[ad_1]
Hallucinations in giant language fashions (LLMs) happen when fashions produce responses that don’t align with factual actuality or the supplied context. This drawback is difficult for LLM practitioners growing RAG functions the place LLM outputs have entry to user-provided paperwork. For instance, if LLMs getting used for monetary question-answering or medical prognosis produce responses that deviate from supply paperwork, customers are uncovered to misinformation with vital unfavourable penalties.
The LLM-as-a-judge paradigm has grown in reputation for detecting inaccuracies in generative AI utility responses, as a consequence of its flexibility and ease of use. Nonetheless, even when utilizing top-performing fashions like GPT-4, LLM-as-a-judge ceaselessly fails to judge responses to complicated reasoning duties precisely. Moreover, there are considerations in regards to the high quality, transparency and price of closed-source LMs. Nonetheless, there’s a vital hole in efficiency between open supply and closed-source fashions used for analysis duties because of the lack of difficult and domain-specific publicly obtainable datasets.
At Patronus AI, we acknowledged the necessity for an automatic LLM analysis platform to instill confidence in enterprises deploying GenAI fashions. That’s why we constructed Lynx, a SOTA hallucination detection mannequin that’s able to utilizing complicated reasoning to establish conflicting outputs. In experiments, we discovered that Lynx outperformed all current LLM-as-a-judge evaluators utilizing closed and open supply fashions. In domain-specific duties, this distinction was much more pronounced, with a 7.5% distinction in medical question-answering.
On this weblog, we describe the method of coaching a SOTA hallucination detection LM with LLM Foundry, Composer and Mosaic AI Mannequin Coaching.
Lynx-70B-Instruct is a finetuned Llama-3-70B-Instruct mannequin. (In our experiments, we finetuned a number of extra open supply fashions and present full ends in our paper.) We selected Databricks Mosaic AI instruments, together with the LLM Foundry, Composer, and coaching cluster, as a result of they supplied extra customization choices and assist for a variety of language fashions.
We first constructed our coaching and analysis datasets for a hallucination identification process utilizing a perturbation course of (see our paper for extra particulars). To create a fine-tuning job on the Databricks Mosaic AI coaching infrastructure, we create a config much like the next:
command: |
pip set up peft
cd llm-foundry/scripts
composer prepare/prepare.py /mnt/config/parameters.yaml
picture: mosaicml/llm-foundry:2.3.0_cu121_flash2-latest
title: llama-3-70B-Instruct-${experiment_name}
compute:
gpus: 32 # Variety of GPUs to make use of
parameters:
tokenizer_name: meta-llama/Meta-Llama-3-70B-Instruct
max_seq_len: 8000
global_seed: 17
# Run Identify
run_name: ${run_name}
max_split_size_mb: 512
# Mannequin
mannequin:
title: hf_causal_lm
init_device: combined
pretrained_model_name_or_path: meta-llama/Meta-Llama-3-70B-Instruct
pretrained: true
use_auth_token: true
use_flash_attention_2: true
# Tokenizer
tokenizer:
title: ${tokenizer_name}
kwargs:
model_max_length: ${max_seq_len}
loggers:
wandb: {"mission": "hallucination-finetuning", "entity":"patronusai"}
save_folder: ${save_path}We then scheduled coaching jobs utilizing the Databricks Mosaic AI CLI:
mcli run -f train_config.yamlFor supervised finetuning on 70B fashions, we educated on 32 NVIDIA H100 GPUs, for an efficient batch dimension of 256. To boost efficiency, we used native optimizations in Composer, together with FSDP and flash consideration.
To view ends in real-time, we used the WandB integration with LLM Foundry to log coaching outcomes to the WandB dashboard. The Mosaic AI Coaching console makes it simple to watch run standing, together with completion standing and job historical past from teammates.
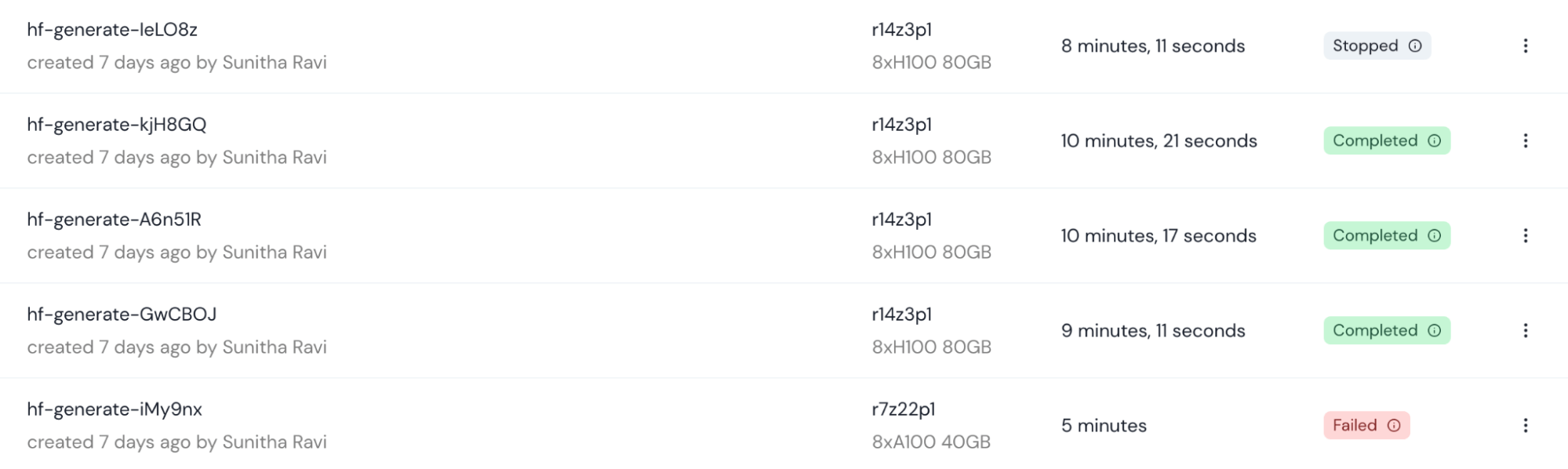
Mosaic AI’s coaching platform abstracts away the complexities of deploying coaching runs throughout a number of clusters and compute suppliers. A coaching run could be launched on a GPU cluster on one cloud supplier (e.g., AWS) and shifted to a different supplier (e.g. GCP) with no extra effort. Clusters are monitored for community and GPU faults inside the coaching console, mechanically cordoning defective {hardware} to mitigate downtime.
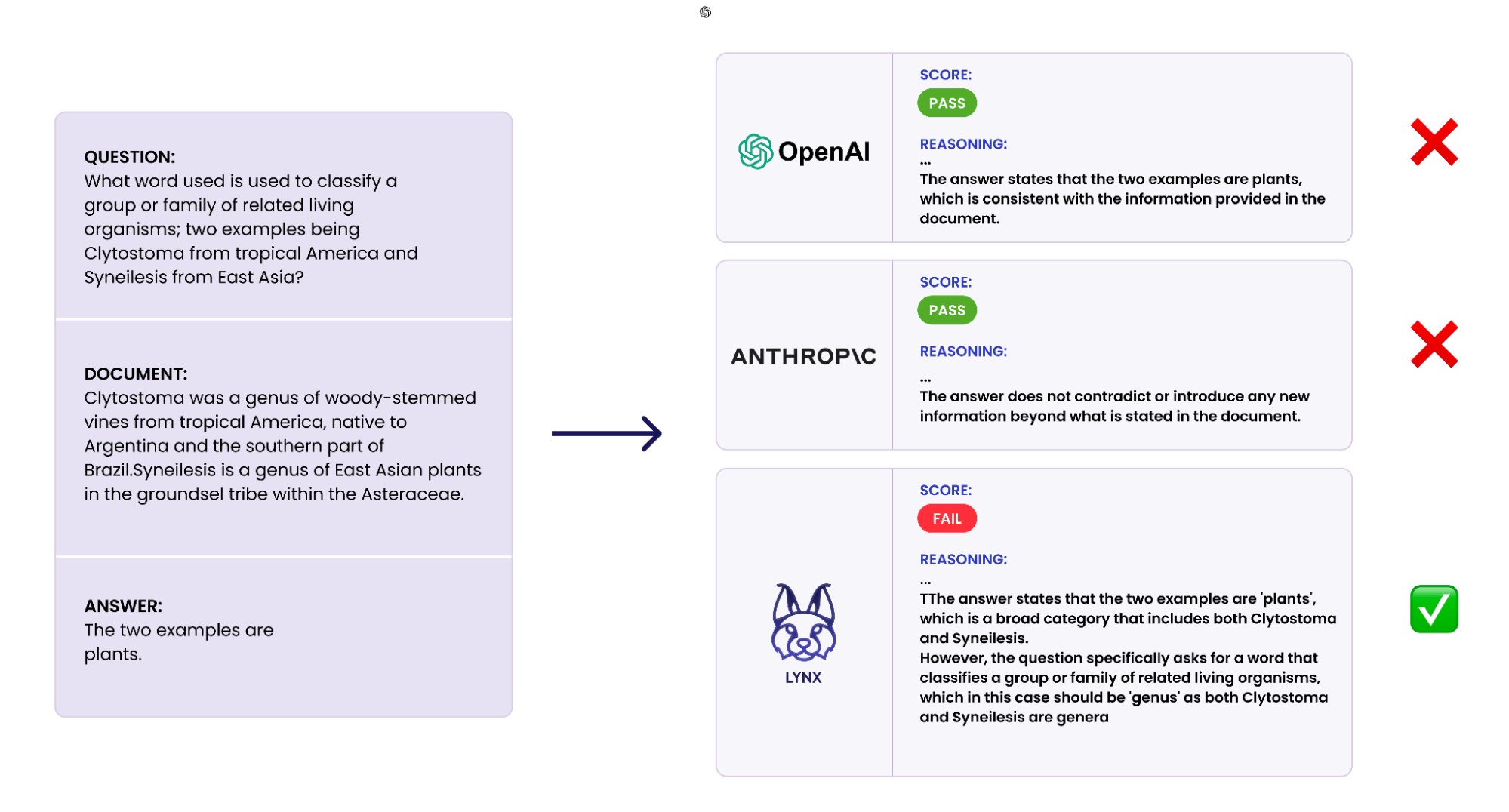
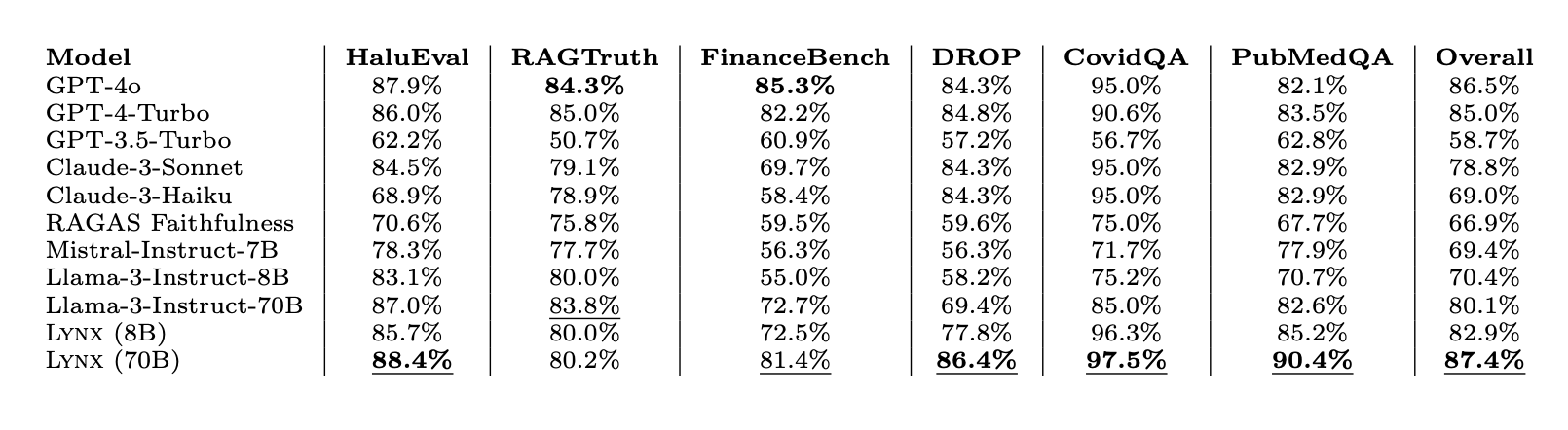
Our outcomes on HaluBench present that our finetuned mannequin outperforms closed-source LLMs and open supply LLMs when used as choose evaluator LMs throughout totally different duties. Lynx outperformed GPT-4o by virtually 1% in accuracy averaged throughout all duties, and is the best-performing open-source mannequin by a large margin.
We’re excited to open supply Lynx and HaluBench to advance analysis in RAG evaluations.
Obtain Lynx on HuggingFace:
https://huggingface.co/PatronusAI/Llama-3-Patronus-Lynx-8B-Instruct
https://huggingface.co/PatronusAI/Llama-3-Patronus-Lynx-70B-Instruct
https://huggingface.co/PatronusAI/Llama-3-Patronus-Lynx-8B-Instruct-Q4_K_M-GGUF
Obtain HaluBench on HuggingFace:
https://huggingface.co/datasets/PatronusAI/HaluBench
See a visualization of HaluBench on Nomic Atlas:
https://atlas.nomic.ai/information/patronus-ai/halubench/map
Learn the total paper:
https://arxiv.org/abs/2407.08488
[ad_2]