[ad_1]
Within the insurance coverage sector, clients demand customized, quick, and environment friendly service that addresses their wants. In the meantime, insurance coverage brokers should entry a considerable amount of documentation from a number of places and in several codecs. To enhance customer support and agent productiveness, Santalucía Seguros, a Spanish firm that has supported households for over 100 years, carried out a GenAI-based Digital Assistant (VA) able to supporting brokers’ queries about merchandise, coverages, procedures and extra.
The VA is accessed inside Microsoft Groups and is ready to reply agent questions in pure language on any cell system, pill, or pc, in real-time, with 24/7 availability. This entry makes insurance coverage brokers’ every day work a lot simpler. For instance, each time a buyer asks about protection they will get a solution in seconds. The velocity of the response not solely positively impacts buyer satisfaction, it accelerates the sale of merchandise by offering fast and correct solutions.
The answer structure is predicated on a Retrieval Augmented Era (RAG) framework working on Santalucía’s Superior Analytics Platform that’s powered by Databricks and Microsoft Azure, providing flexibility, privateness, safety, and scalability. This structure permits the continual ingestion of up-to-date documentation into embedding-based vector shops, which offer the flexibility to index data for speedy search and retrieval. The RAG system is ready up as a pyfunc mannequin in MLflow, an open supply LLMOps resolution from Databricks. We additionally used Databricks Mosaic AI Mannequin Serving endpoints to host all LLM fashions for queries.
It may be difficult to help the continual supply of latest releases whereas sustaining good LLMOps practices and response high quality, because it requires the seamless integration of newly ingested paperwork into the RAG system. Guaranteeing the standard of responses is essential for our enterprise, and we can not afford to change any a part of the answer’s code with out guaranteeing that it’ll not negatively affect the standard of beforehand delivered releases. This requires thorough testing and validation processes to maintain our solutions correct and dependable. We relied on the RAG instruments out there within the Databricks Knowledge Intelligence Platform to make sure our releases all the time have the most recent knowledge, with governance and guardrails round their output.
Subsequent, we’ll delve into the essential parts important for the profitable growth of a GenAI-based Digital Assistant that’s high-quality, scalable, and sustainable. These parts have made it simpler to develop, deploy, consider, monitor, and ship the answer. Listed below are two of a very powerful ones.
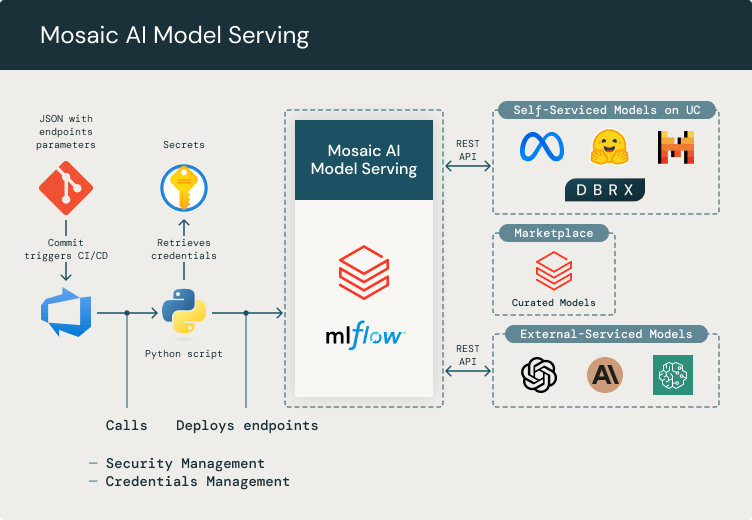
Mosaic AI Mannequin Serving
Mosaic AI Mannequin Serving makes it simple to combine exterior LLMs, similar to GPT-4 or different fashions out there within the Databricks Market, into our platform. Mosaic AI Mannequin Serving manages the configuration, credentials, and permissions of those third-party fashions, permitting entry to them by way of REST API. This ensures that any software or service will use it in a unified method, and offers an summary layer that makes it simple for growth groups so as to add new fashions, eliminating the necessity for third-party API integrations. Mannequin Serving is essential for us because it permits the administration of token consumption, credentials, and safety entry. We have now constructed a simple technique for creating and deploying new endpoints upon request, utilizing a easy git repository with a CI/CD course of that deploys the endpoint within the applicable Databricks workspace.
Builders can work together with LLM fashions (for instance, exterior providers like Azure OpenAI API or some other third-party mannequin, self-hosted that may be deployed from the Databricks Market) not directly by way of a Databricks endpoint. We deploy new fashions on our platform by way of a git repository, the place we outline a configuration JSON to parameterize credentials and endpoints. We hold these credentials protected in an Azure Key vault and use MLflow to deploy fashions in Databricks with CI/CD pipelines for mannequin serving.
LLM as a decide for analysis earlier than new releases
Evaluating the standard of the RAG responses is essential for Santalucía. Every time we ingest new paperwork into the VA, we should overview the assistant’s efficiency earlier than releasing the up to date model. This implies we can not watch for customers to judge the standard of the responses; as an alternative, the system itself should be capable to assess the standard earlier than scaling to manufacturing.
Our proposed resolution makes use of a high-capacity LLM as a decide inside the CI/CD pipeline. To trace how good the VA’s solutions are, we should first create a floor fact set of questions which have been validated by professionals. For instance, if we wish to embody a brand new product’s coverages within the VA, we should get the documentation and (both manually or aided by a LLM) develop a set of questions concerning the documentation and the anticipated reply to every query. Right here, it is very important notice that with every launch, the set of questions/solutions within the floor fact will increase mannequin robustness.
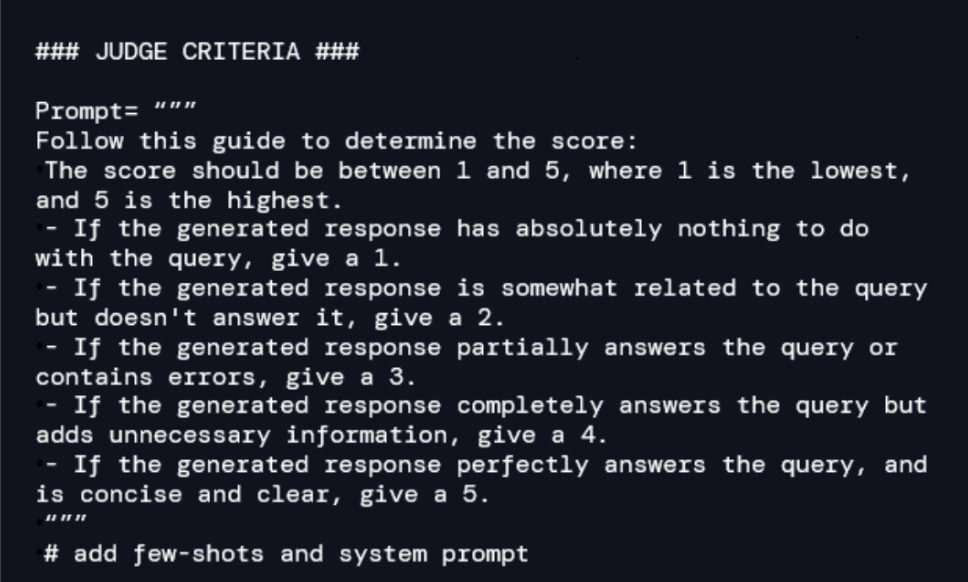
The LLM-as-a-judge consists of natural-language-based standards for measuring accuracy, relevance, and coherence between anticipated solutions and people supplied by the VA. Thus, for every query/reply pair within the floor fact, the decide oversees scoring the standard. For instance, we’d design a criterion as follows:
We set up an analysis course of inside the CI/CD pipeline. The VA solutions every query utilizing the bottom fact, and the decide assigns a rating by evaluating the anticipated reply with the one supplied by the VA. Right here is an instance with two questions:
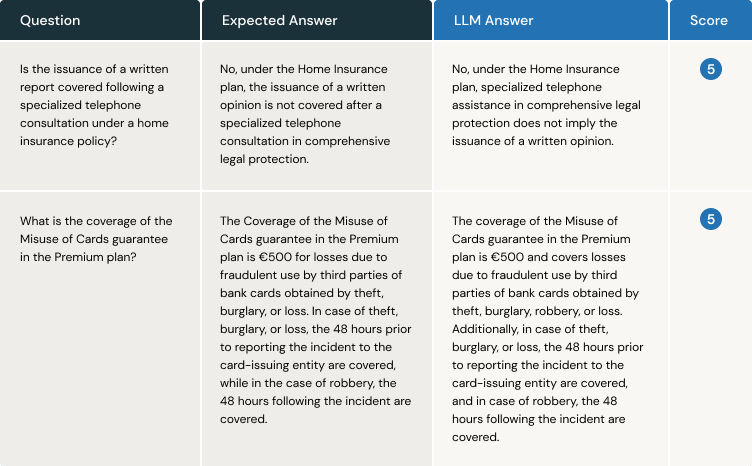
The primary benefit is apparent: we need not watch for the consumer to tell us that the VA is malfunctioning in retrieving data and producing responses. Moreover, we regularly must make minor changes to some components of the code, similar to a immediate. An analysis system like this, based mostly on floor fact and LLM-as-a-judge, permits us to detect whether or not any adjustments made to a immediate to boost the consumer expertise are impacting the standard of responses from beforehand delivered releases.
Conclusion
Santa Lucia has carried out a powerful and adaptable structure utilizing a RAG framework for a GenAI-based Digital Assistant. Our resolution combines exterior LLM fashions with our Superior Analytics Platform, guaranteeing privateness, safety and management of the information and fashions. The velocity and high quality of the responses are essential for enterprise and buyer satisfaction. Through the use of Mosaic AI Mannequin Serving and LLM-as-a-judge, the Digital Assistant has exceeded the expectations of customers whereas demonstrating finest practices for LLM deployment. We’re dedicated to enhancing our resolution additional when it comes to response high quality, efficiency, and value and look ahead to extra collaboration with the Databricks Mosaic AI workforce.
[ad_2]