[ad_1]
Massive-scale generative fashions like GPT-4, DALL-E, and Secure Diffusion have reworked synthetic intelligence, demonstrating outstanding capabilities in producing textual content, pictures, and different media. Nevertheless, as these fashions change into extra prevalent, a vital problem emerges the implications of coaching generative fashions on datasets containing their outputs. This challenge, often called mannequin collapse, poses a major risk to the long run improvement of AI. As generative fashions are educated on web-scale datasets that more and more embody AI-generated content material, researchers are combating the potential degradation of mannequin efficiency over successive iterations, probably rendering newer fashions ineffective and compromising the standard of coaching information for future AI techniques.
Current researchers have investigated mannequin collapse by means of varied strategies, together with changing actual information with generated information, augmenting mounted datasets, and mixing actual and artificial information. Most research maintained fixed dataset sizes and mixing proportions. Theoretical work has targeted on understanding mannequin habits with artificial information integration, analyzing high-dimensional regression, self-distillation results, and language mannequin output tails. Some researchers recognized part transitions in error scaling legal guidelines and proposed mitigation methods. Nevertheless, these research primarily thought-about mounted coaching information quantities per iteration. Few explored the consequences of accumulating information over time, intently resembling evolving internet-based datasets. This analysis hole highlights the necessity for additional investigation into the long-term penalties of coaching fashions on repeatedly increasing datasets that embody each actual and artificial information, reflecting the dynamic nature of web-scale data.
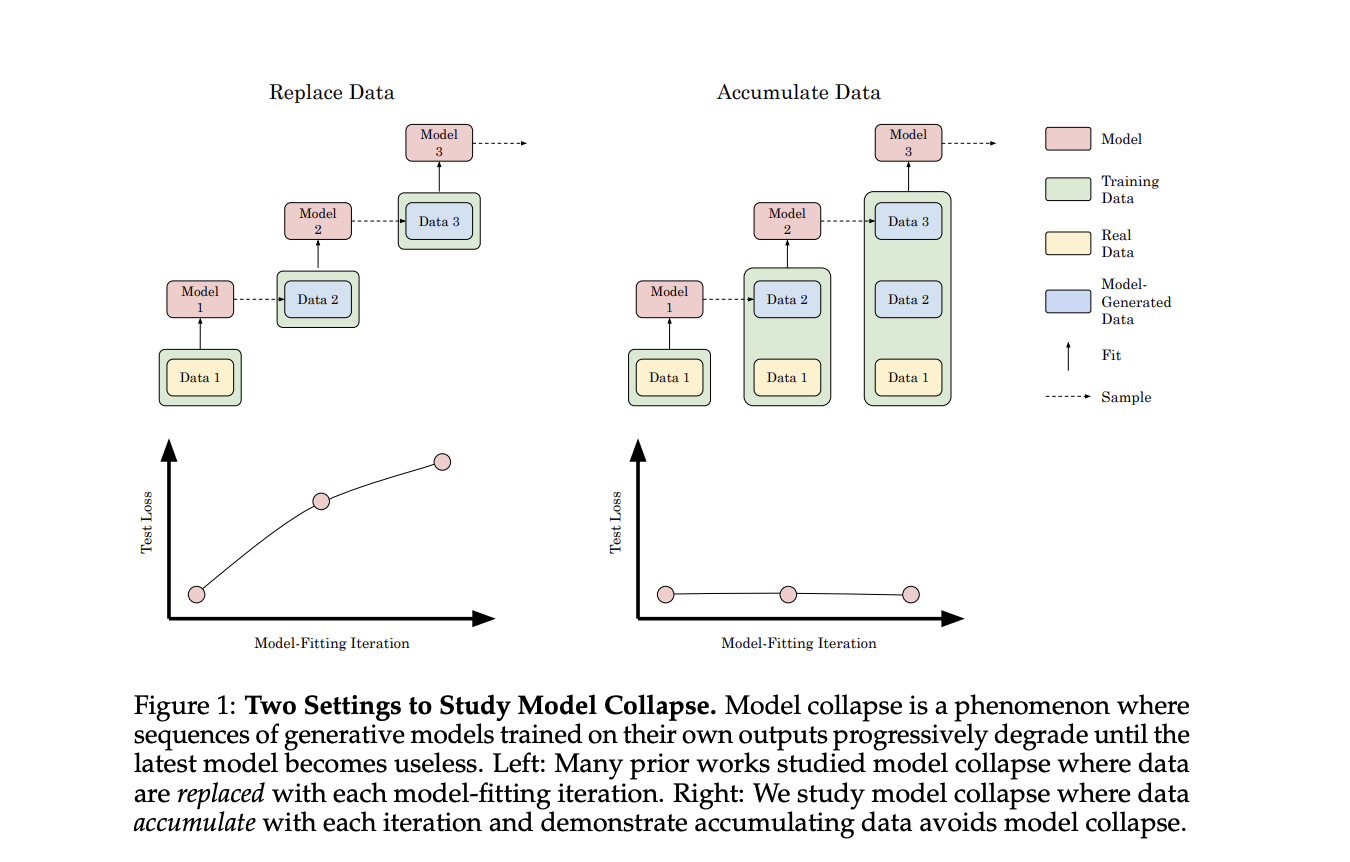
Researchers from Stanford College suggest a examine that explores the affect of accumulating information on mannequin collapse in generative AI fashions. In contrast to earlier analysis specializing in information substitute, this strategy simulates the continual accumulation of artificial information in internet-based datasets. Experiments with transformers, diffusion fashions, and variational autoencoders throughout varied information sorts reveal that accumulating artificial information with actual information prevents mannequin collapse, in distinction to the efficiency degradation noticed when changing information. The researchers lengthen current evaluation of sequential linear fashions to show that information accumulation ends in a finite, well-controlled higher certain on take a look at error, impartial of model-fitting iterations. This discovering contrasts with the linear error improve seen in information substitute situations.
Researchers experimentally investigated mannequin collapse in generative AI utilizing causal transformers, diffusion fashions, and variational autoencoders throughout textual content, molecular, and picture datasets.
- Transformer-Primarily based Causal Language Modeling:
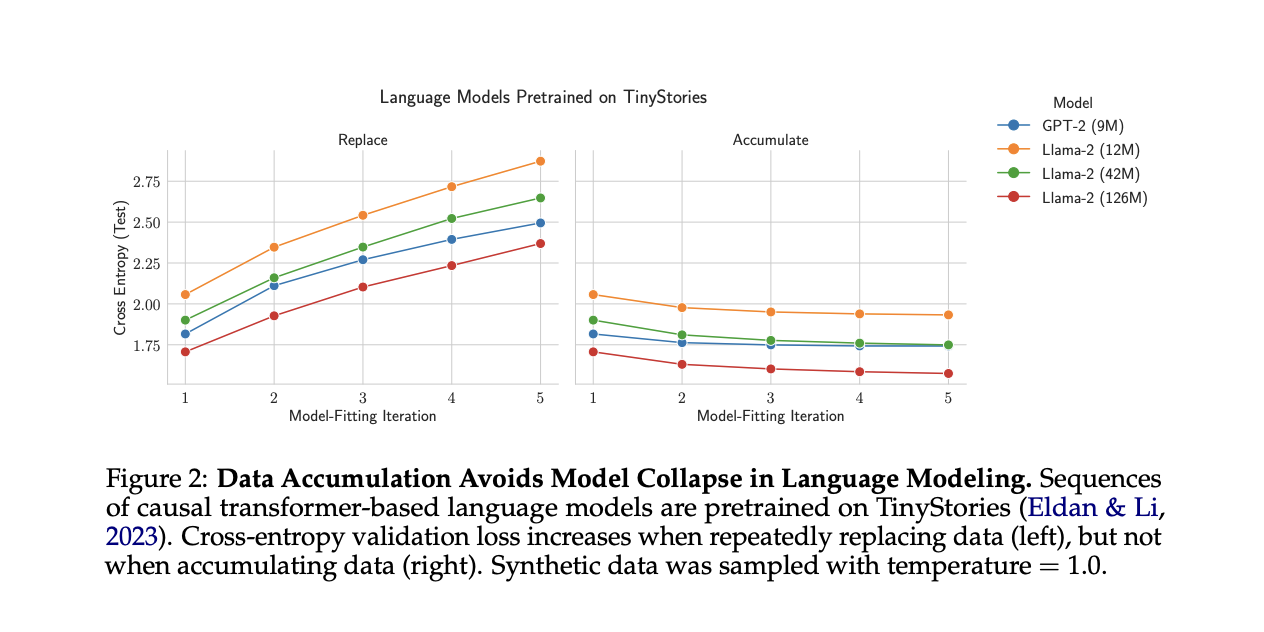
To check the mannequin collapse in transformer-based language fashions researchers used GPT-2 and Llama2 architectures of assorted sizes, pre-trained on TinyStories. They in contrast information substitute and accumulation methods over a number of iterations. Outcomes constantly confirmed that changing information elevated take a look at cross-entropy (worse efficiency) throughout all mannequin configurations and sampling temperatures. In distinction, accumulating information maintained or improved efficiency over iterations. Decrease sampling temperatures accelerated error will increase when changing information, however the total development remained constant. These findings strongly help the speculation that information accumulation prevents mannequin collapse in language modeling duties, whereas information substitute results in progressive efficiency degradation.
- Diffusion Fashions on Molecular Conformation Knowledge:
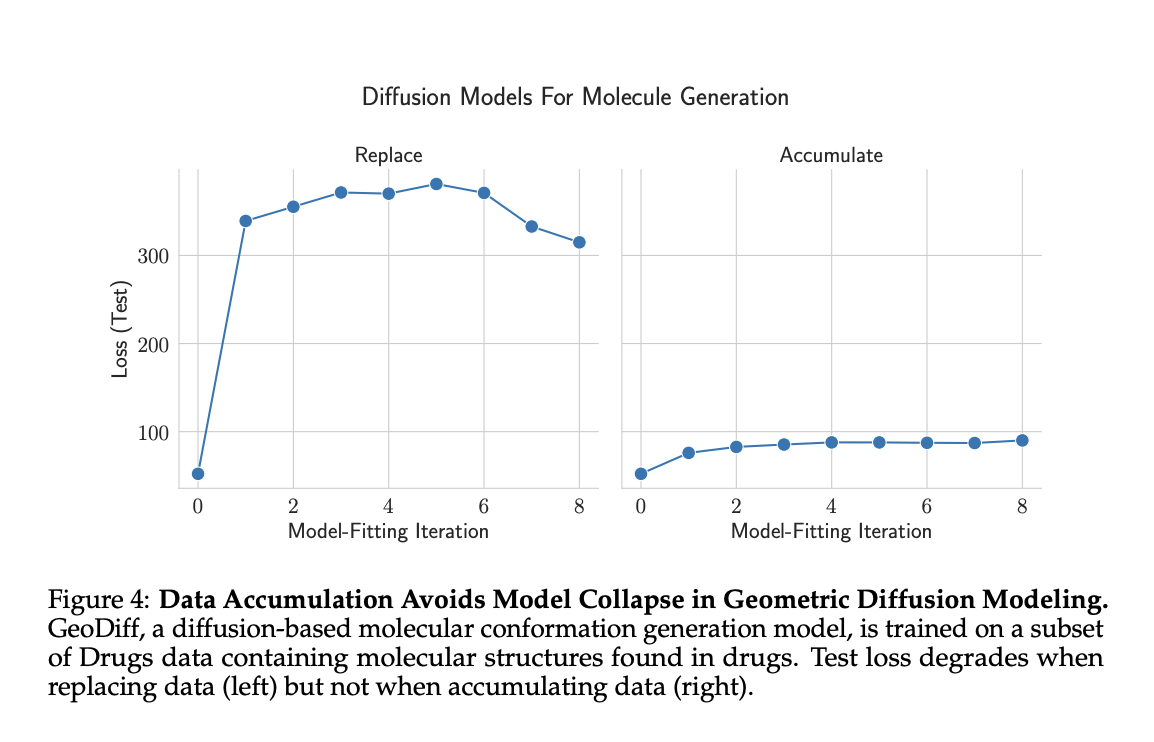
Researchers examined GeoDiff diffusion fashions on GEOM-Medicine molecular conformation information, evaluating information substitute and accumulation methods. Outcomes confirmed growing take a look at loss when changing information, however steady efficiency when accumulating information. In contrast to language fashions, vital degradation occurred primarily within the first iteration with artificial information. These findings additional help information accumulation as a technique to forestall mannequin collapse throughout totally different AI domains.
- Variational Autoencoders on Picture Knowledge (VAE)
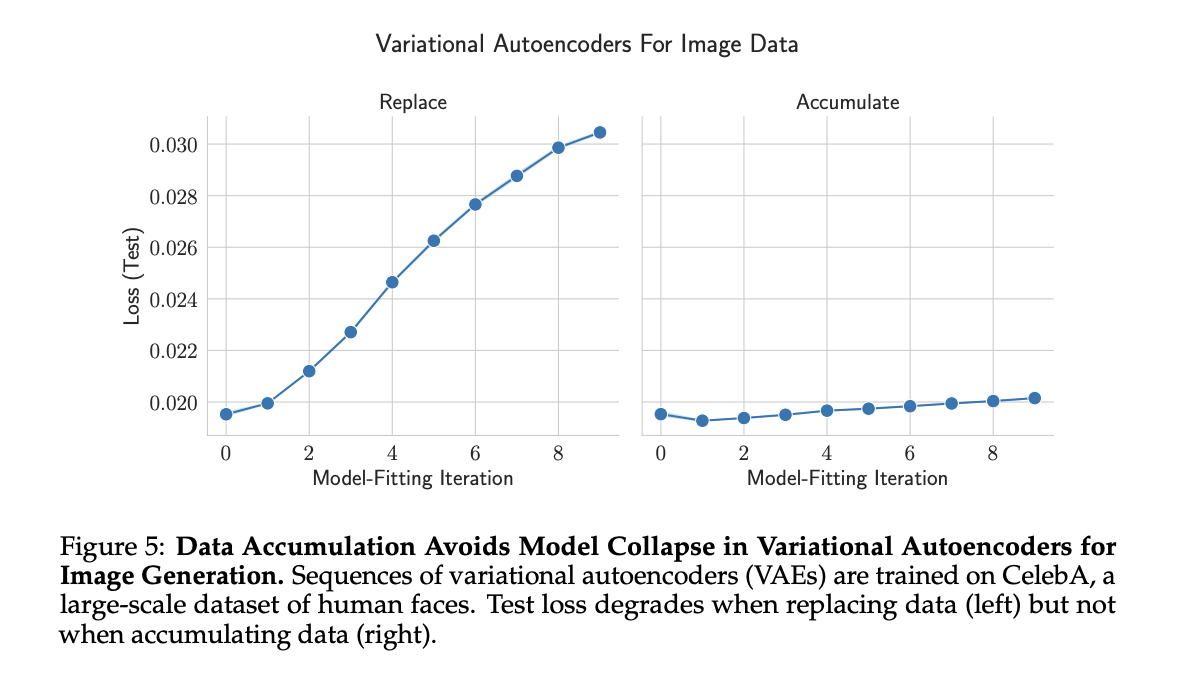
Researchers used VAEs on CelebA face pictures, evaluating information substitute and accumulation methods. Changing information led to speedy mannequin collapse, with growing take a look at error and reducing picture high quality and variety. Accumulating information considerably slowed collapse, preserving main variations however shedding minor particulars over iterations. In contrast to language fashions, accumulation confirmed slight efficiency degradation. These findings help information accumulation’s advantages in mitigating mannequin collapse throughout AI domains whereas highlighting variations in effectiveness relying on mannequin kind and dataset.

This analysis investigates mannequin collapse in AI, a priority as AI-generated content material more and more seems in coaching datasets. Whereas earlier research confirmed that coaching on mannequin outputs can degrade efficiency, this work demonstrates that mannequin collapse will be prevented by coaching on a mix of actual and artificial information. The findings, supported by experiments throughout varied AI domains and theoretical evaluation for linear regression, recommend that the “curse of recursion” could also be much less extreme than beforehand thought, so long as artificial information is amassed alongside actual information quite than changing it totally.
Take a look at the Paper. All credit score for this analysis goes to the researchers of this challenge. Additionally, don’t overlook to comply with us on Twitter and be a part of our Telegram Channel and LinkedIn Group.
In case you like our work, you’ll love our publication..
Don’t Overlook to affix our 47k+ ML SubReddit
Discover Upcoming AI Webinars right here
Asjad is an intern advisor at Marktechpost. He’s persuing B.Tech in mechanical engineering on the Indian Institute of Know-how, Kharagpur. Asjad is a Machine studying and deep studying fanatic who’s all the time researching the functions of machine studying in healthcare.
[ad_2]