[ad_1]
Introduction
Many strategies have been confirmed efficient in enhancing mannequin high quality, effectivity, and useful resource consumption in Deep Studying. The excellence between fine-tuning vs full coaching vs coaching from scratch can assist you determine which method is correct to your venture. Then, we’ll overview them individually and see the place and when to make use of them, utilizing code snippets for instance their benefits and downsides.
Studying Goals:
- Perceive the variations between fine-tuning vs full coaching vs coaching from scratch in Deep Studying.
- Establish the suitable use circumstances for coaching a mannequin from scratch.
- Acknowledge when to make use of full coaching on massive, established datasets.
- Be taught the benefits and downsides of every coaching method.
- Acquire sensible data by way of instance code snippets for every coaching technique.
- Consider the useful resource necessities and efficiency implications of every method.
- Apply the appropriate coaching technique for particular Deep Studying initiatives.
What’s Coaching from Scratch?
It means constructing and coaching a brand new mannequin on the fly utilizing your dataset. Beginning with random preliminary weights and persevering with the entire coaching course of.
Use Instances
- Distinctive Information: When the dataset used is exclusive and vastly totally different from any current dataset.
- Novel Architectures: Whereas designing new mannequin architectures or attempting out new strategies.
- Analysis & Growth: That is utilized in educational analysis or for superior purposes the place fashions primarily based on each potential database are inadequate.
Execs
- Versatile: You’ll be able to absolutely management the mannequin structure and coaching course of to adapt them to your knowledge’s particularities.
- Customized Options: Relating to extremely specialised duties corresponding to these with probably no pre-trained fashions obtainable.
Instance Code
Right here’s an instance utilizing PyTorch to coach a easy neural community from scratch:
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import datasets, transforms
# Outline a easy neural community
class SimpleNN(nn.Module):
def __init__(self):
tremendous(SimpleNN, self).__init__()
self.fc1 = nn.Linear(28*28, 128)
self.fc2 = nn.Linear(128, 64)
self.fc3 = nn.Linear(64, 10)
def ahead(self, x):
x = torch.flatten(x, 1)
x = torch.relu(self.fc1(x))
x = torch.relu(self.fc2(x))
x = self.fc3(x)
return x
# Load the dataset
rework = transforms.Compose([transforms.ToTensor(), transforms.Normalize((0.5,), (0.5,))])
train_dataset = datasets.MNIST(root="./knowledge", practice=True, obtain=True, rework=rework)
train_loader = torch.utils.knowledge.DataLoader(train_dataset, batch_size=64, shuffle=True)
# Initialize the mannequin, loss perform, and optimizer
mannequin = SimpleNN()
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(mannequin.parameters(), lr=0.001)
# Coaching loop
for epoch in vary(10):
for pictures, labels in train_loader:
optimizer.zero_grad()
output = mannequin(pictures)
loss = criterion(output, labels)
loss.backward()
optimizer.step()
print(f"Epoch {epoch+1}, Loss: {loss.merchandise()}")
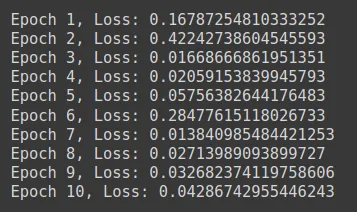
What’s Full Coaching?
Full coaching usually refers to coaching a mannequin from scratch however on a big and well-established dataset. This method is frequent for growing foundational fashions like VGG, ResNet, or GPT.
Use Instances
- Foundational Fashions: Coaching massive fashions supposed for use as pre-trained fashions for different duties.
- Benchmarking: Evaluating totally different architectures or methods on customary datasets to determine benchmarks.
- Trade Purposes: Creating strong and generalized fashions for widespread industrial use.
Benefits
- Excessive Efficiency: These fashions can obtain state-of-the-art efficiency on particular duties. They usually function the spine for a lot of purposes and are fine-tuned for specialised duties.
- Standardization: It helps set up benchmark fashions. Fashions skilled on massive, numerous datasets can generalize nicely throughout varied duties and domains.
Disadvantages
- Useful resource-demanding: It requires intensive computational energy and time. Coaching fashions like ResNet or GPT-3 contain a number of GPUs or TPUs over a number of days or perhaps weeks.
- Experience Wanted: Tuning hyperparameters and making certain correct convergence requires deep data. This contains understanding mannequin structure, knowledge preprocessing, and optimization methods.
Instance Code
Right here’s an instance utilizing TensorFlow to coach a CNN on the CIFAR-10 dataset:
import tensorflow as tf
from tensorflow.keras import datasets, layers, fashions
# Load the CIFAR-10 dataset
(train_images, train_labels), (test_images, test_labels) = datasets.cifar10.load_data()
# Normalize the photographs
train_images, test_images = train_images / 255.0, test_images / 255.0
# Outline a CNN mannequin
mannequin = fashions.Sequential([
layers.Conv2D(32, (3, 3), activation='relu', input_shape=(32, 32, 3)),
layers.MaxPooling2D((2, 2)),
layers.Conv2D(64, (3, 3), activation='relu'),
layers.MaxPooling2D((2, 2)),
layers.Conv2D(64, (3, 3), activation='relu'),
layers.Flatten(),
layers.Dense(64, activation='relu'),
layers.Dense(10)
])
# Compile the mannequin
mannequin.compile(optimizer="adam",
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=['accuracy'])
# Practice the mannequin
historical past = mannequin.match(train_images, train_labels, epochs=10,
validation_data=(test_images, test_labels))
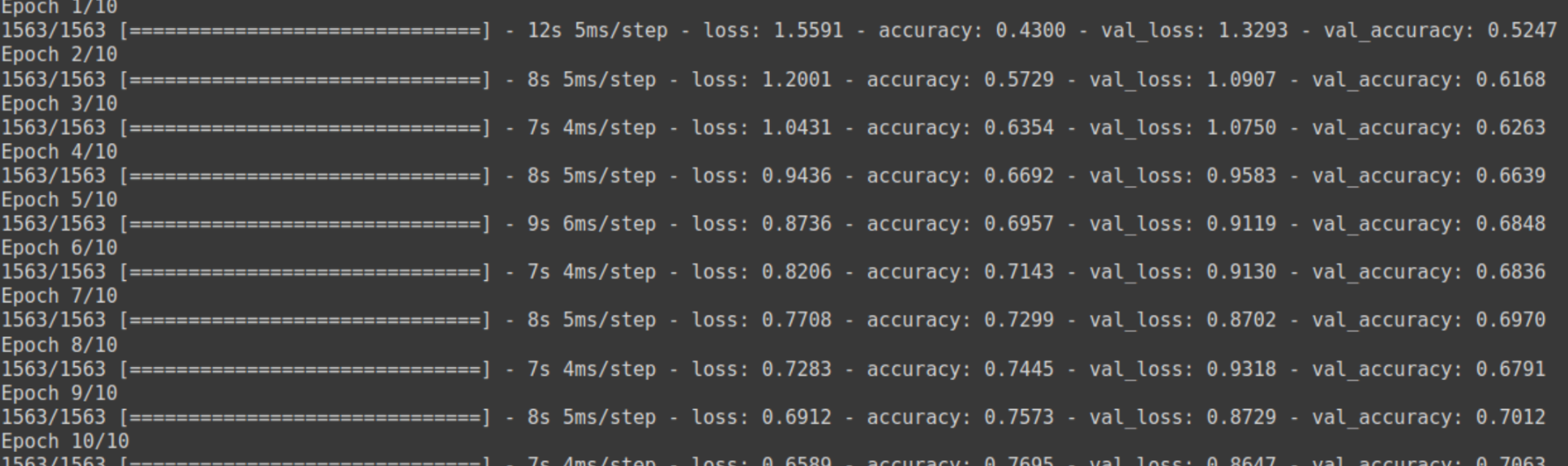
What’s Positive-Tuning?
Using a pre-trained mannequin and making minor modifications to make it appropriate for a selected process. You usually freeze the primary few layers and practice the remaining in your dataset.
Use Instances
- Switch Studying: Positive-tuning is available in in case your dataset is small or you could have restricted {hardware} sources. It makes use of the data of already pre-trained fashions.
- Area Adaptation: Turning a basic mannequin to work right into a specialised area(e.g., medical imaging and sentiment evaluation).
Advantages
- Effectivity: It consumes decrease computational energy and time. Coaching from scratch would require extra sources, however fine-tuning might be executed with fewer sources.
- Mannequin Efficiency: The mannequin performs nicely in lots of circumstances, even with little knowledge. Pre-trained layers study basic options which are helpful for many duties.
Cons
- Much less Flexibility: You don’t absolutely management the preliminary layers of the mannequin. You depend upon the structure and coaching of a pre-trained mannequin.
- Overfitting Threat: Coaching a mannequin to work with such a restricted quantity of knowledge needs to be approached with warning to keep away from overfitting the system. Overfitting might happen with fine-tuning if the brand new dataset is just too small or too just like the pre-trained knowledge.
Instance Code
Right here’s an instance utilizing Keras to fine-tune a pre-trained VGG16 mannequin on a customized dataset:
import tensorflow as tf
from tensorflow.keras.purposes import VGG16
from tensorflow.keras import layers, fashions
from tensorflow.keras.preprocessing.picture import ImageDataGenerator
# Load the pre-trained VGG16 mannequin and freeze its layers
base_model = VGG16(weights="imagenet", include_top=False, input_shape=(150, 150, 3))
for layer in base_model.layers:
layer.trainable = False
# Add customized layers on prime of the bottom mannequin
mannequin = fashions.Sequential([
base_model,
layers.Flatten(),
layers.Dense(256, activation='relu'),
layers.Dense(1, activation='sigmoid')
])
# Compile the mannequin
mannequin.compile(optimizer="adam", loss="binary_crossentropy", metrics=['accuracy'])
# Load and preprocess the dataset
train_datagen = ImageDataGenerator(rescale=0.5)
train_generator = train_datagen.flow_from_directory(
'path_to_train_data',
target_size=(150, 150),
batch_size=20,
class_mode="binary"
)
# Positive-tune the mannequin
historical past = mannequin.match(train_generator, epochs=10, steps_per_epoch=100)
Positive-Tuning vs Full Coaching vs Coaching from Scratch
| Side | Coaching from Scratch | Full Coaching | Positive-Tuning |
| Definition | Constructing and coaching a brand new mannequin from random preliminary weights. | Coaching a mannequin from scratch on a big, established dataset. | Adapting a pre-trained mannequin to a selected process by coaching some layers. |
| Use Instances | Distinctive knowledge, novel architectures, analysis & growth. | Foundational fashions, benchmarking, business purposes. | Switch studying, area adaptation, restricted knowledge or sources. |
| Benefits | Full management, customized options for particular wants. | Excessive efficiency, establishes benchmarks, strong and generalized fashions. | Environment friendly, much less resource-intensive, good efficiency with little knowledge. |
| Disadvantages | Extremely resource-demanding requires intensive computational energy and experience. | Much less flexibility and threat of overfitting with small datasets. | Excessive efficiency establishes benchmarks and strong and generalized fashions. |
Similarities Between Positive-Tuning vs Full Coaching vs Coaching from Scratch
- Machine Studying Fashions: All three strategies contain machine studying fashions for varied duties.
- Coaching Course of: Every technique includes coaching a neural community, although the information and preliminary situations might fluctuate.
- Optimization: All strategies require optimization algorithms to attenuate the loss perform.
- Efficiency Analysis: All three strategies require evaluating mannequin efficiency utilizing metrics like accuracy, loss, and so on.
Easy methods to Determine Which One is Finest for you?
1. Dataset Dimension and High quality:
- Coaching from Scratch: It’s best to have a singular, massive dataset is considerably totally different from present datasets.
- Full Coaching: That is very best when you can entry massive, well-established datasets and the sources to coach a mannequin from scratch.
- Positive-tuning: It’s appropriate for small datasets or for leveraging the data from a pre-trained mannequin.
2. Assets Obtainable:
- Coaching from Scratch: Requires substantial computational sources and time.
- Full Coaching: Extraordinarily resource-intensive, usually requiring a number of GPUs/TPUs and appreciable coaching time.
- Positive-tuning: Much less resource-intensive, might be carried out with restricted {hardware} and in much less time.
3. Mission Targets:
- Coaching from Scratch: That is for initiatives needing custom-made options and novel mannequin architectures.
- Full Coaching: That is for creating foundational fashions that can be utilized as benchmarks or for widespread purposes.
- Positive-Tuning: For domain-specific duties the place a pre-trained mannequin might be tailored to enhance efficiency.
4. Experience Stage:
- Coaching from Scratch: Requires in-depth data of machine studying, mannequin structure, and optimization methods.
- Full Coaching: Requires experience in hyperparameter tuning, mannequin structure, and intensive computational setup.
- Positive-tuning: Extra accessible for practitioners with intermediate data, leveraging pre-trained fashions to realize good efficiency with fewer sources.
Contemplating these components, you possibly can decide your deep studying venture’s most acceptable coaching technique.
Conclusion
Your particular case, knowledge availability, laptop sources, and goal efficiency affect whether or not to fine-tune, absolutely practice or practice from scratch. Coaching from scratch is versatile however requires substantial sources and enormous datasets. Full coaching on established datasets is sweet for growing fundamental fashions and benchmarking. Positive-tuning effectively makes use of pre-trained fashions and adjusts them for explicit duties with restricted knowledge.
Realizing these variations, you possibly can select the appropriate method to your machine studying venture that maximizes efficiency and useful resource utilization. Whether or not you might be developing a brand new mannequin, evaluating architectures, or modifying present ones, the appropriate coaching technique might be elementary to attaining your ambitions in machine studying.
Incessantly Requested Questions
A. Positive-tuning includes utilizing a pre-trained mannequin and barely adjusting it to a selected process. Full coaching refers to constructing a mannequin from scratch utilizing a big, well-established dataset. Coaching from scratch means constructing and coaching a brand new mannequin solely in your dataset, beginning with randomly initialized weights.
A. Coaching from scratch is good when you could have a singular dataset considerably totally different from any present dataset, are growing new mannequin architectures or experimenting with novel methods, or are conducting educational analysis or engaged on cutting-edge purposes the place present fashions are inadequate.
A. The benefits are full management over the mannequin structure and coaching course of, permitting you to tailor them to your knowledge’s particular traits. It’s appropriate for extremely specialised duties the place pre-trained fashions are unavailable.
A. Full coaching includes a mannequin from scratch utilizing a big and well-established dataset. It’s usually used to develop foundational fashions like VGG, ResNet, or GPT, benchmark totally different architectures or methods, and create strong and generalized industrial fashions.
[ad_2]