[ad_1]
Pure language processing has significantly improved language mannequin finetuning. This course of entails refining AI fashions to carry out particular duties extra successfully by coaching them on in depth datasets. Nevertheless, creating these giant, various datasets is complicated and costly, typically requiring substantial human enter. This problem has created a niche between tutorial analysis, which usually makes use of smaller datasets, and industrial functions, which profit from huge, finely-tuned datasets.
Amongst many, one main drawback on this discipline is the reliance on human-annotated information. Manually curating datasets is labor-intensive and dear, limiting the dimensions and variety of the information that may be generated. Tutorial datasets typically comprise a whole lot or hundreds of samples, whereas industrial datasets might include tens of tens of millions. This disparity has pushed researchers to discover automated strategies for producing instruction datasets that rival the standard of these produced by human labor.
Current strategies to deal with this drawback embody utilizing giant language fashions (LLMs) to switch and increase human-written content material. Whereas these strategies have been considerably profitable, they nonetheless have to catch up relating to scalability and variety. As an example, the Flan assortment, utilized in coaching the T0 mannequin household, expanded to incorporate hundreds of duties however confronted grammatical errors and textual content high quality points. Equally, different datasets like Evol-Instruct and UltraChat contain subtle augmentation processes that require human oversight.
Researchers from the College of Maryland have proposed an modern answer to this drawback by introducing GenQA. This methodology leverages a single, well-crafted immediate to autonomously generate tens of millions of various instruction examples. GenQA goals to create large-scale and extremely various datasets by minimizing human intervention. The analysis crew used LLMs to develop quite a lot of instruction examples, starting from easy duties to complicated multi-turn dialogs throughout quite a few topic areas.
The core know-how behind GenQA entails utilizing generator prompts to boost the randomness and variety of the outputs produced by LLMs. A single hand-written meta-prompt can extract tens of millions of various questions from an LLM. This method considerably reduces the necessity for human oversight. For instance, one experiment generated over 11 million questions throughout 9 completely different splits, every tailor-made to particular domains akin to lecturers, arithmetic, and dialogue. These questions had been generated utilizing a number of prompts that boosted the randomness of the LLM outputs, leading to a various set of instruction examples.
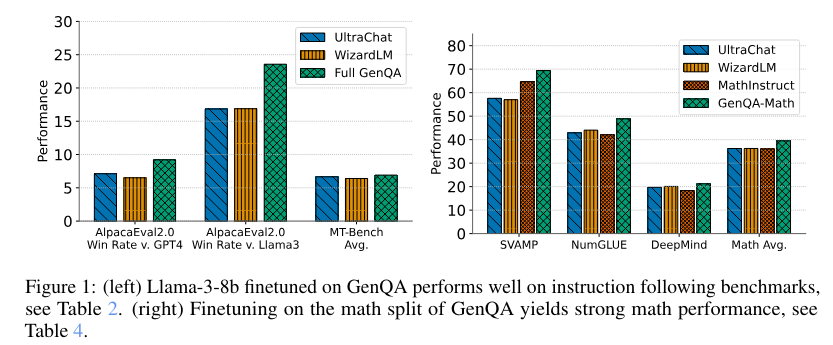
Relating to efficiency, the researchers examined the GenQA dataset by finetuning a Llama-3 8B base mannequin. The outcomes had been spectacular, with the mannequin’s efficiency on knowledge-intensive and conversational benchmarks assembly or exceeding that of datasets like WizardLM and UltraChat. Particularly, the Llama-3-8B finetuned on GenQA carried out exceptionally properly on instruction-following benchmarks and mathematical reasoning duties. As an example, on the MT-Bench, GenQA achieved a mean rating of seven.55, outperforming each WizardLM and UltraChat.
The detailed evaluation revealed that GenQA’s generator prompts led to excessive variety within the generated questions and solutions. For instance, the similarity scores of nearest neighbors had been considerably decrease for GenQA than static prompts, indicating the next stage of uniqueness. The dataset additionally included numerous splits, akin to 4,210,076 questions within the tutorial area and 515,509 math questions, showcasing its large applicability.

In conclusion, with the introduction of GenQA by automating the dataset creation course of, the researchers have demonstrated that producing large-scale, various datasets with minimal human intervention is feasible. This method reduces prices and bridges the hole between tutorial and industrial practices. The success of GenQA in finetuning a Llama-3 8B mannequin underscores its potential to rework AI analysis and functions.
Take a look at the Paper and Dataset. All credit score for this analysis goes to the researchers of this challenge. Additionally, don’t overlook to observe us on Twitter.
Be part of our Telegram Channel and LinkedIn Group.
In case you like our work, you’ll love our e-newsletter..
Don’t Overlook to affix our 45k+ ML SubReddit
Asif Razzaq is the CEO of Marktechpost Media Inc.. As a visionary entrepreneur and engineer, Asif is dedicated to harnessing the potential of Synthetic Intelligence for social good. His most up-to-date endeavor is the launch of an Synthetic Intelligence Media Platform, Marktechpost, which stands out for its in-depth protection of machine studying and deep studying information that’s each technically sound and simply comprehensible by a large viewers. The platform boasts of over 2 million month-to-month views, illustrating its reputation amongst audiences.
[ad_2]