[ad_1]
Massive Language Fashions (LLMs) have demonstrated outstanding proficiency in language technology duties. Nonetheless, their coaching course of, which includes unsupervised studying from intensive datasets adopted by supervised fine-tuning, presents important challenges. The first concern stems from the character of pre-training datasets, comparable to Widespread Crawl, which regularly comprise undesirable content material. Consequently, LLMs inadvertently purchase the power to generate offensive language and doubtlessly dangerous recommendation. This unintended functionality poses a critical security danger, as these fashions can produce coherent responses to person inputs with out correct content material filtering. The problem for researchers lies in creating strategies to keep up the LLMs’ language technology capabilities whereas successfully mitigating the manufacturing of unsafe or unethical content material.
Current makes an attempt to beat the protection considerations in LLMs have primarily centered on two approaches: security tuning and the implementation of guardrails. Security tuning goals to optimize fashions to reply in a fashion aligned with human values and security issues. Nonetheless, these chat fashions stay susceptible to jailbreak assaults, which make use of numerous methods to avoid security measures. These methods embody utilizing low-resource languages, refusal suppression, privilege escalation, and distractions.
To counter these vulnerabilities, researchers have developed guardrails to watch exchanges between chat fashions and customers. One notable method includes using model-based guardrails, that are separate from the chat fashions themselves. These guard fashions are designed to flag dangerous content material and function a essential part of AI security stacks in deployed techniques.
Nonetheless, the present strategies face important challenges. Using separate guard fashions introduces substantial computational overhead, making them impractical in low-resource settings. Additionally, the training course of is inefficient because of the appreciable overlap in language understanding talents between chat fashions and guard fashions, as each have to carry out their respective duties of response technology and content material moderation successfully.
Samsung R&D Institute researchers current LoRA-Guard, an revolutionary system that integrates chat and guard fashions, addressing effectivity points in LLM security. It makes use of a low-rank adapter on a chat mannequin’s transformer spine to detect dangerous content material. The system operates in twin modes: activating LoRA parameters for guardrailing with a classification head, and deactivating them for regular chat capabilities. This method considerably reduces parameter overhead by 100-1000x in comparison with earlier strategies, making deployment possible in resource-constrained settings. LoRA-Guard has been evaluated on numerous datasets, together with zero-shot eventualities, and its mannequin weights have been revealed to help additional analysis.
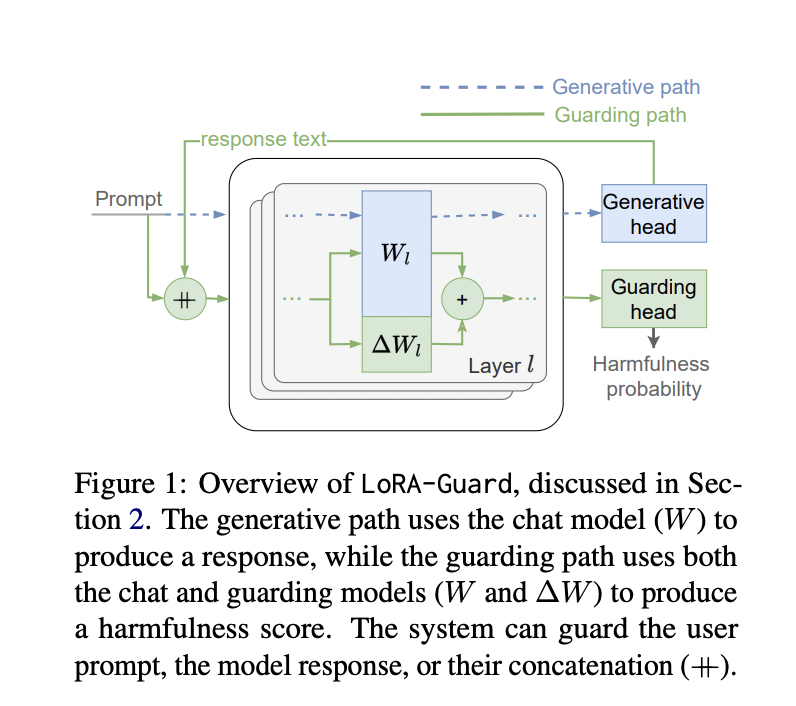
LoRA-Guard’s structure is designed to effectively combine guarding capabilities right into a chat mannequin. It makes use of the identical embedding and tokenizer for each the chat mannequin C and the guard mannequin G. The important thing innovation lies within the function map: whereas C makes use of the unique function map f, G employs f’ with LoRA adapters connected to f. G additionally makes use of a separate output head hguard for classification into harmfulness classes.
This dual-path design permits for seamless switching between chat and guard capabilities. By activating or deactivating LoRA adapters and switching between output heads, the system can carry out both activity with out efficiency degradation. The parameter sharing between paths considerably reduces the computational overhead, with the guard mannequin usually including solely a fraction (usually 1/a thousandth) of the unique mannequin’s parameters.
LoRA-Guard is skilled by means of supervised fine-tuning of f’ and hguard on labeled datasets, maintaining the chat mannequin’s parameters frozen. This method makes use of the chat mannequin’s current information whereas studying to detect dangerous content material effectively.
LoRA-Guard demonstrates distinctive efficiency on a number of datasets. On ToxicChat, it outperforms baselines in AUPRC whereas utilizing considerably fewer parameters – as much as 1500 instances lower than absolutely fine-tuned fashions. For OpenAIModEval, it matches various strategies with 100 instances fewer parameters. Cross-domain evaluations reveal attention-grabbing asymmetries: fashions skilled on ToxicChat generalize properly to OpenAIModEval, however the reverse exhibits appreciable efficiency drops. This asymmetry is perhaps because of variations in dataset traits or the presence of jailbreak samples in ToxicChat. General, LoRA-Guard proves to be an environment friendly and efficient answer for content material moderation in language fashions.
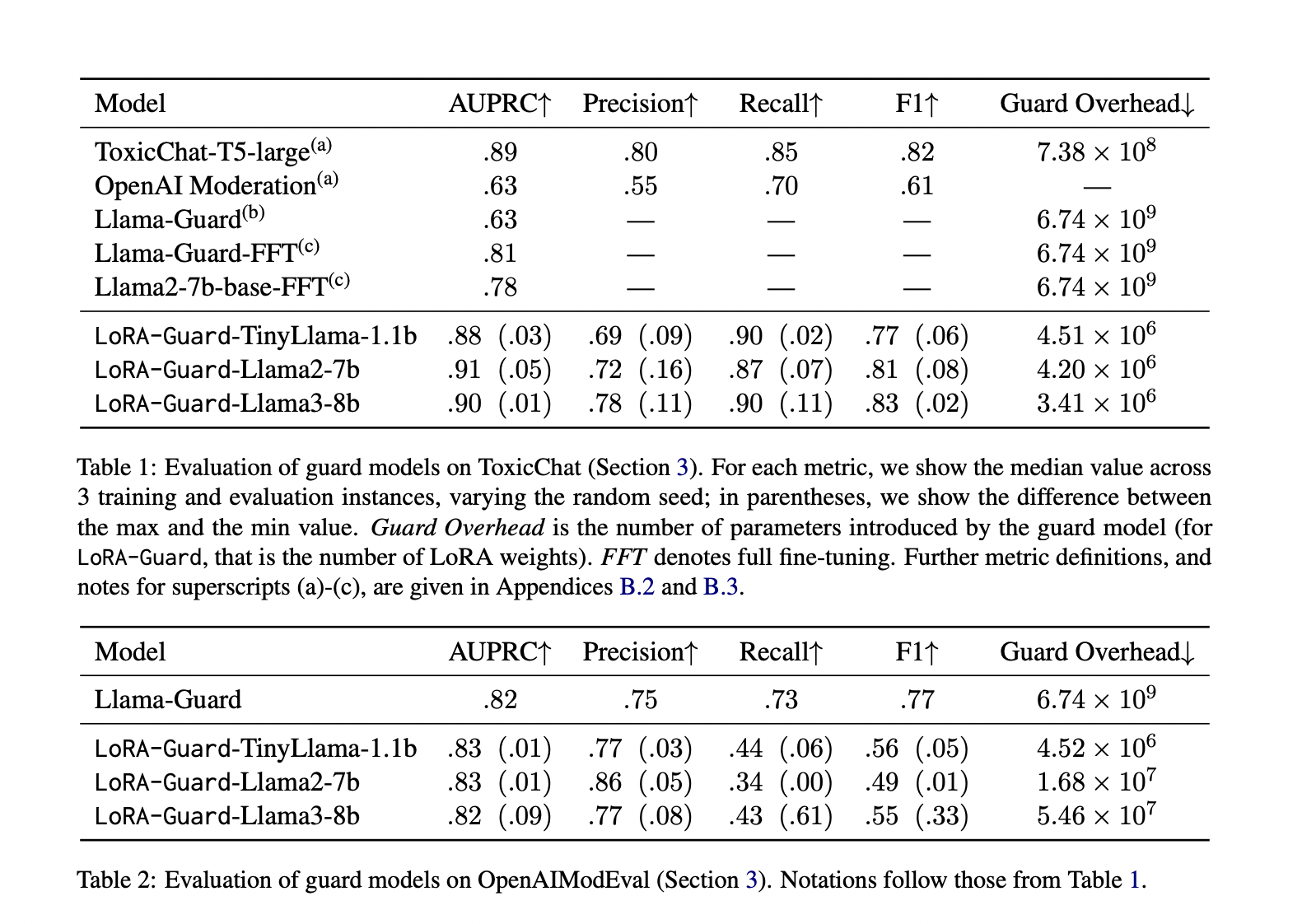
LoRA-Guard represents a big leap in moderated conversational techniques, decreasing guardrailing parameter overhead by 100-1000 instances whereas sustaining or bettering efficiency. This effectivity is achieved by means of information sharing and parameter-efficient studying mechanisms. Its dual-path design prevents catastrophic forgetting throughout fine-tuning, a typical subject in different approaches. By dramatically decreasing coaching time, inference time, and reminiscence necessities, LoRA-Guard emerges as a vital growth for implementing sturdy content material moderation in resource-constrained environments. As on-device LLMs change into extra prevalent, LoRA-Guard paves the way in which for safer AI interactions throughout a broader vary of purposes and units.
Try the Paper. All credit score for this analysis goes to the researchers of this venture. Additionally, don’t overlook to observe us on Twitter.
Be a part of our Telegram Channel and LinkedIn Group.
For those who like our work, you’ll love our publication..
Don’t Neglect to affix our 46k+ ML SubReddit
Asjad is an intern advisor at Marktechpost. He’s persuing B.Tech in mechanical engineering on the Indian Institute of Know-how, Kharagpur. Asjad is a Machine studying and deep studying fanatic who’s at all times researching the purposes of machine studying in healthcare.
[ad_2]