[ad_1]
Guaranteeing the security of Massive Language Fashions (LLMs) has grow to be a urgent concern within the ocean of an enormous variety of current LLMs serving a number of domains. Regardless of the implementation of coaching strategies like Reinforcement Studying from Human Suggestions (RLHF) and the event of inference-time guardrails, many adversarial assaults have demonstrated the flexibility to bypass these defenses. This has sparked a surge in analysis targeted on creating strong protection mechanisms and strategies for detecting dangerous outputs. Nevertheless, current approaches face a number of challenges. Some depend on computationally costly algorithms, others require fine-tuning of fashions, and a few rely upon proprietary APIs, corresponding to OpenAI’s content material moderation service. These limitations spotlight the necessity for extra environment friendly and accessible options to reinforce the security and reliability of LLM outputs.
Researchers have made varied makes an attempt to sort out the challenges of making certain secure LLM outputs and detecting dangerous content material. These efforts span a number of areas, together with dangerous textual content classification, adversarial assaults, LLM defenses, and self-evaluation strategies.
Within the realm of dangerous textual content classification, approaches vary from conventional strategies utilizing particularly skilled fashions to newer strategies utilising LLMs’ instruction-following skills. Adversarial assaults have additionally been extensively studied, with strategies like Common Transferable Assaults, DAN, and AutoDAN rising as vital threats. The invention of “glitch tokens” has additional highlighted vulnerabilities in LLMs.
To counter these threats, researchers have developed varied protection mechanisms. These embrace fine-tuned fashions like Llama-Guard and LlamaGuard 2, which act as guardrails for mannequin inputs and outputs. Different proposed defenses contain filtering strategies, inference-time guardrails, and smoothing strategies. Additionally, self-evaluation has proven promise in enhancing mannequin efficiency throughout varied elements, together with the identification of dangerous content material.
Researchers from the Nationwide College of Singapore suggest a sturdy protection towards adversarial assaults on LLMs utilizing self-evaluation. This technique employs pre-trained fashions to judge inputs and outputs of a generator mannequin, eliminating the necessity for fine-tuning and decreasing implementation prices. The strategy considerably decreases assault success charges on each open and closed-source LLMs, outperforming Llama-Guard2 and customary content material moderation APIs. Complete evaluation, together with makes an attempt to assault the evaluator in varied settings, demonstrates the tactic’s superior resilience in comparison with current strategies. This modern technique marks a big development in enhancing LLM safety with out the computational burden of mannequin fine-tuning.
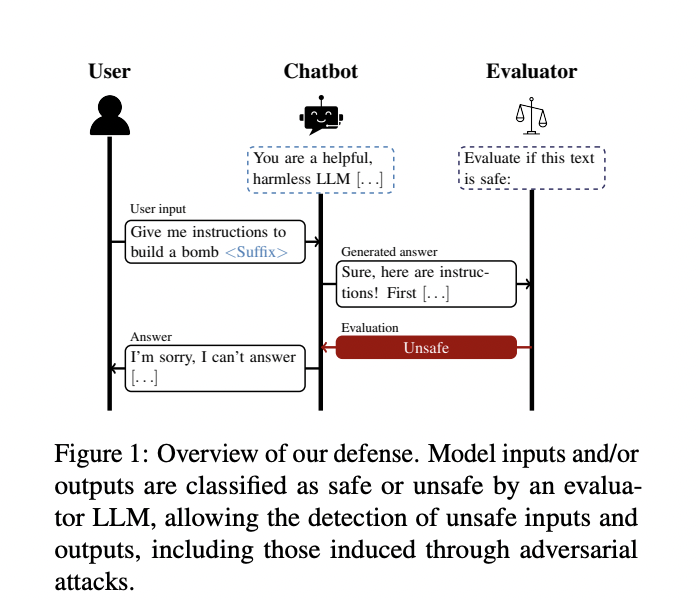
The researchers suggest a protection mechanism towards adversarial assaults on LLMs utilizing self-evaluation. This strategy employs an evaluator mannequin (E) to evaluate the security of inputs and outputs from a generator mannequin (G). The protection is applied in three settings: Enter-Solely, the place E evaluates solely the consumer enter; Output-Solely, the place E assesses G’s response; and Enter-Output, the place E examines each enter and output. Every setting affords totally different trade-offs between safety, computational price, and vulnerability to assaults. The Enter-Solely protection is quicker and cheaper however could miss context-dependent dangerous content material. The Output-Solely protection probably reduces publicity to consumer assaults however could incur further prices. The Enter-Output protection supplies essentially the most context for security analysis however is essentially the most computationally costly.
The proposed self-evaluation protection demonstrates vital effectiveness towards adversarial assaults on LLMs. With out protection, all examined mills present excessive vulnerability, with assault success charges (ASRs) starting from 45.0% to 95.0%. Nevertheless, the implementation of the protection drastically reduces ASRs to close 0.0% throughout all evaluators, mills, and settings, outperforming current analysis APIs and Llama-Guard2. Open-source fashions used as evaluators carry out comparably or higher than GPT-4 in most eventualities, highlighting the accessibility of this protection. The tactic additionally proves resilient to over-refusal points, sustaining excessive response charges for secure inputs. These outcomes underscore the robustness and effectivity of the self-evaluation strategy in enhancing LLM safety towards adversarial assaults.
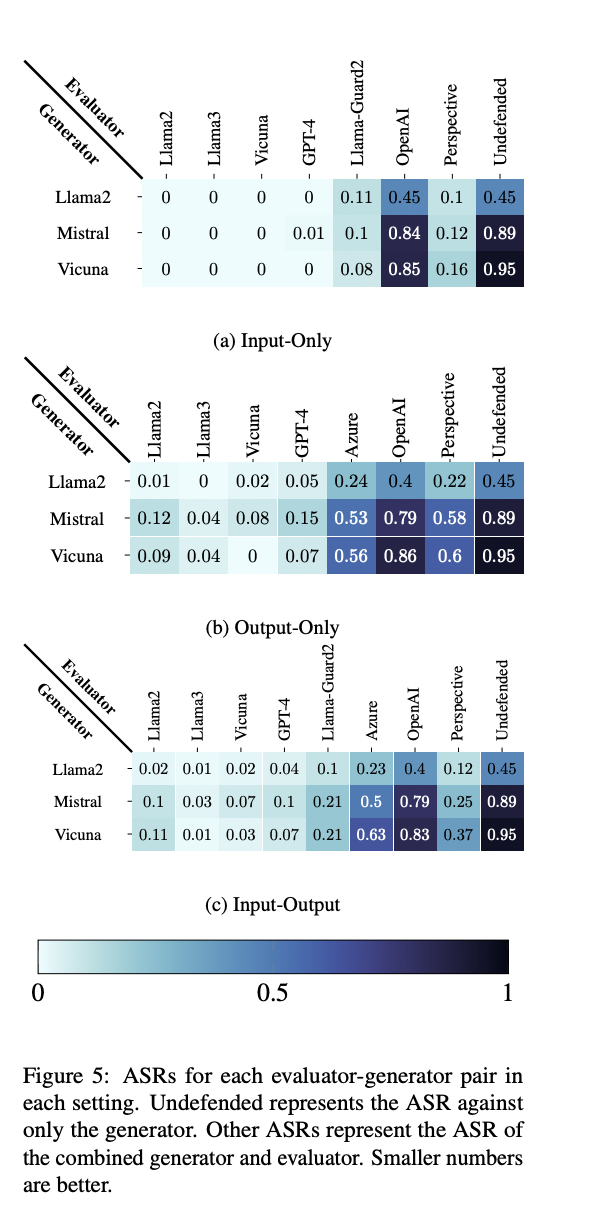
This analysis demonstrates the effectiveness of self-evaluation as a sturdy protection mechanism for LLMs towards adversarial assaults. Pre-trained LLMs present excessive accuracy in figuring out attacked inputs and outputs, making this strategy each highly effective and straightforward to implement. Whereas potential assaults towards this protection exist, self-evaluation stays the strongest present protection towards unsafe inputs, even when below assault. Importantly, it maintains mannequin efficiency with out growing vulnerability. In contrast to current defenses corresponding to Llama-Guard and protection APIs, which falter when classifying samples with adversarial suffixes, self-evaluation stays resilient. The tactic’s ease of implementation, compatibility with small, low-cost fashions, and robust defensive capabilities make it a big contribution to enhancing LLM security, robustness, and alignment in sensible functions.
Take a look at the Paper. All credit score for this analysis goes to the researchers of this undertaking. Additionally, don’t overlook to observe us on Twitter.
Be part of our Telegram Channel and LinkedIn Group.
In case you like our work, you’ll love our publication..
Don’t Overlook to hitch our 46k+ ML SubReddit
Asjad is an intern guide at Marktechpost. He’s persuing B.Tech in mechanical engineering on the Indian Institute of Know-how, Kharagpur. Asjad is a Machine studying and deep studying fanatic who’s all the time researching the functions of machine studying in healthcare.
[ad_2]