[ad_1]
Reinforcement studying (RL) is a specialised space of machine studying the place brokers are skilled to make selections by interacting with their surroundings. This interplay entails taking motion and receiving suggestions by means of rewards or penalties. RL has been instrumental in growing superior robotics, autonomous automobiles, and strategic game-playing applied sciences and fixing complicated issues in numerous scientific and industrial domains.
A big problem in RL is managing the complexity of environments with massive discrete motion areas. Conventional RL strategies like Q-learning contain a computationally costly means of evaluating the worth of all doable actions at every choice level. This exhaustive search course of turns into more and more impractical because the variety of actions grows, resulting in substantial inefficiencies and limitations in real-world purposes the place fast and efficient decision-making is essential.
Present value-based RL strategies, together with Q-learning and its variants, face appreciable challenges in large-scale purposes. These strategies rely closely on maximizing a worth perform’s general potential actions to replace the agent’s coverage. Whereas deep Q-networks (DQN) leverage neural networks to approximate worth features, they nonetheless have to work on scalability points as a result of intensive computational sources required to guage quite a few actions in complicated environments.
Researchers from KAUST and Purdue College have launched revolutionary stochastic value-based RL strategies to handle these inefficiencies. These strategies embody Stochastic Q-learning, StochDQN, and StochDDQN, which make the most of stochastic maximization strategies. These strategies considerably scale back the computational load by contemplating solely a subset of doable actions in every iteration. This method permits for scalable options that may extra successfully deal with massive discrete motion areas.
By incorporating stochastic maximization strategies, the researchers carried out stochastic value-based RL strategies, together with Stochastic Q-learning, StochDQN, and StochDDQN. They examined these strategies on numerous datasets, together with Gymnasium environments like FrozenLake-v1 and MuJoCo management duties akin to InvertedPendulum-v4 and HalfCheetah-v4. The framework concerned changing conventional max and arg max operations with stochastic equivalents, lowering computational complexity. The evaluations demonstrated that the stochastic strategies achieved quicker convergence and better effectivity than non-stochastic strategies, dealing with as much as 4096 actions with considerably decreased computational time per step.
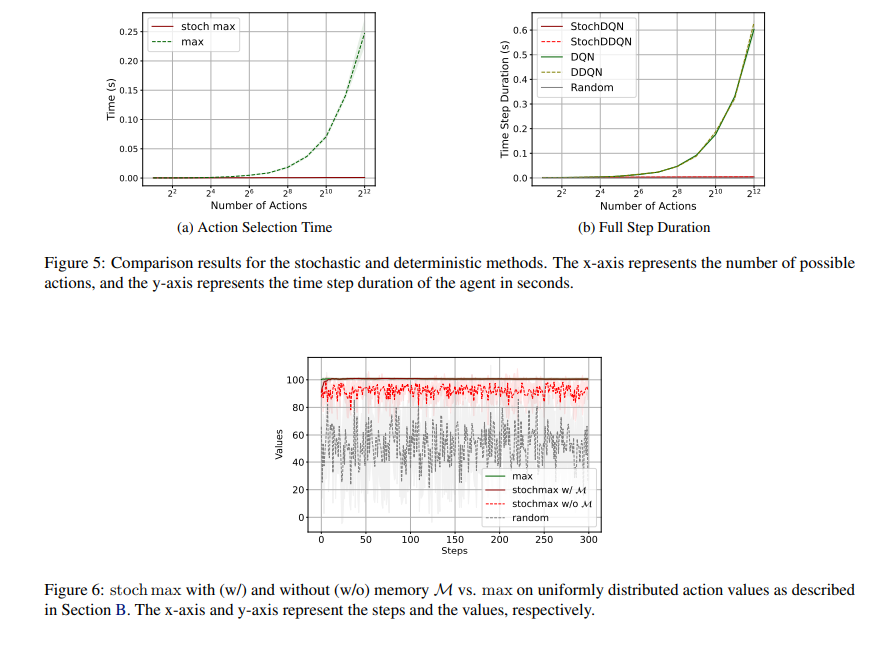
The outcomes present that stochastic strategies considerably enhance efficiency and effectivity. Within the FrozenLake-v1 surroundings, Stochastic Q-learning achieved optimum cumulative rewards in 50% fewer steps than conventional Q-learning. Within the InvertedPendulum-v4 activity, StochDQN reached a mean return of 90 in 10,000 steps, whereas DQN took 30,000 steps. For HalfCheetah-v4, StochDDQN accomplished 100,000 steps in 2 hours, whereas DDQN required 17 hours for a similar activity. Moreover, the time per step for stochastic strategies was decreased to 0.003 seconds from 0.18 seconds in duties with 1000 actions, representing a 60-fold improve in velocity. These quantitative outcomes spotlight the effectivity and effectiveness of the stochastic strategies.
To conclude, analysis introduces stochastic strategies to boost the effectivity of RL in massive discrete motion areas. By incorporating stochastic maximization, the strategies considerably scale back computational complexity whereas sustaining excessive efficiency. Examined throughout numerous environments, these strategies achieved quicker convergence and better effectivity than conventional approaches. This work is essential because it presents scalable options for real-world purposes, making RL extra sensible and efficient in complicated environments. The improvements introduced maintain vital potential for advancing RL applied sciences in various fields.
Take a look at the Paper. All credit score for this analysis goes to the researchers of this undertaking. Additionally, don’t overlook to observe us on Twitter. Be a part of our Telegram Channel, Discord Channel, and LinkedIn Group.
Should you like our work, you’ll love our e-newsletter..
Don’t Overlook to hitch our 42k+ ML SubReddit
Nikhil is an intern marketing consultant at Marktechpost. He’s pursuing an built-in twin diploma in Supplies on the Indian Institute of Expertise, Kharagpur. Nikhil is an AI/ML fanatic who’s at all times researching purposes in fields like biomaterials and biomedical science. With a powerful background in Materials Science, he’s exploring new developments and creating alternatives to contribute.
[ad_2]