[ad_1]
Massive language fashions (LLMs) have made vital strides in varied purposes, however they proceed to face substantial challenges in complicated reasoning duties. As an example, even superior fashions like Mistral-7B can solely obtain 36.5% accuracy on the GSM8K dataset, regardless of using strategies comparable to Chain-of-Thought (CoT). Whereas fine-tuning has proven promise in bettering reasoning capabilities, most LLMs depend on knowledge distilled or synthesized by superior fashions like GPT-4. This dependency on extra superior fashions has led researchers to discover different approaches to boost reasoning with out counting on a superior trainer LLM. Nonetheless, this endeavour presents its challenges, notably for smaller language fashions (SLMs), which need assistance with efficient resolution house exploration and high quality evaluation of reasoning steps.
Researchers have made varied makes an attempt to boost the reasoning capabilities of language fashions. Prompting-based strategies, comparable to Chain-of-Thought, deal with designing directions and pipelines to enhance efficiency throughout inference. These approaches embody planning, drawback decomposition, abstraction, and programming strategies. Additionally, self-improvement strategies have gained traction, with fine-tuning approaches using pre-trained LLMs to synthesise knowledge and improve efficiency progressively. Superior prompting strategies like self-verification and RAP intention to enhance efficiency by iterative self-exploration. Sampling various reasoning paths has proven promise in mathematical reasoning duties, with strategies like Self-Consistency and tree-search approaches breaking down duties into easier steps. For reply verification, majority voting is extensively used, whereas some researchers have explored coaching worth or reward fashions, although these require further annotations and threat overfitting.
Researchers from Microsoft Analysis Asia and Harvard College launched the Self-play muTuAl Reasoning (rStar) method, a sturdy resolution to boost SLMs reasoning capabilities throughout inference, with out counting on fine-tuning or superior fashions. rStar tackles the challenges confronted by SLMs by a novel self-play mutual generation-discrimination course of. This methodology employs a traditional Monte Carlo Tree Search (MCTS) for self-generating reasoning steps however expands the set of reasoning actions to simulate human reasoning behaviors. These actions embody decomposing issues, trying to find particular reasoning steps, proposing new sub-questions, and rephrasing given questions. To information the exploration of generated reasoning trajectories successfully, rStar introduces a discrimination course of referred to as mutual consistency, which employs a second SLM as a discriminator to offer unsupervised suggestions on candidate reasoning trajectories.
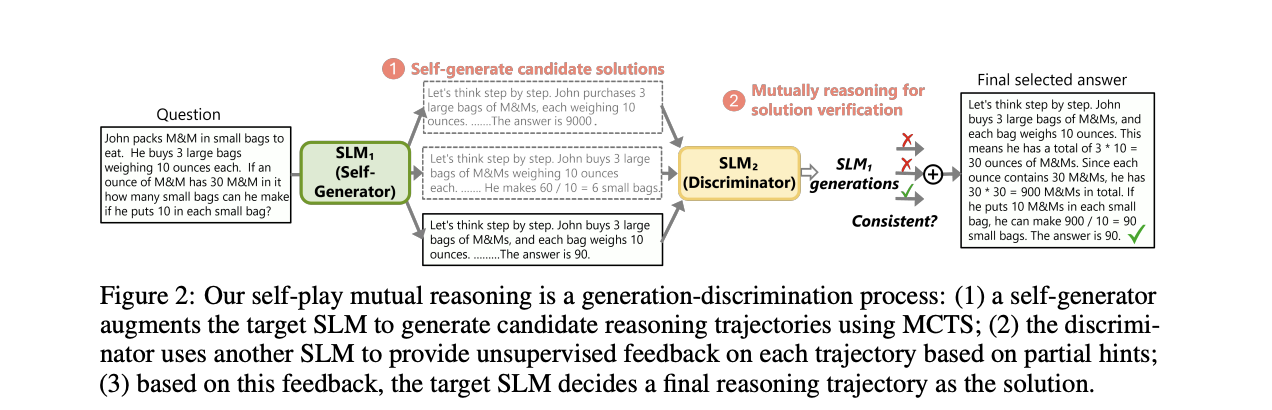
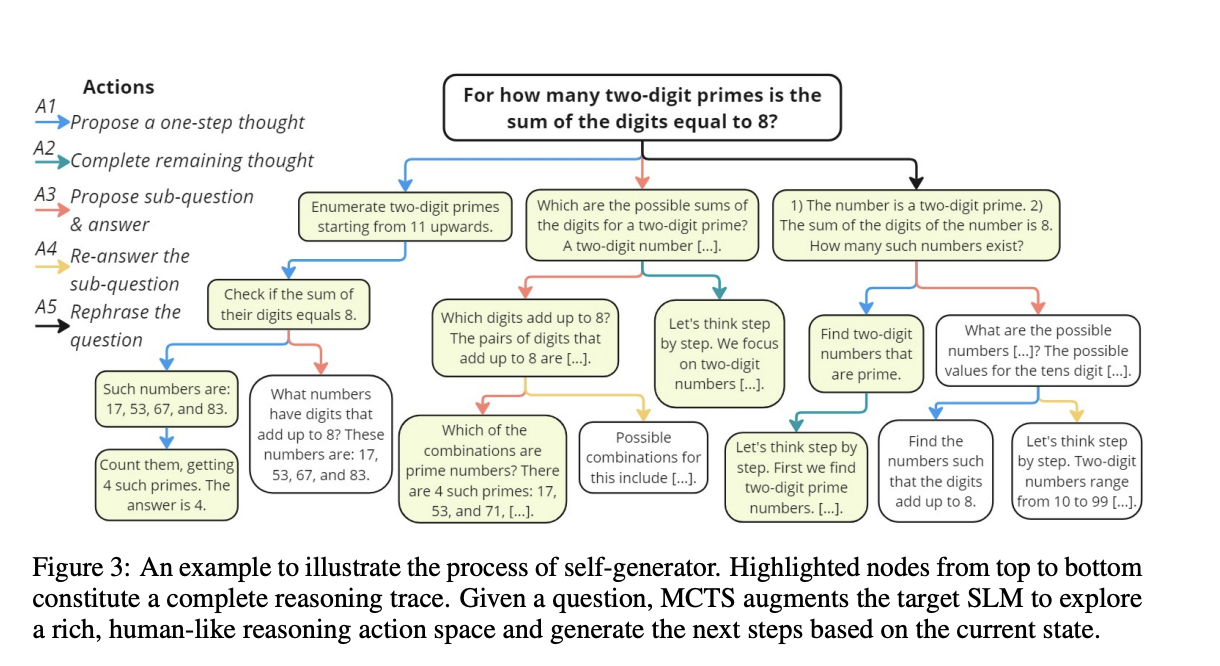
The rStar method employs a novel structure to boost SLMs reasoning capabilities. At its core, rStar makes use of an MCTS algorithm to enhance the goal SLM for self-generating multi-step reasoning options. The strategy introduces a wealthy set of 5 human-like reasoning actions, together with proposing one-step ideas, producing remaining thought steps, proposing and answering sub-questions, re-answering sub-questions, and rephrasing questions. This various motion house permits for thorough exploration throughout varied reasoning duties.
rStar implements a fastidiously designed reward perform that evaluates every motion’s worth with out counting on self-rewarding strategies or exterior supervision. The MCTS rollout course of makes use of the Higher Confidence Bounds utilized to Timber (UCT) algorithm to steadiness exploration and exploitation throughout tree growth. To confirm the generated reasoning trajectories, rStar introduces a second SLM as a discriminator, using a mutual consistency method. This course of entails masking a part of a candidate trajectory and asking the discriminator SLM to finish it, then evaluating the outcomes for consistency.
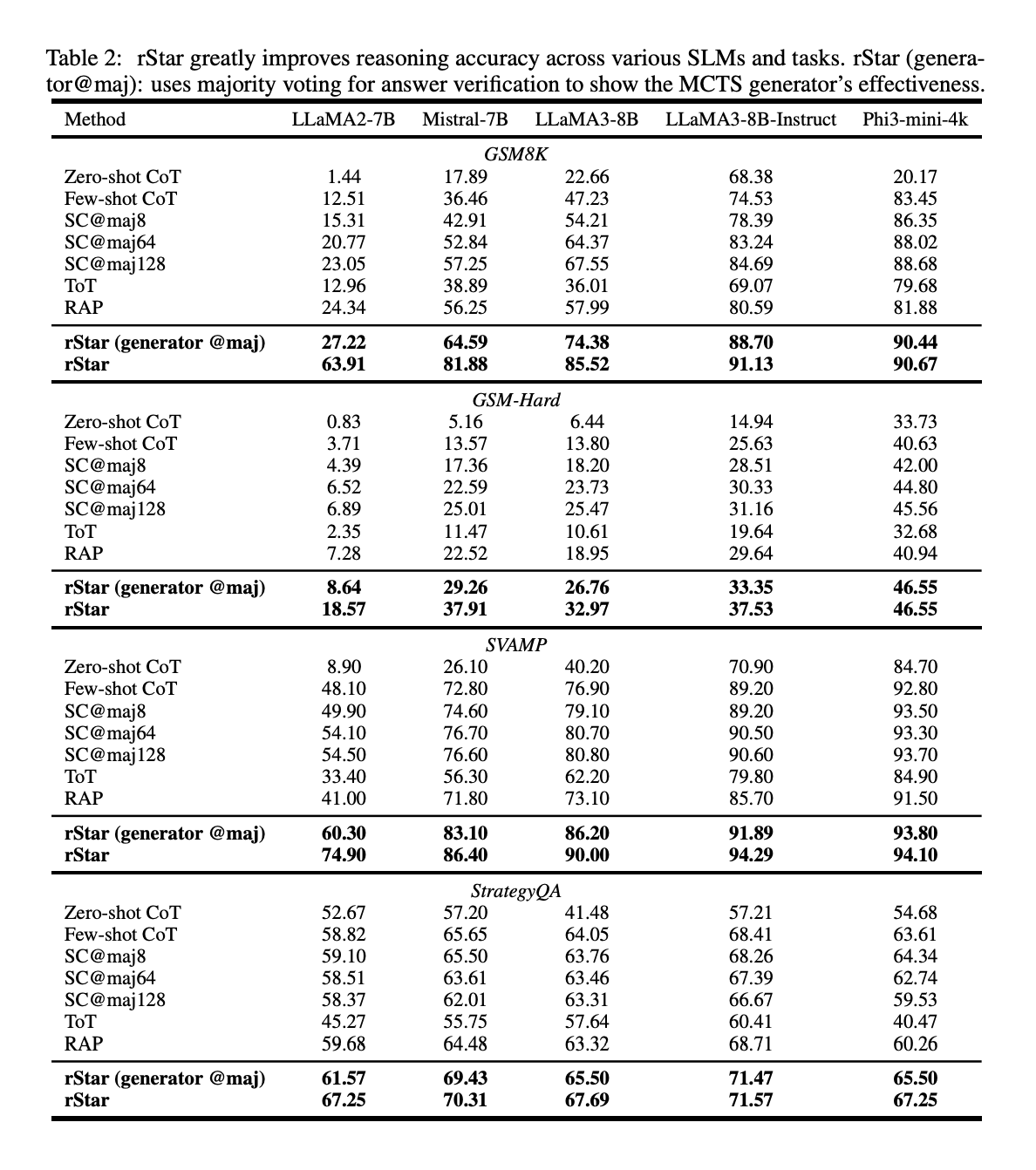
The outcomes show the effectiveness of rStar throughout varied reasoning benchmarks and language fashions:
1. Efficiency on various reasoning duties:
- rStar considerably improved SLMs’ problem-solving skills. For instance, LLaMA2-7B’s accuracy on GSM8K elevated from 12.51% with few-shot CoT to 63.91% with rStar, almost matching fine-tuned efficiency.
- rStar constantly improved reasoning accuracy throughout completely different SLMs and duties to state-of-the-art ranges, outperforming different baseline approaches.
- Even with out the discriminator, rStar’s generator outperformed present multi-round inference baselines like RAP, ToT, and Self-Consistency on GSM8K.
2. Effectivity:
- rStar confirmed vital enhancements in reasoning accuracy with simply 2 rollouts on the GSM8K dataset.
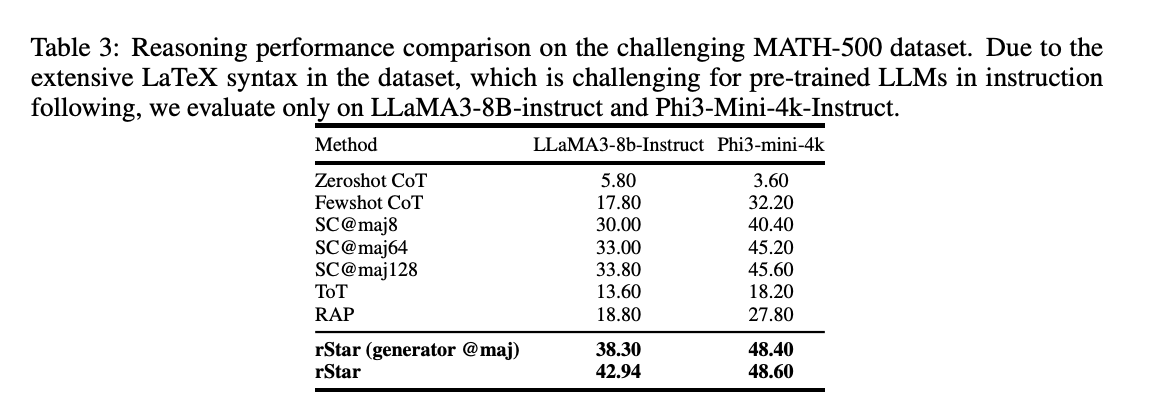
3. Efficiency on difficult mathematical datasets:
- On GSM-Onerous and MATH-500, rStar improved SLMs’ reasoning accuracy considerably, with enhancements of as much as 12.9% and 9.14% respectively in comparison with state-of-the-art baselines.
4. Ablation research:
- The MCTS generator in rStar outperformed different approaches like RAP and Self-Consistency throughout completely different fashions and duties.
- rStar’s discriminator constantly outperformed different verification strategies, together with majority voting and self-verification, throughout completely different turbines.
5. Mannequin comparisons:
- Completely different fashions had been examined as discriminators, with GPT-4 attaining the very best accuracy (92.57%) on GSM8K, adopted by Phi3-Mini-Instruct (91.13%).
These outcomes spotlight rStar’s effectiveness in enhancing SLMs’ reasoning capabilities throughout varied duties and fashions, outperforming present strategies in each accuracy and effectivity.
The rStar method introduces a sturdy generator-discriminator self-play methodology that considerably enhances the reasoning capabilities of SLMs throughout inference. This analysis reveals that SLMs like LLaMA2-7B possess robust inherent reasoning skills even earlier than domain-specific supervised fine-tuning. rStar demonstrates state-of-the-art efficiency throughout 5 completely different SLMs and 5 various reasoning duties, considerably outperforming present multi-round prompting and self-improvement strategies. The intensive ablation research and evaluation performed on this analysis contribute useful insights to the sector, paving the way in which for extra superior self-improved reasoning strategies in SLMs. These findings spotlight the potential of rStar in unlocking the latent reasoning capabilities of language fashions with out the necessity for intensive fine-tuning or reliance on bigger fashions.
Try the Paper. All credit score for this analysis goes to the researchers of this undertaking. Additionally, don’t overlook to comply with us on Twitter and be a part of our Telegram Channel and LinkedIn Group. When you like our work, you’ll love our e-newsletter..
Don’t Neglect to hitch our 48k+ ML SubReddit
Discover Upcoming AI Webinars right here
Asjad is an intern marketing consultant at Marktechpost. He’s persuing B.Tech in mechanical engineering on the Indian Institute of Expertise, Kharagpur. Asjad is a Machine studying and deep studying fanatic who’s all the time researching the purposes of machine studying in healthcare.
[ad_2]