[ad_1]
Introduction
Textual content summarization is a necessary a part of pure language processing (NLP) that tries to shorten monumental quantities of textual content and make extra readable summaries whereas retaining essential info. Given the enlargement of web materials, good summarizing methods are important for numerous purposes, equivalent to tutorial analysis, content material technology, and information summaries. This text will clarify find out how to construct a textual content summarization utilizing the T5-base transformer mannequin on the CNN/DailyMail dataset. Moreover, it contains pre-processing the info, loading the mannequin, fine-tuning it, and evaluating it.
Studying Goals
- Perceive textual content summarization’s key ideas and their purposes in NLP.
- Study concerning the options and structure of the T5 mannequin.
- Learn the way textual content summarizing duties are carried out with this dataset.
- Uncover find out how to put together textual content information for the T5 mannequin.
- Perceive find out how to fine-tune a T5-base mannequin already educated on a dataset.
- Study methods to evaluate mannequin efficiency and produce summaries on unseen information, our check information.
What Method Are We Taking?
Allow us to have a look at our method for textual content summarization utilizing T5-base on the CNN/DailyMail dataset.
T5 Mannequin and Tokenizer
The T5 mannequin and tokenizer are vital elements for textual content summarization. The tokenizer converts textual content into token sequences, that are numerical representations the mannequin can course of. The T5 mannequin then makes use of these token sequences to generate summaries. On this undertaking, we make the most of the t5-base variant of the mannequin, which balances efficiency and computational effectivity.
Additionally Learn: What are Giant Language Fashions(LLMs)?
Dataset
The CNN/DailyMail dataset is a broadly used benchmark for summarization duties. It incorporates information articles and corresponding summaries (highlights), making it superb for coaching and evaluating summarization fashions. The dataset is split into coaching, validation, and check units, guaranteeing sturdy mannequin analysis.
Preprocessing
Preprocessing includes tokenizing the articles and summaries to organize them for enter into the T5 mannequin. This step contains truncating textual content to suit inside mannequin constraints and padding sequences to make sure uniform enter lengths. The preprocess_function handles these duties, creating mannequin inputs and corresponding labels.
Coaching and Analysis
Nice-tuning the T5 mannequin includes coaching it on the preprocessed dataset. We arrange coaching arguments to regulate numerous facets of the coaching course of, equivalent to studying charge, batch measurement, and the variety of epochs. The Coach class from the Transformers library simplifies this course of, seamlessly dealing with mannequin coaching and analysis.
Inference
After fine-tuning, the mannequin is evaluated on the check set to evaluate its efficiency. We then generate summaries for unseen information utilizing the fine-tuned mannequin. The generate_summary perform encodes enter articles, generates summaries, and decodes the output to readable textual content.
What’s the T-5 Mannequin?
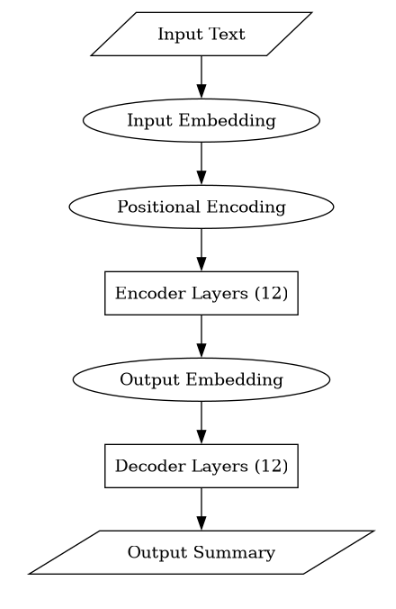
The T5 structure includes a stack of transformer encoder-decoder layers, every layer iteratively processing enter textual content to seize contextual info and supply significant representations. These interconnected layers permit for environment friendly info circulate and hierarchical illustration studying. T5 delivers cutting-edge efficiency throughout a number of NLP benchmarks whereas preserving a easy and scalable structure.
T-5 base Structure
Allow us to now have a look at the structure of the T-5 base.
Comparability with Different T-5 Fashions
Allow us to now evaluate it with different T-5 fashions.

Code for Textual content Summarization Utilizing T5-base
Right here is the code that can assist us implement the textual content summarization utilizing T5-base on CNN/DailyMail dataset.
Set up and Setup
First, we set up the mandatory libraries and import the required modules:
Earlier than we start, guarantee to put in the next:
!pip set up transformers datasets
!pip set up speed up -U
!pip set up transformers[torch]
from transformers import T5ForConditionalGeneration, T5Tokenizer, Coach, TrainingArguments
from datasets import load_datasetLoading the Dataset
We load the CNN/DailyMail dataset:
dataset = load_dataset("cnn_dailymail", "3.0.0")
Mannequin and Tokenizer
We load the pre-trained T5 mannequin and tokenizer:
model_name = "t5-base"
mannequin = T5ForConditionalGeneration.from_pretrained(model_name)
tokenizer = T5Tokenizer.from_pretrained(model_name)Preprocessing the Knowledge
The preprocess_function prepares the info for the mannequin:
def preprocess_function(examples):
inputs = [doc for doc in examples['article']]
model_inputs = tokenizer(inputs, max_length=512, truncation=True, padding="max_length")
with tokenizer.as_target_tokenizer():
labels = tokenizer(examples['highlights'], max_length=128, truncation=True, padding="max_length")
model_inputs["labels"] = labels["input_ids"]
return model_inputs
encoded_dataset = dataset.map(preprocess_function, batched=True)Splitting the Dataset
We cut up the dataset into coaching and check units:
train_dataset = encoded_dataset["train"].shuffle(seed=42).choose(vary(2000))
test_dataset = encoded_dataset["validation"].shuffle(seed=42).choose(vary(1000))Coaching the Mannequin
We arrange coaching arguments and fine-tuned the mannequin:
training_args = TrainingArguments(
output_dir="./outcomes",
evaluation_strategy="epoch",
learning_rate=3e-4,
per_device_train_batch_size=4,
per_device_eval_batch_size=4,
num_train_epochs=3,
weight_decay=0.01,
save_total_limit=3,
)
coach = Coach(
mannequin=mannequin,
args=training_args,
train_dataset=train_dataset,
eval_dataset=test_dataset,
)
coach.practice()Evaluating the Mannequin
We consider the fine-tuned mannequin:
coach.consider()Producing Summaries
Lastly, we generate summaries for the check set:
import torch
machine = torch.machine("cuda" if torch.cuda.is_available() else "cpu")
mannequin.to(machine)
def generate_summary(instance):
input_ids = tokenizer.encode(instance["article"], return_tensors="pt", max_length=512, truncation=True).to(machine)
output = mannequin.generate(input_ids)
abstract = tokenizer.decode(output[0], skip_special_tokens=True)
return {"abstract": abstract}
summaries = test_dataset.map(generate_summary, batched=False)Displaying Examples
We show a number of examples to match reference and generated summaries (utilizing the unseen check dataset):
for i in vary(3):
print("Article:", test_dataset[i]["article"])
print("nReference Abstract:", test_dataset[i]["highlights"])
print("nGenerated Abstract:", summaries[i]["summary"])
print("n")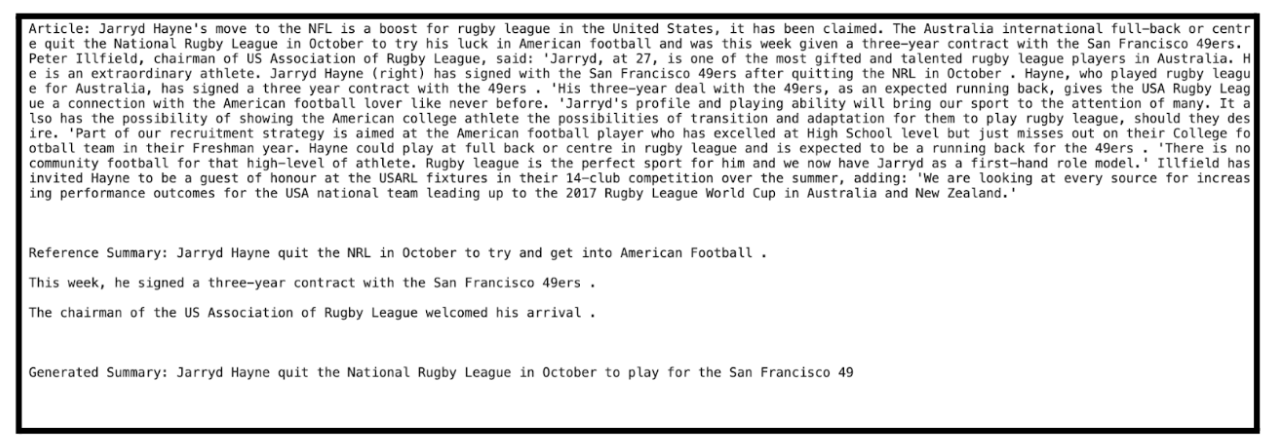
The present textual content summarization output captures the essence of the unique textual content. Nevertheless, we are able to strive a number of issues for the abstract to have extra depth and coherence. To enhance efficiency, totally different fine-tuning and hyperparameter tuning procedures might be investigated. This contains fine-tuning with a bigger and extra various dataset and altering studying charges, batch sizes, and the variety of coaching epochs to enhance mannequin convergence and generalization.
Moreover, experimenting with different transformer fashions and structure changes, equivalent to including layers or consideration heads, might assist to enhance the summarization course of. The textual content summarising system can create extra complete and informative summaries by iteratively refining the mannequin and experimenting with totally different hyperparameters.
Analysis of Abstract
We’ll use rouge for our analysis; let’s first make sure the set up by operating ‘pip set up rouge.’
from rouge import Rouge
def calculate_rouge(reference_list, generated_list):
rouge = Rouge()
scores = rouge.get_scores(generated_list, reference_list)
rouge_1 = sum(rating['rouge-1']['f'] for rating in scores) / len(scores)
rouge_2 = sum(rating['rouge-2']['f'] for rating in scores) / len(scores)
rouge_l = sum(rating['rouge-l']['f'] for rating in scores) / len(scores)
return rouge_1, rouge_2, rouge_l
# Initialize lists to retailer reference and generated summaries
reference_summaries = [example["highlights"] for instance in test_dataset]
generated_summaries = [example["summary"] for instance in summaries]
# Calculate ROUGE scores
rouge_1, rouge_2, rouge_l = calculate_rouge(reference_summaries, generated_summaries)
print("Common ROUGE-1:", rouge_1)
print("Common ROUGE-2:", rouge_2)
print("Common ROUGE-L:", rouge_l)
These common ROUGE scores point out the standard of the generated summaries in comparison with the reference summaries throughout your dataset. ROUGE makes use of each precision and recall to match model-generated summaries. Right here’s what every rating means:
ROUGE-1 gauges how intently the generated and reference summaries coincide concerning unigrams or particular person phrases. The generated summaries’ common ROUGE-1 rating of 0.2347 reveals that, on common, 23.47% of the unigrams match these within the reference summaries.
ROUGE-2 gauges how intently the generated and reference summaries overlap in bigrams or pairs of neighboring phrases. In accordance with a median ROUGE-2 rating of 0.0959, about 9.59% of the bigrams within the generated summaries match these within the reference summaries.
ROUGE-L counts the variety of phrases shared the longest between the reference and generated summaries. In accordance with a median ROUGE-L rating of 0.2238, about 22.38% of the longest widespread subsequence of phrases within the generated summaries matches that within the reference summaries.
Conclusion
Due to this fact, textual content summarization with the T5-base mannequin on the CNN/DailyMail dataset highlights the effectivity of transformer-based architectures for compressing huge texts into brief summaries. We will produce high-quality summarization outcomes by taking an organized technique, starting with dataset loading and preprocessing and ending with mannequin fine-tuning and analysis. This methodology demonstrates the T5 mannequin’s adaptability and the importance of rigorous preprocessing and meticulous mannequin coaching.
Incessantly Requested Questions
A. The T5 mannequin is uncommon as a result of it treats all NLP jobs as text-to-text issues. Translation, summarization, and query answering are all considered as textual content creation duties. This makes it a really adaptable mannequin that may be fine-tuned for a number of duties utilizing the identical structure, in contrast to the opposite transformer fashions that will require task-specific buildings or changes.
A. The Coach class within the Transformers library makes mannequin coaching and evaluation simpler by offering a high-level interface for specifying coaching parameters, dealing with datasets, and operating the coaching loop. It automates procedures like gradient buildup and checkpoints like saving and analysis metrics calculation, making it simpler to fine-tune and assess transformer fashions with out intensive boilerplate code.
A. ROUGE (Recall-Oriented Understudy for Gisting evaluation) scores are widespread evaluation metrics for summarization fashions. They present the overlap of n-grams, phrase sequences, and phrase pairs between the article and the generated abstract. A number of widespread analysis measures embody ROUGE-1, ROUGE-2, and ROUGE-L. These metrics assist quantitatively consider the mannequin’s generated summaries’ high quality and relevancy. Human analysis can even assist decide the summaries’ high quality and the mannequin’s efficiency.
[ad_2]