[ad_1]
Multimodal synthetic intelligence focuses on growing fashions able to processing and integrating numerous information varieties, corresponding to textual content and pictures. These fashions are important for answering visible questions and producing descriptive textual content for pictures, highlighting AI’s means to know and work together with a multifaceted world. Mixing data from totally different modalities permits AI to carry out complicated duties extra successfully, demonstrating vital promise in analysis and sensible purposes.
One of many major challenges in multimodal AI is optimizing mannequin effectivity. Conventional strategies fusing modality-specific encoders or decoders usually restrict the mannequin’s means to combine data throughout totally different information varieties successfully. This limitation leads to elevated computational calls for and lowered efficiency effectivity. Researchers have been striving to develop new architectures that seamlessly combine textual content and picture information from the outset, aiming to boost the mannequin’s efficiency and effectivity in dealing with multimodal inputs.
Current strategies for dealing with mixed-modal information embrace architectures that preprocess and encode textual content and picture information individually earlier than integrating them. These approaches, whereas purposeful, could be computationally intensive and should solely partially exploit the potential of early information fusion. The separation of modalities usually results in inefficiencies and an lack of ability to adequately seize the complicated relationships between totally different information varieties. Due to this fact, progressive options are required to beat these challenges and obtain higher efficiency.
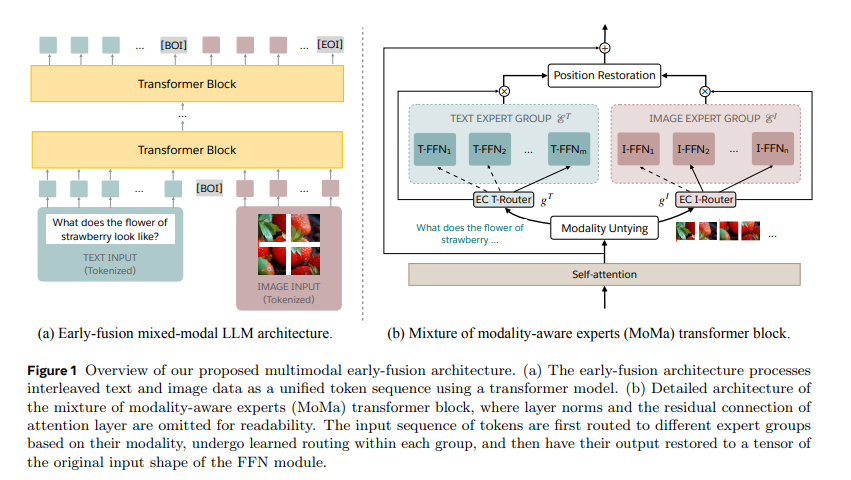
To handle these challenges, researchers at Meta launched MoMa, a novel modality-aware mixture-of-experts (MoE) structure designed to pre-train mixed-modal, early-fusion language fashions. MoMa processes textual content and pictures in arbitrary sequences by dividing knowledgeable modules into modality-specific teams. Every group solely handles designated tokens, using realized routing inside every group to take care of semantically knowledgeable adaptivity. This structure considerably improves pre-training effectivity, with empirical outcomes exhibiting substantial features. The analysis, performed by a crew at Meta, showcases the potential of MoMa to advance mixed-modal language fashions.
The know-how behind MoMa entails a mix of mixture-of-experts (MoE) and mixture-of-depths (MoD) strategies. In MoE, tokens are routed throughout a set of feed-forward blocks (specialists) at every layer. These specialists are divided into text-specific and image-specific teams, permitting for specialised processing pathways. This strategy, termed modality-aware sparsity, enhances the mannequin’s means to seize options particular to every modality whereas sustaining cross-modality integration by means of shared self-attention mechanisms. Moreover, MoD permits tokens to selectively skip computations at sure layers, additional optimizing the processing effectivity.
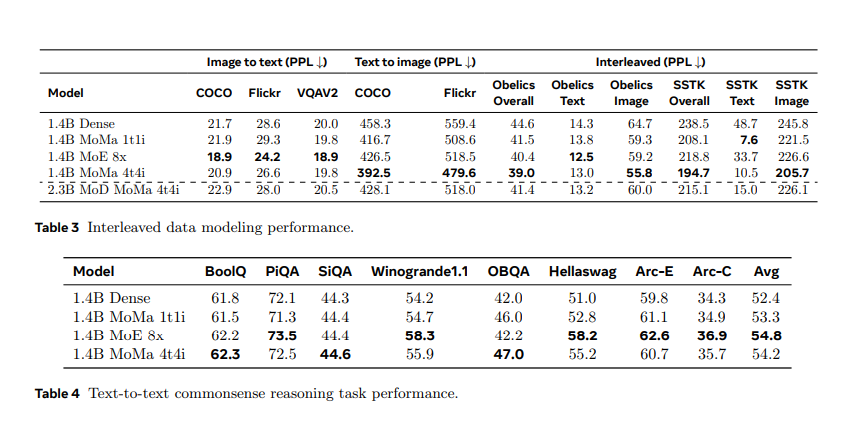
The efficiency of MoMa was evaluated extensively, exhibiting substantial enhancements in effectivity and effectiveness. Underneath a 1-trillion-token coaching finances, the MoMa 1.4B mannequin, which incorporates 4 textual content specialists and 4 picture specialists, achieved a 3.7× total discount in floating-point operations per second (FLOPs) in comparison with a dense baseline. Particularly, it achieved a 2.6× discount for textual content and a 5.2× discount for picture processing. When mixed with MoD, the general FLOPs financial savings elevated to 4.2×, with textual content processing enhancing by 3.4× and picture processing by 5.3×. These outcomes spotlight MoMa’s potential to considerably improve the effectivity of mixed-modal, early-fusion language mannequin pre-training.
MoMa’s progressive structure represents a major development in multimodal AI. By integrating modality-specific specialists and superior routing strategies, the researchers have developed a extra resource-efficient AI mannequin that maintains excessive efficiency throughout numerous duties. This innovation addresses vital computational effectivity points, paving the best way for growing extra succesful and resource-effective multimodal AI programs. The crew’s work demonstrates the potential for future analysis to construct upon these foundations, exploring extra refined routing mechanisms and increasing the strategy to extra modalities and duties.
In abstract, the MoMa structure, developed by Meta researchers, affords a promising resolution to the computational challenges in multimodal AI. The strategy leverages modality-aware mixture-of-experts and mixture-of-depths strategies to attain vital effectivity features whereas sustaining strong efficiency. This breakthrough paves the best way for the subsequent technology of multimodal AI fashions, which may course of and combine numerous information varieties extra successfully and effectively, enhancing AI’s functionality to know and work together with the complicated, multimodal world we dwell in.
Try the Paper. All credit score for this analysis goes to the researchers of this undertaking. Additionally, don’t neglect to comply with us on Twitter and be a part of our Telegram Channel and LinkedIn Group. Should you like our work, you’ll love our e-newsletter..
Don’t Neglect to hitch our 47k+ ML SubReddit
Discover Upcoming AI Webinars right here
Nikhil is an intern advisor at Marktechpost. He’s pursuing an built-in twin diploma in Supplies on the Indian Institute of Know-how, Kharagpur. Nikhil is an AI/ML fanatic who’s at all times researching purposes in fields like biomaterials and biomedical science. With a robust background in Materials Science, he’s exploring new developments and creating alternatives to contribute.

[ad_2]