[ad_1]
Video massive language fashions (LLMs) have emerged as highly effective instruments for processing video inputs and producing contextually related responses to consumer instructions. Nonetheless, these fashions face vital challenges of their present methodologies. The first difficulty lies within the excessive computational and labeling prices related to coaching on supervised fine-tuning (SFT) video datasets. Additionally, current Video LLMs wrestle with two most important drawbacks: they’re restricted of their potential to course of numerous enter frames, hindering the seize of fine-grained spatial and temporal content material all through movies, and so they lack correct temporal modeling design, relying solely on the LLM’s functionality to mannequin movement patterns with out specialised video processing parts.
Researchers have tried to unravel video processing challenges utilizing varied LLM approaches. Picture LLMs like Flamingo, BLIP-2, and LLaVA demonstrated success in visual-textual duties, whereas Video LLMs akin to Video-ChatGPT and Video-LLaVA prolonged these capabilities to video processing. Nonetheless, these fashions usually require costly fine-tuning on massive video datasets. Coaching-free strategies like FreeVA and IG-VLM emerged as cost-efficient alternate options, using pre-trained Picture LLMs with out extra fine-tuning. Regardless of promising outcomes, these approaches nonetheless wrestle with processing longer movies and capturing advanced temporal dependencies, limiting their effectiveness in dealing with numerous video content material.
Apple researchers current SF-LLaVA, a singular training-free Video LLM that addresses the challenges in video processing by introducing a SlowFast design impressed by profitable two-stream networks for motion recognition. This strategy captures each detailed spatial semantics and long-range temporal context with out requiring extra fine-tuning. The Gradual pathway extracts options at a low body fee with larger spatial decision, whereas the Quick pathway operates at a excessive body fee with aggressive spatial pooling. This dual-pathway design balances modeling functionality and computational effectivity, enabling the processing of extra video frames to protect sufficient particulars. SF-LLaVA integrates complementary options from slowly altering visible semantics and quickly altering movement dynamics, offering a complete understanding of movies and overcoming the constraints of earlier strategies.
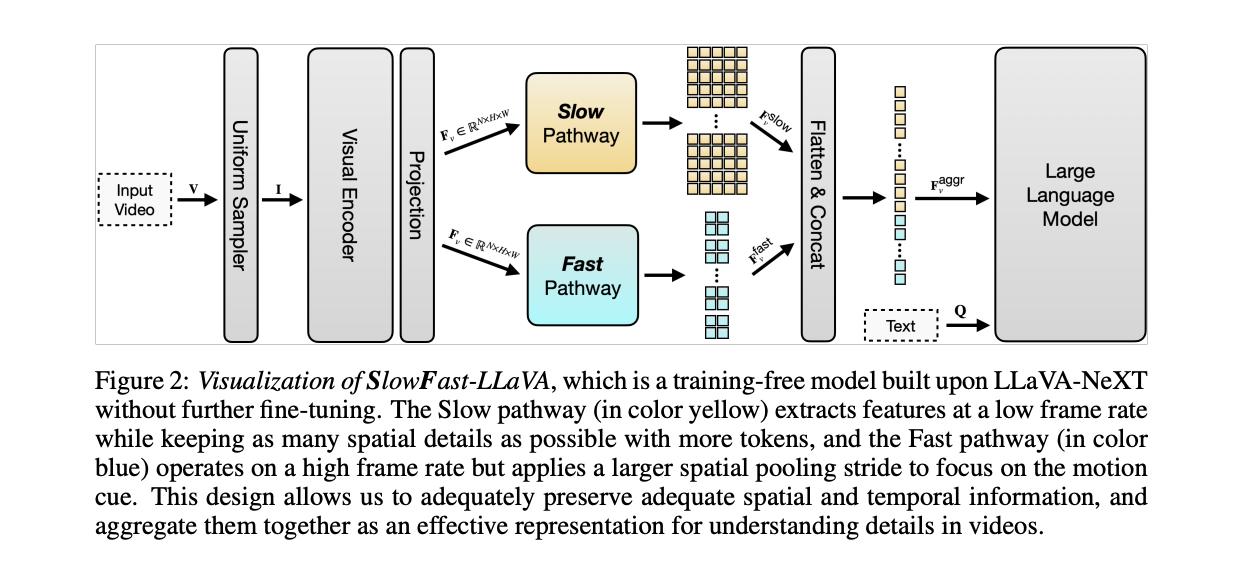
SlowFast-LLaVA (SF-LLaVA) introduces a singular SlowFast structure for training-free Video LLMs, impressed by two-stream networks for motion recognition. This design successfully captures each detailed spatial semantics and long-range temporal context with out exceeding the token limits of frequent LLMs. The Gradual pathway processes high-resolution however low-frame-rate options (e.g., 8 frames with 24×24 tokens every) to seize spatial particulars. Conversely, the Quick pathway handles low-resolution however high-frame-rate options (e.g., 64 frames with 4×4 tokens every) to mannequin broader temporal context. This dual-pathway strategy permits SF-LLaVA to protect each spatial and temporal info, aggregating them into a strong illustration for complete video understanding with out requiring extra fine-tuning.
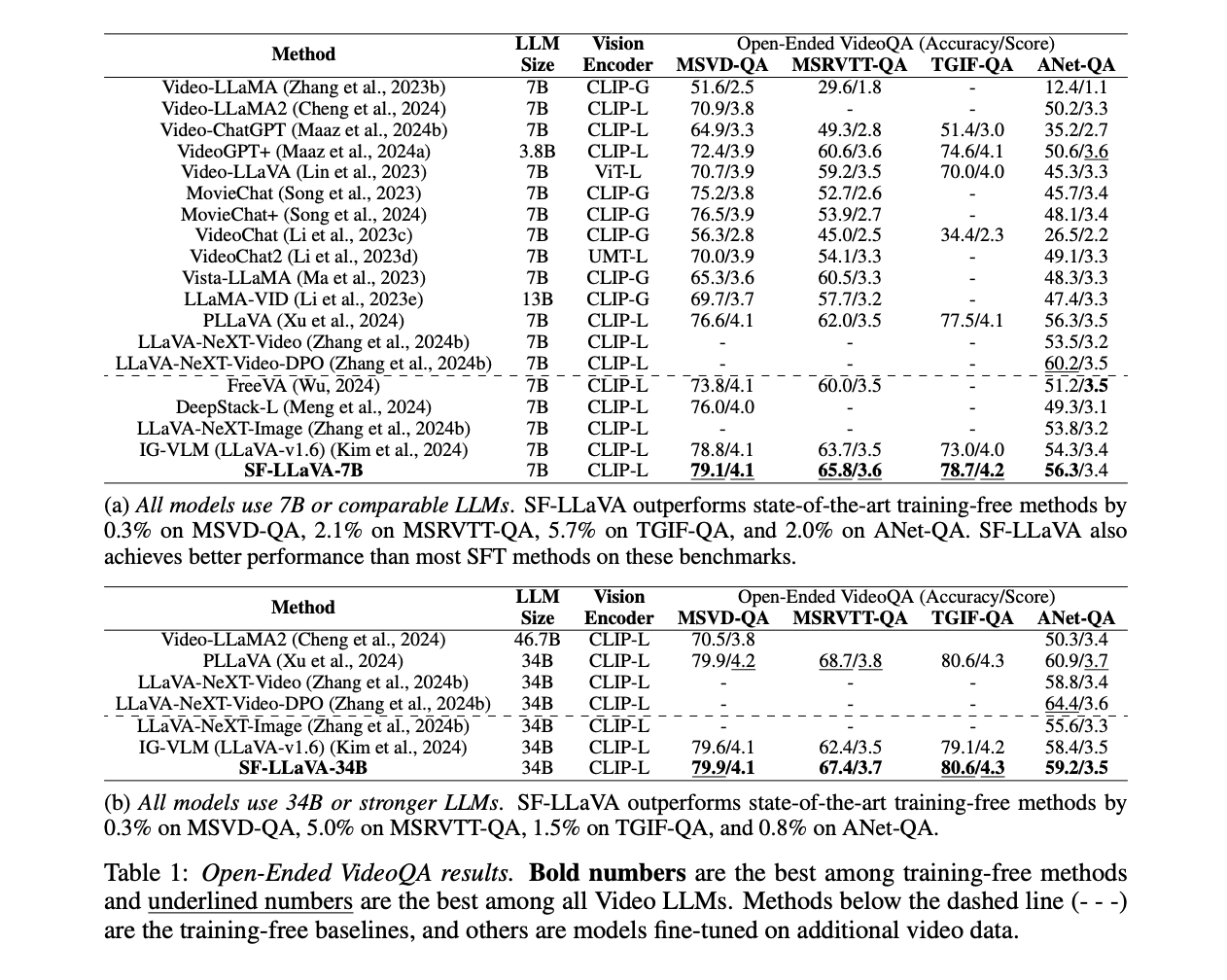
SF-LLaVA demonstrates spectacular efficiency throughout varied video understanding duties, usually surpassing state-of-the-art training-free strategies and competing with SFT fashions. In open-ended VideoQA duties, SF-LLaVA outperforms different training-free strategies on all benchmarks, with enhancements of as much as 5.7% on some datasets. For multiple-choice VideoQA, SF-LLaVA reveals vital benefits, significantly on advanced long-form temporal reasoning duties like EgoSchema, the place it outperforms IG-VLM by 11.4% utilizing a 7B LLM. In textual content technology duties, SF-LLaVA-34B surpasses all training-free baselines on common and excels in temporal understanding. Whereas SF-LLaVA often falls quick in capturing advantageous spatial particulars in comparison with some strategies, its SlowFast design permits it to cowl longer temporal contexts effectively, demonstrating superior efficiency in most duties, particularly these requiring temporal reasoning.
This analysis introduces SF-LLaVA, a singular training-free Video LLM, presenting a major leap in video understanding with out the necessity for added fine-tuning. Constructed upon LLaVA-NeXT, it introduces a SlowFast design that makes use of two-stream inputs to seize each detailed spatial semantics and long-range temporal context successfully. This revolutionary strategy aggregates body options right into a complete video illustration, enabling SF-LLaVA to carry out exceptionally nicely throughout varied video duties. In depth experiments throughout 8 numerous video benchmarks show SF-LLaVA’s superiority over current training-free strategies, with efficiency usually matching or exceeding state-of-the-art supervised fine-tuned Video LLMs. SF-LLaVA not solely serves as a powerful baseline within the subject of Video LLMs but in addition provides helpful insights for future analysis in modeling video representations for Multimodal LLMs by its design selections.
Try the Paper. All credit score for this analysis goes to the researchers of this challenge. Additionally, don’t neglect to observe us on Twitter and be part of our Telegram Channel and LinkedIn Group. In the event you like our work, you’ll love our e-newsletter..
Don’t Neglect to hitch our 47k+ ML SubReddit
Discover Upcoming AI Webinars right here
Asjad is an intern advisor at Marktechpost. He’s persuing B.Tech in mechanical engineering on the Indian Institute of Know-how, Kharagpur. Asjad is a Machine studying and deep studying fanatic who’s at all times researching the functions of machine studying in healthcare.

[ad_2]