[ad_1]
Neural networks, regardless of their theoretical functionality to suit coaching units with as many samples as they’ve parameters, typically fall brief in observe as a result of limitations in coaching procedures. This hole between theoretical potential and sensible efficiency poses important challenges for purposes requiring exact information becoming, equivalent to medical prognosis, autonomous driving, and large-scale language fashions. Understanding and overcoming these limitations is essential for advancing AI analysis and bettering the effectivity and effectiveness of neural networks in real-world duties.
Present strategies to deal with neural community flexibility contain overparameterization, convolutional architectures, varied optimizers, and activation features like ReLU. Nonetheless, these strategies have notable limitations. Overparameterized fashions, though theoretically able to common perform approximation, typically fail to succeed in optimum minima in observe as a result of limitations in coaching algorithms. Convolutional networks, whereas extra parameter-efficient than MLPs and ViTs, don’t absolutely leverage their potential on randomly labeled information. Optimizers like SGD and Adam are historically thought to regularise, however they could truly prohibit the community’s capability to suit information. Moreover, activation features designed to forestall vanishing and exploding gradients inadvertently restrict data-fitting capabilities.
A workforce of researchers from New York College, the College of Maryland, and Capital One proposes a complete empirical examination of neural networks’ data-fitting capability utilizing the Efficient Mannequin Complexity (EMC) metric. This novel strategy measures the biggest pattern dimension a mannequin can completely match, contemplating sensible coaching loops and varied information sorts. By systematically evaluating the results of architectures, optimizers, and activation features, the proposed strategies provide a brand new understanding of neural community flexibility. The innovation lies within the empirical strategy to measuring capability and figuring out elements that actually affect information becoming, thus offering insights past theoretical approximation bounds.
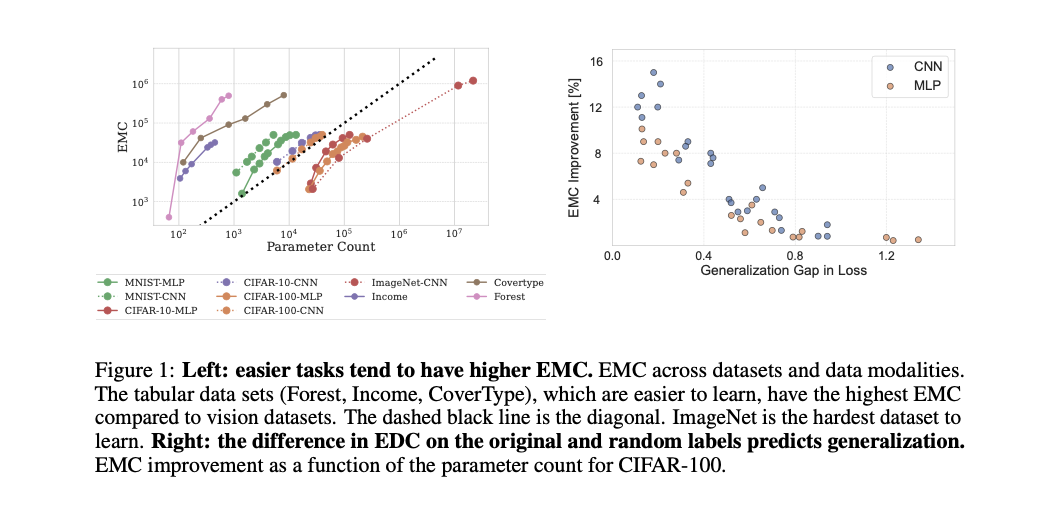
The EMC metric is calculated by way of an iterative strategy, beginning with a small coaching set and incrementally rising it till the mannequin fails to attain 100% coaching accuracy. This technique is utilized throughout a number of datasets, together with MNIST, CIFAR-10, CIFAR-100, and ImageNet, in addition to tabular datasets like Forest Cowl Kind and Grownup Earnings. Key technical elements embrace the usage of varied neural community architectures (MLPs, CNNs, ViTs) and optimizers (SGD, Adam, AdamW, Shampoo). The research ensures that every coaching run reaches a minimal of the loss perform by checking gradient norms, coaching loss stability, and the absence of damaging eigenvalues within the loss Hessian.
The research reveals important insights: normal optimizers restrict data-fitting capability, whereas CNNs are extra parameter-efficient even on random information. ReLU activation features allow higher information becoming in comparison with sigmoidal activations. Convolutional networks (CNNs) demonstrated a superior capability to suit coaching information over multi-layer perceptrons (MLPs) and Imaginative and prescient Transformers (ViTs), significantly on datasets with semantically coherent labels. Moreover, CNNs educated with stochastic gradient descent (SGD) match extra coaching samples than these educated with full-batch gradient descent, and this capability was predictive of higher generalization. The effectiveness of CNNs was particularly evident of their capability to suit extra accurately labeled samples in comparison with incorrectly labeled ones, which is indicative of their generalization functionality.
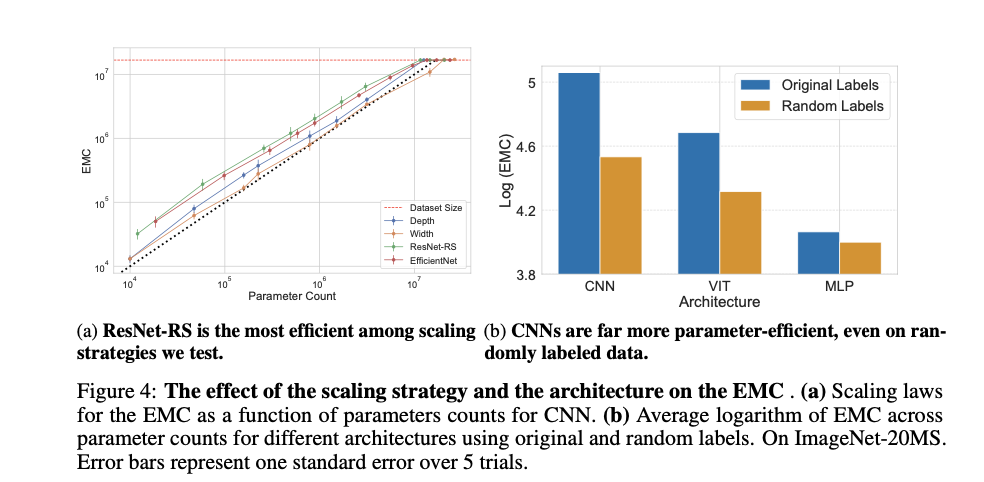
In conclusion, the proposed strategies present a complete empirical analysis of neural community flexibility, difficult standard knowledge on their data-fitting capability. The research introduces the EMC metric to measure sensible capability, revealing that CNNs are extra parameter-efficient than beforehand thought and that optimizers and activation features considerably affect information becoming. These insights have substantial implications for bettering neural community coaching and structure design, advancing the sector by addressing a vital problem in AI analysis.
Take a look at the Paper. All credit score for this analysis goes to the researchers of this mission. Additionally, don’t overlook to comply with us on Twitter.
Be a part of our Telegram Channel and LinkedIn Group.
When you like our work, you’ll love our publication..
Don’t Neglect to affix our 45k+ ML SubReddit
Aswin AK is a consulting intern at MarkTechPost. He’s pursuing his Twin Diploma on the Indian Institute of Know-how, Kharagpur. He’s enthusiastic about information science and machine studying, bringing a robust educational background and hands-on expertise in fixing real-life cross-domain challenges.
[ad_2]