[ad_1]
Giant language fashions (LLMs) have proven outstanding capabilities in NLP, performing duties corresponding to translation, summarization, and question-answering. These fashions are important in advancing how machines work together with human language, however evaluating their efficiency stays a major problem as a result of immense computational sources required.
One of many major points in evaluating LLMs is the excessive price related to utilizing intensive benchmark datasets. Historically, benchmarks like HELM and AlpacaEval encompass 1000’s of examples, making the analysis course of computationally costly and environmentally and financially demanding. As an example, evaluating a single LLM on HELM can price over 4,000 GPU hours, translating to over $10,000. These excessive prices hinder the flexibility to steadily assess and enhance LLMs, particularly as these fashions develop in measurement and complexity.
Present strategies for evaluating LLMs contain utilizing large-scale benchmarks corresponding to MMLU, which accommodates roughly 14,000 examples. Whereas these benchmarks are complete, they might be extra environment friendly. They’ve been exploring methods to cut back the variety of examples wanted for correct analysis. That is the place the idea of “tinyBenchmarks” comes into play. By specializing in a curated subset of examples, researchers intention to take care of accuracy whereas considerably decreasing the price and time required for analysis.
The analysis staff from the College of Michigan, the College of Pompeu Fabra, IBM Analysis, MIT, and the MIT-IBM Watson AI Lab launched tinyBenchmarks. These smaller variations of standard benchmarks are designed to supply dependable efficiency estimates utilizing fewer examples. For instance, their evaluation confirmed that evaluating an LLM on simply 100 curated examples from the MMLU benchmark can predict its efficiency with a median error of beneath 2%. This strategy drastically reduces the sources wanted for analysis whereas offering correct outcomes.
The researchers used a number of methods to develop these tinyBenchmarks. One technique includes stratified random sampling, the place examples are chosen to characterize completely different information teams evenly. One other strategy is clustering primarily based on mannequin confidence, the place examples more likely to be appropriately or incorrectly predicted by the LLM are grouped. The staff utilized merchandise response idea (IRT), a statistical mannequin historically utilized in psychometrics, to measure the latent talents required to reply to benchmark examples. By clustering these representations, they created strong analysis units that might successfully estimate efficiency.
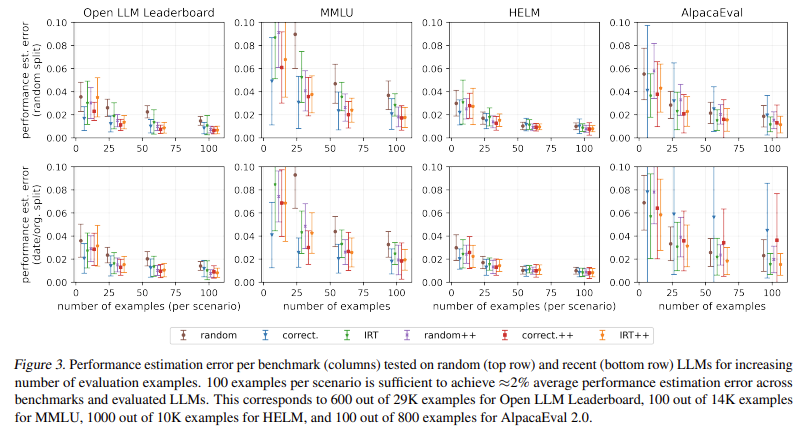
The proposed technique has demonstrated effectiveness throughout numerous benchmarks, together with the Open LLM Leaderboard, HELM, and AlpacaEval 2.0. By evaluating LLMs on simply 100 examples, the researchers achieved dependable efficiency estimates with an error margin of round 2%. This important discount within the variety of required examples interprets to substantial financial savings in computational and monetary prices.
The efficiency of those tinyBenchmarks was additional validated by way of intensive testing. As an example, the accuracy of predictions on the MMLU benchmark utilizing solely 100 examples was inside 1.9% of the true accuracy throughout all 14,000. This stage of precision confirms that tinyBenchmarks are environment friendly and extremely dependable. The analysis staff has publicly made these instruments and datasets accessible, permitting different researchers and practitioners to learn from their work.

In conclusion, tinyBenchmarks addresses the excessive computational and monetary prices related to conventional benchmarks by decreasing the variety of examples wanted for correct efficiency estimation. The analysis gives a sensible answer for frequent and environment friendly analysis of LLMs, enabling steady enchancment in NLP applied sciences.
Take a look at the Paper, GitHub, HF Fashions, and Colab Pocket book. All credit score for this analysis goes to the researchers of this venture. Additionally, don’t overlook to observe us on Twitter and be a part of our Telegram Channel and LinkedIn Group. Should you like our work, you’ll love our e-newsletter..
Don’t Overlook to affix our 47k+ ML SubReddit
Discover Upcoming AI Webinars right here
Asif Razzaq is the CEO of Marktechpost Media Inc.. As a visionary entrepreneur and engineer, Asif is dedicated to harnessing the potential of Synthetic Intelligence for social good. His most up-to-date endeavor is the launch of an Synthetic Intelligence Media Platform, Marktechpost, which stands out for its in-depth protection of machine studying and deep studying information that’s each technically sound and simply comprehensible by a large viewers. The platform boasts of over 2 million month-to-month views, illustrating its recognition amongst audiences.

[ad_2]