[ad_1]
Temporal reasoning entails understanding and deciphering the relationships between occasions over time, a vital functionality for clever methods. This area of analysis is important for growing AI that may deal with duties starting from pure language processing to decision-making in dynamic environments. AI can carry out advanced operations like scheduling, forecasting, and historic knowledge evaluation by precisely deciphering time-related knowledge. This makes temporal reasoning a foundational facet of growing superior AI methods.
Regardless of the significance of temporal reasoning, current benchmarks typically must be revised. They rely closely on real-world knowledge that LLMs might have seen throughout coaching or use anonymization strategies that may result in inaccuracies. This creates a necessity for extra strong analysis strategies that precisely measure LLMs’ skills in temporal reasoning. The first problem lies in creating benchmarks that check reminiscence recall and genuinely consider reasoning expertise. That is crucial for purposes requiring exact and context-aware temporal understanding.
Present analysis consists of the event of artificial datasets for probing LLM capabilities, similar to logical and mathematical reasoning. Frameworks like TempTabQA, TGQA, and information graph-based benchmarks are extensively used. Nevertheless, these strategies are restricted by the inherent biases and pre-existing information throughout the fashions. This typically leads to evaluations that don’t actually mirror the fashions’ reasoning capabilities however reasonably their skill to recall realized info. The deal with well-known entities and information must adequately problem the fashions’ understanding of temporal logic and arithmetic, resulting in an incomplete evaluation of their true capabilities.
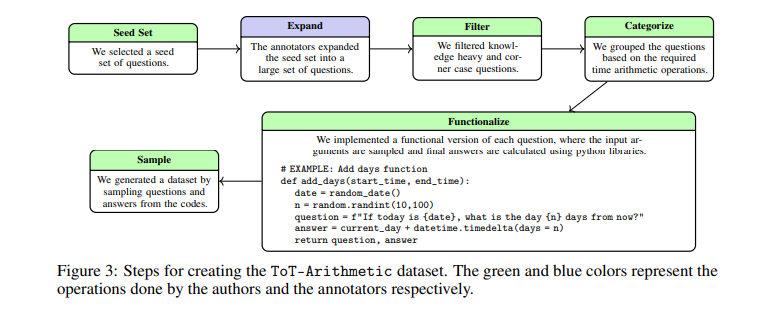
To deal with these challenges, researchers from Google Analysis, Google DeepMind, and Google have launched the Take a look at of Time (ToT) benchmark. This modern benchmark makes use of artificial datasets particularly designed to judge temporal reasoning with out counting on the fashions’ prior information. The benchmark is open-sourced to encourage additional analysis and growth on this space. The introduction of ToT represents a big development, offering a managed setting to systematically check and enhance LLMs’ temporal reasoning expertise.
The ToT benchmark consists of two essential duties. ToT-Semantic focuses on temporal semantics and logic, permitting for versatile exploration of numerous graph constructions and reasoning complexities. This job isolates core reasoning skills from pre-existing information. ToT-Arithmetic assesses the power to carry out calculations involving time factors and durations, utilizing crowd-sourced duties to make sure sensible relevance. These duties are meticulously designed to cowl numerous temporal reasoning situations, offering an intensive analysis framework.
To create the ToT-Semantic job, researchers generated random graph constructions utilizing algorithms similar to Erdős-Rényi and Barabási-–Albert fashions. These graphs had been then used to create numerous temporal questions, permitting for an in-depth evaluation of LLMs’ skill to know and cause about time. For ToT-Arithmetic, duties had been designed to check sensible arithmetic involving time, similar to calculating durations and dealing with time zone conversions. This twin strategy ensures a complete analysis of each logical and arithmetic elements of temporal reasoning.
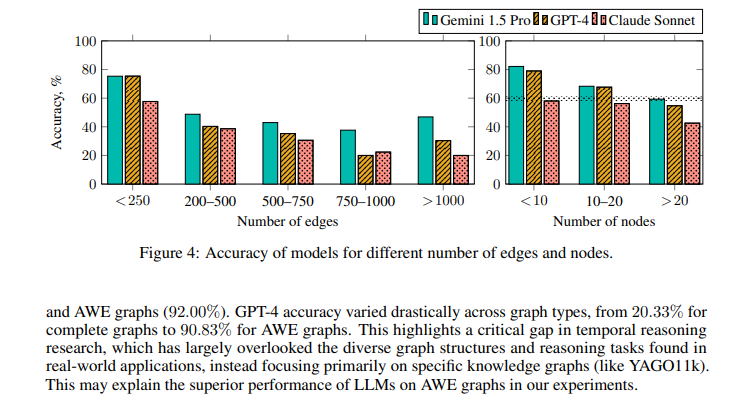
Experimental outcomes utilizing the ToT benchmark reveal important insights into the strengths and weaknesses of present LLMs. For example, GPT-4’s efficiency diversified extensively throughout totally different graph constructions, with accuracy starting from 40.25% on full graphs to 92.00% on AWE graphs. These findings spotlight the impression of temporal construction on reasoning efficiency. Moreover, the order of information offered to the fashions considerably influenced their efficiency, with the best accuracy noticed when the goal entity sorted information and begin time.
The research additionally explored the varieties of temporal questions and their problem ranges. Single-fact questions had been simpler for fashions to deal with, whereas multi-fact questions, requiring integration of a number of items of data, posed extra challenges. For instance, GPT-4 achieved 90.29% accuracy on EventAtWhatTime questions however struggled with Timeline questions, indicating a spot in dealing with advanced temporal sequences. The detailed evaluation of query varieties and mannequin efficiency offers a transparent image of present capabilities and areas needing enchancment.
In conclusion, the ToT benchmark represents a big development in evaluating LLMs’ temporal reasoning capabilities. Offering a extra complete and managed evaluation framework helps determine areas for enchancment and guides the event of extra succesful AI methods. This benchmark units the stage for future analysis to boost the temporal reasoning skills of LLMs, finally contributing to the broader objective of reaching synthetic normal intelligence.
Take a look at the Paper and HF Web page. All credit score for this analysis goes to the researchers of this challenge. Additionally, don’t neglect to comply with us on Twitter.
Be a part of our Telegram Channel and LinkedIn Group.
For those who like our work, you’ll love our publication..
Don’t Neglect to affix our 44k+ ML SubReddit
Nikhil is an intern advisor at Marktechpost. He’s pursuing an built-in twin diploma in Supplies on the Indian Institute of Expertise, Kharagpur. Nikhil is an AI/ML fanatic who’s at all times researching purposes in fields like biomaterials and biomedical science. With a powerful background in Materials Science, he’s exploring new developments and creating alternatives to contribute.
[ad_2]