[ad_1]
As giant language fashions surpass human-level capabilities, offering correct supervision turns into more and more troublesome. Weak-to-strong studying, which makes use of a much less succesful mannequin to reinforce a stronger one, gives potential advantages however wants testing for advanced reasoning duties. This technique presently lacks environment friendly methods to forestall the stronger mannequin from imitating the weaker mannequin’s errors. As AI progresses towards Synthetic Normal Intelligence (AGI), creating superintelligent programs introduces vital challenges, notably in supervision and studying paradigms. Standard strategies counting on human oversight or superior mannequin steerage turn into insufficient as AI capabilities surpass these of their supervisors.
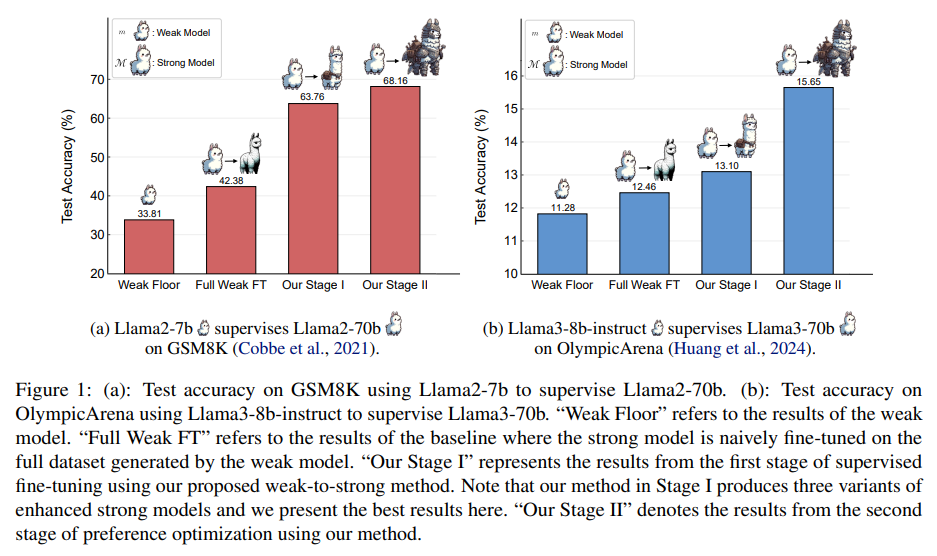
Researchers from Shanghai Jiao Tong College, Fudan College, Shanghai AI Laboratory, and GAIR have developed a progressive studying framework that enables sturdy fashions to refine their coaching information autonomously. This method begins with supervised fine-tuning on a small, high-quality dataset, adopted by choice optimization utilizing contrastive samples recognized by the sturdy mannequin. Experiments on the GSM8K and MATH datasets present vital enhancements within the reasoning talents of Llama2-70b utilizing three totally different weak fashions. The framework’s effectiveness is additional demonstrated with Llama3-8b-instruct supervising Llama3-70b on the difficult OlympicArena dataset, paving the way in which for enhanced AI reasoning methods.
LLMs improve task-solving and alignment with human directions via supervised fine-tuning (SFT), which depends on high-quality coaching information for substantial efficiency beneficial properties. This research examines the potential of studying from weak supervision. Aligning LLMs with human values additionally requires RLHF and direct choice optimization (DPO). DPO simplifies reparameterizing reward capabilities in RLHF and has numerous steady and performant variants like ORPO and SimPO. In mathematical reasoning, researchers deal with prompting methods and producing high-quality question-answer pairs for fine-tuning, considerably bettering problem-solving capabilities.
The weak-to-strong coaching technique goals to maximise the usage of weak information and improve the sturdy mannequin’s talents. In Stage I, doubtlessly constructive samples are recognized with out floor reality and used for supervised fine-tuning. Stage II entails utilizing the total weak information, specializing in doubtlessly adverse samples via choice learning-based approaches like DPO. This technique refines the sturdy mannequin by studying from the weak mannequin’s errors. The sturdy mannequin’s responses are sampled, and confidence ranges are used to find out dependable solutions. Contrastive samples are created for additional coaching, serving to the sturdy mannequin differentiate between appropriate and incorrect options, leading to an improved mannequin.
The experiments make the most of GSM8K and MATH datasets, with subsets Dgold,1, and Dgold, two used for coaching weak and powerful fashions. Preliminary coaching on GSM8K was enhanced with further information, whereas MATH information confronted limitations on account of its complexity. Iterative fine-tuning improved weak fashions, which subsequently elevated sturdy mannequin efficiency. Utilizing choice studying strategies, vital enhancements have been noticed, notably on GSM8K. Additional evaluation confirmed higher generalization on easier issues. Assessments with Llama3 fashions on OlympicArena, a more difficult dataset, demonstrated that the proposed weak-to-strong studying technique is efficient and scalable in real looking situations.
In conclusion, the research investigates the effectiveness of the weak-to-strong framework in advanced reasoning duties, presenting a technique that leverages weak supervision to develop sturdy capabilities with out human or superior mannequin annotations. The sturdy mannequin refines its coaching information independently, even with out prior activity data, progressively enhancing its reasoning expertise via iterative studying. This self-directed information curation is important for advancing AI reasoning capabilities selling mannequin independence and effectivity. The research highlights modern mannequin supervision’s function in AI growth, notably for AGI. Limitations embody utilizing present fashions as proxies for future superior fashions and the challenges posed by errors and noise in process-level supervision.
Try the Paper and GitHub. All credit score for this analysis goes to the researchers of this challenge. Additionally, don’t overlook to comply with us on Twitter and be a part of our Telegram Channel and LinkedIn Group. Should you like our work, you’ll love our e-newsletter..
Don’t Overlook to affix our 47k+ ML SubReddit
Discover Upcoming AI Webinars right here
Sana Hassan, a consulting intern at Marktechpost and dual-degree pupil at IIT Madras, is captivated with making use of expertise and AI to deal with real-world challenges. With a eager curiosity in fixing sensible issues, he brings a recent perspective to the intersection of AI and real-life options.

[ad_2]