, blended characteristic varieties, and lack of transparency. Though new deep studying approaches for tabular knowledge have been proposed, inconsistent benchmarking and analysis make it unclear if they really outperform established fashions like XGBoost.
Researchers from the IT AI Group at Intel rigorously in contrast deep studying fashions to XGBoost for tabular knowledge to find out their efficacy. Evaluating efficiency throughout varied datasets, they discovered that XGBoost persistently outperformed deep studying fashions, even on datasets initially used to showcase the deep fashions. Moreover, XGBoost required considerably much less hyperparameter tuning. Nevertheless, combining deep fashions with XGBoost in an ensemble yielded the perfect outcomes, surpassing each standalone XGBoost and deep fashions. This research highlights that, regardless of developments in deep studying, XGBoost stays a superior and environment friendly alternative for tabular knowledge issues.
Historically, Gradient-Boosted Resolution Bushes (GBDT), like XGBoost, LightGBM, and CatBoost, dominate tabular knowledge functions because of their robust efficiency. Nevertheless, latest research have launched deep studying fashions tailor-made for tabular knowledge, resembling TabNet, NODE, DNF-Internet, and 1D-CNN, which present promise in outperforming conventional strategies. These fashions embrace differentiable timber and attention-based approaches, but GBDTs stay aggressive. Ensemble studying, combining a number of fashions, can additional improve efficiency. The researchers evaluated these deep fashions and GBDTs throughout numerous datasets, discovering that XGBoost usually excels, however combining deep fashions with XGBoost yields the perfect outcomes.
The research totally in contrast deep studying fashions and conventional algorithms like XGBoost throughout 11 various tabular datasets. The deep studying fashions examined included NODE, DNF-Internet, and TabNet, they usually have been evaluated alongside XGBoost and ensemble approaches. These datasets, chosen from outstanding repositories and Kaggle competitions, displayed a broad vary of traits by way of options, lessons, and pattern sizes. The analysis standards encompassed accuracy, effectivity in coaching and inference, and the time wanted for hyperparameter tuning. Findings revealed that XGBoost persistently outperformed the deep studying fashions on most datasets not a part of the fashions’ unique coaching units. Particularly, XGBoost achieved superior efficiency on 8 of 11 datasets, demonstrating its versatility throughout completely different domains. Conversely, deep studying fashions confirmed their finest efficiency solely on datasets they have been initially designed for, implying an inclination to overfit their preliminary coaching knowledge.
Moreover, the research examined the efficacy of mixing deep studying fashions with XGBoost in ensemble strategies. It was noticed that ensembles integrating each deep fashions and XGBoost usually yielded superior outcomes in comparison with particular person fashions or ensembles of classical machine studying fashions like SVM and CatBoost. This synergy highlights the complementary strengths of deep studying and tree-based fashions, the place deep networks seize complicated patterns, and XGBoost offers sturdy, generalized efficiency. Regardless of the computational benefits of deep fashions, XGBoost proved considerably sooner and extra environment friendly in hyperparameter optimization, converging to optimum efficiency with fewer iterations and computational assets. General, the findings underscore the necessity for cautious consideration of mannequin choice and the advantages of mixing completely different algorithmic approaches to leverage their distinctive strengths for varied tabular knowledge challenges.
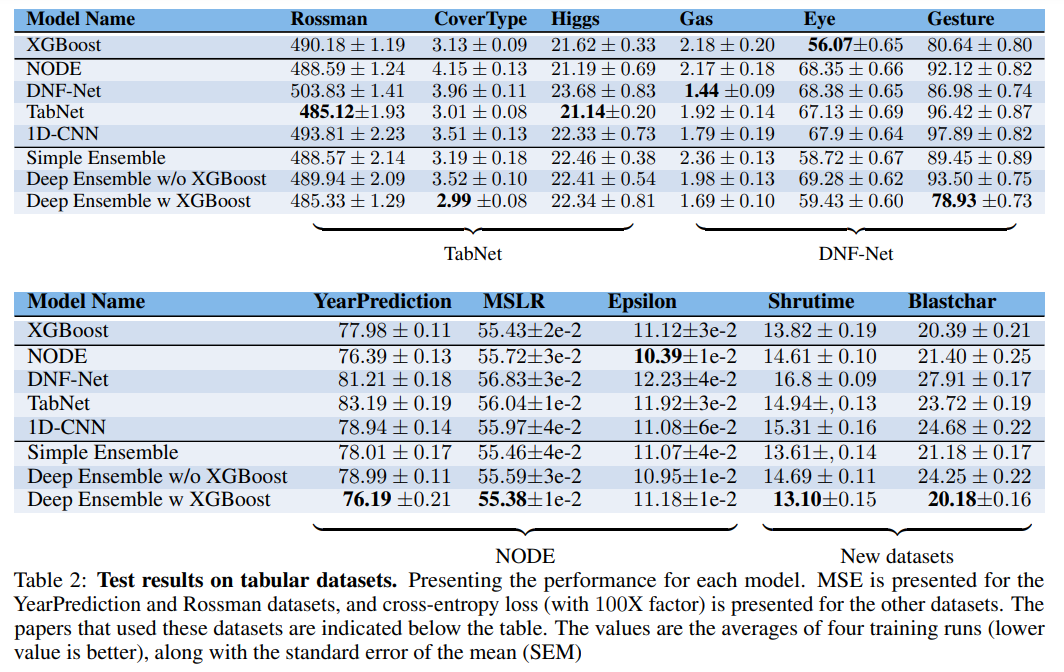
The research evaluated the efficiency of deep studying fashions on tabular datasets and located them to be usually much less efficient than XGBoost on datasets exterior their unique papers. An ensemble of deep fashions and XGBoost carried out higher than any single mannequin or classical ensemble, highlighting the strengths of mixing strategies. XGBoost was simpler to optimize and extra environment friendly, making it preferable below time constraints. Nevertheless, integrating deep fashions can improve efficiency. Future analysis ought to take a look at fashions on numerous datasets and concentrate on growing deep fashions which are simpler to optimize and might higher compete with XGBoost.
Try the Paper. All credit score for this analysis goes to the researchers of this challenge. Additionally, don’t neglect to observe us on Twitter.
Be a part of our Telegram Channel and LinkedIn Group.
If you happen to like our work, you’ll love our e-newsletter..
Don’t Neglect to hitch our 46k+ ML SubReddit
Sana Hassan, a consulting intern at Marktechpost and dual-degree scholar at IIT Madras, is keen about making use of expertise and AI to handle real-world challenges. With a eager curiosity in fixing sensible issues, he brings a contemporary perspective to the intersection of AI and real-life options.
[ad_2]