[ad_1]
The world is transferring from batch to real-time. With Confluent’s latest IPO, streaming knowledge has formally gone mainstream, “turning into the underpinning of a contemporary digital buyer expertise, and the important thing to driving clever, environment friendly operations” to cite from their letter to shareholders. However whereas it’s simpler to stream the information, analyzing it in actual time nonetheless includes an excessive amount of value and complexity. Batch processes merely don’t reduce it. Creating and sustaining real-time knowledge pipelines is simply too laborious, and even probably the most superior cloud warehouses are too gradual and costly for real-time analytics.
Actual-time analytics databases are constructed from the bottom up for quick queries on recent knowledge, making real-time knowledge pipelines simpler, regardless of the supply. They’re a vital a part of the trendy knowledge stack for powering:
- Actual-time search functions
- Social options within the product
- Suggestion/rewards options within the product
- Actual-time dashboards
- IoT functions
These use instances can have a number of TBs per day streaming in – they’re actually knowledge torrents. It’s just too costly to retailer all of the uncooked knowledge and just too gradual to run batch processes to pre-aggregate it. One widespread instance is a cellular app, the place each exercise is recorded as an occasion, leading to tens of millions of occasions per day streaming in. When you retailer each occasion, your storage footprint grows at an alarming price and queries grow to be prohibitively gradual and costly. As an alternative, in case you can “rollup” knowledge as it’s being generated, then you’ll be able to outline metrics that may be tracked in actual time throughout numerous dimensions with higher efficiency and decrease value.
Rollups for Extra Price-Efficient Actual-Time Analytics
To raised serve these streaming knowledge use instances, Rockset is introducing rollups, permitting customers to mixture knowledge as it’s ingested. This significantly reduces each the quantity of knowledge saved and the compute for queries.
Early customers of rollups have skilled a 30-100x efficiency enchancment whereas additionally decreasing the price of storage considerably. Relying upon the granularity of the rollups, storage wants will be decreased 5-150x.
With this launch, Rockset customers have the aptitude to constantly mixture and rework knowledge on the time of ingest, utilizing SQL, from any knowledge supply (knowledge streams, databases and knowledge lakes). It is a first within the business and frees customers from managing gradual, costly ETL pipelines for his or her streaming knowledge.
For instance, contemplate a fee processor, who’s processing tens of millions of funds between hundreds of retailers and tens of millions of consumers. They should monitor all these transactions in actual time and run superior statistical fashions to search for anomalies and detect suspicious exercise. These statistical fashions usually construct a baseline primarily based on mixture knowledge they get from a service provider. Storing the uncooked transaction knowledge and recalculating the metrics for each transaction will probably be prohibitively costly. Utilizing Rockset’s rollup performance, the fee processor is ready outline all of the merchant-specific mixture metrics merely utilizing SQL. Rockset will robotically keep all these metrics for every service provider in real-time at a fraction of the fee, and people metrics will probably be correct as much as the final second. Since these metrics are pre-calculated and refreshed robotically, they will now implement real-time monitoring and anomaly detection to higher safe their enterprise.
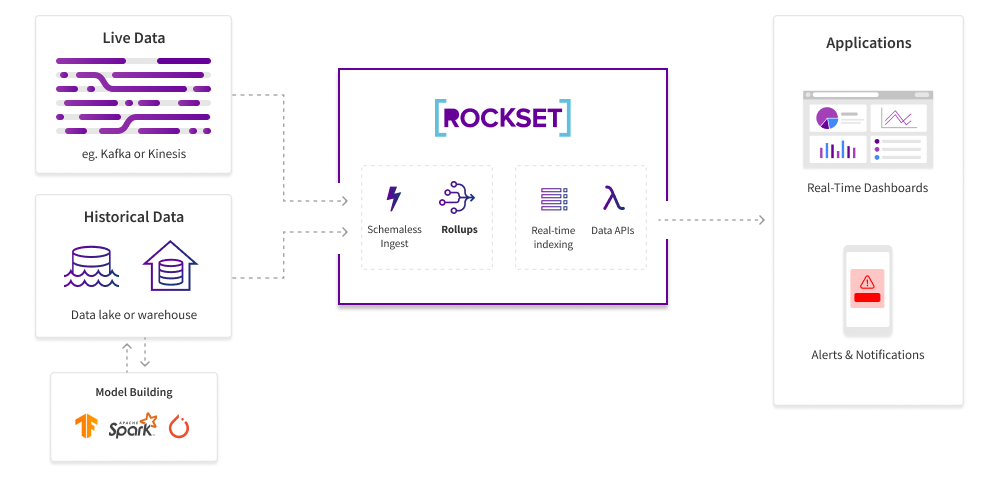
Determine 1: A pattern structure utilizing rollups for streaming knowledge
Steady Rollups and Transformations on Any Information
Rockset helps rollups and transformations not only for streaming knowledge but in addition for knowledge from different sources, like databases and knowledge lakes. Rockset can ingest all the information related for real-time functions, together with transaction or stock knowledge from databases, and supply low-latency entry to that knowledge in an economical method. Different real-time analytics methods, like Apache Druid, don’t assist OLTP databases as knowledge sources.
Rollups and Transformations Utilizing SQL
Customers specify aggregations and transformations all in SQL, a well-known language to most builders. Whereas Druid requires separate rollup and rework specs that may run into 100s of strains, customers can do that extra naturally with SQL in Rockset.

Determine 2: An instance rollup utilizing SQL
Function-Wealthy Aggregations
Rockset helps wider aggregation capabilities past merely time-based aggregations. Prospects can mixture knowledge primarily based on time, customer-id, location and every other standards, which isn’t potential in Druid. That is extraordinarily highly effective for customers creating new real-time options/functionalities of their product as a result of they will use their knowledge extra flexibly.
An instance rollup that’s not time-based:
SELECT
SUM(fare_amount) AS total_fare_amount,
passenger_count,
payment_type
FROM _input
GROUP BY passenger_count, payment_type
Good Rollups for Streaming Information
Past supporting exactly-once semantics, Rockset ensures excellent rollups for all sources, together with streaming knowledge sources. In distinction, Druid helps excellent rollup for batch knowledge, like Hadoop, and solely helps best-effort rollup for streaming knowledge. Finest-effort rollups result in inconsistent outcomes for out-of-band knowledge. Rockset is the one platform to assist excellent rollups for real-time streaming knowledge.
Virtually talking, which means when streaming knowledge is rolled up by time, Rockset doesn’t require the information to be ingested within the order wherein it was generated. That is particularly necessary for streaming knowledge sources as there’s usually a must backfill with late-arriving knowledge. Rockset is the one platform that ensures that rolled-up statistics are appropriately up to date even when knowledge is obtained out of order.
Take a look at our interview with Rockset Chief Architect Tudor Bosman to be taught extra concerning the motivation and design behind rollups in Rockset:
Embedded content material: https://youtu.be/bu5MRzd8d-0
Rockset vs Druid for Actual-Time Rollups
Now that we’ve listed some key performance above, it might be useful to check Rockset’s trendy rollup functionality to that supplied by Apache Druid, an earlier choice for real-time analytics on streaming knowledge.
By way of knowledge sources, Druid helps ingestion from streaming and batch sources, like Hadoop. Assist for database change streams is notably absent. Rockset, however, will ingest and rollup knowledge from operational databases as properly.
Whereas Rockset permits rollups and transformations to be laid out in SQL, Druid has separate ingestion specs for these. Given the better expressivity of SQL, there’s extra flexibility within the forms of aggregations customers can do in Rockset. In distinction, Druid solely does time-based aggregations, which limits the use instances to which they are often utilized. As well as, Druid solely helps best-effort rollup for streaming sources, which gives a weaker assure on the accuracy of outcomes.

Determine 3: A comparability of rollups in Rockset vs Apache Druid
Rockset Provides Actual Time To the Trendy Information Stack
By being the primary to permit ingest-time rollups and transformations from any knowledge supply, utilizing SQL, Rockset gives the pliability organizations want in a contemporary real-time knowledge stack. However apart from the most recent rollup performance, there’s a checklist of different the explanation why Rockset is the best choice for contemporary knowledge functions.
-
Simplicity. Rockset doesn’t require a military of infra or knowledge ops, efficiency engineers or consultants to make use of.
- No servers or clusters to handle: Rockset is a completely managed serverless database, with no capability planning, provisioning and scaling to fret about. Druid, whether or not within the cloud or not, nonetheless employs a datacenter-era structure rooted in servers and clusters, requiring time, effort and experience to configure and function.
- No knowledge pre-processing: Information in Druid must be flattened and denormalized earlier than ingest. Rockset can ingest knowledge with out the necessity for flattening, denormalization or perhaps a schema, saving a lot of knowledge engineering complexity.
-
Effectivity. Rockset’s cloud-native structure permits probably the most environment friendly use of compute and storage sources.
- Scale compute and storage independently: Cloud storage and compute scale independently of one another. In distinction, Druid’s structure is tightly coupled, so storage and compute should be scaled in lockstep.
- Make the most of sources totally: Due to Druid’s tightly coupled storage and compute, solely the compute related to the information to be processed can be utilized, whereas the remainder of the compute is idle. Not like Druid, Rockset is ready to make the most of all of its compute sources always.
-
Constructed for builders. Rockset makes it simple for builders to construct functions on real-time knowledge within the quickest time potential.
- Native SQL: Builders can use commonplace SQL for queries in addition to for ingest-time rollups and transformations. This enables organizations to leverage their present experience and SQL ecosystem.
- Question Lambdas: Rockset permits builders to create knowledge APIs merely from Question Lambdas–SQL queries saved in Rockset and executed by means of a REST endpoint.

Increasing the Attain of Actual-Time Analytics with Rockset
Rockset’s underlying converged indexing know-how permits it to take advantage of cloud economics to ship quick, versatile real-time analytics with none operational overhead. The output from rollups feeds into Rockset’s Converged Index to make real-time analytics on large-scale streaming knowledge extra reasonably priced and accessible.
If you wish to expertise Rockset hands-on and higher perceive the way it compares to Druid and different options, you’ll be able to check drive Rockset in your knowledge and queries with a two week free trial and $300 in free credit right here.
[ad_2]