[ad_1]
In recent times, picture technology has made important progress as a result of developments in each transformers and diffusion fashions. Much like tendencies in generative language fashions, many trendy picture technology fashions now use normal picture tokenizers and de-tokenizers. Regardless of exhibiting nice success in picture technology, picture tokenizers encounter basic limitations as a result of manner they’re designed. These tokenizers are primarily based on the idea that the latent house ought to retain a 2D construction to take care of a direct mapping for places between the latent tokens and picture patches.
This paper discusses three present strategies within the realm of picture processing and understanding. Firstly, Picture Tokenization has been a basic method for the reason that early days of deep studying, using autoencoders to compress high-dimensional photos into low-dimensional latent representations after which decode them again. The second method is Tokenization for Picture Understanding, which is used for picture understanding duties akin to picture classification, object detection, segmentation, and multimodal giant language fashions (MLLMs). Final is the Picture Technology, during which strategies have developed from sampling variational autoencoders (VAEs) to using generative adversarial networks (GANs), diffusion fashions, and autoregressive fashions.
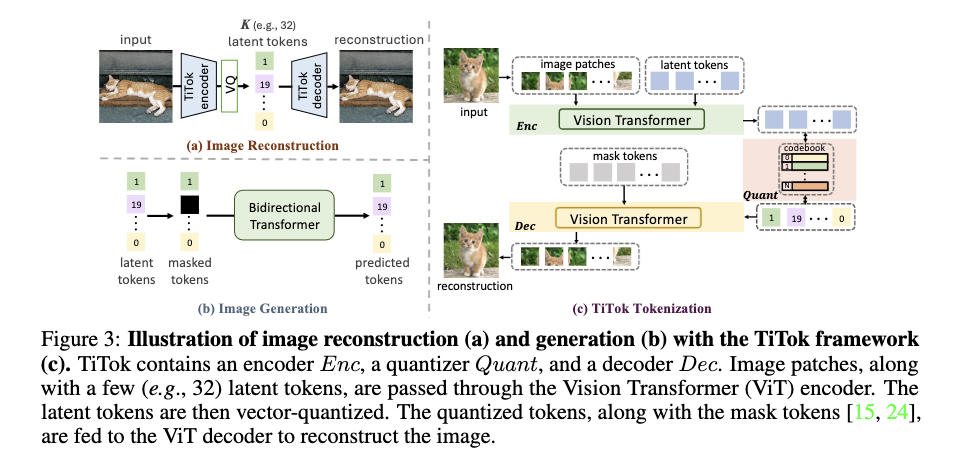
Researchers from Technical College Munich and ByteDance have proposed an modern method that tokenizes photos into 1D latent sequences, named Transformer-based 1-Dimensional Tokenizer (TiTok). TiTok consists of a Imaginative and prescient Transformer (ViT) encoder, a ViT decoder, and a vector quantizer, much like typical Vector-Quantized (VQ) mannequin designs. In the course of the tokenization part, the picture is split into patches, that are then flattened and mixed right into a 1D sequence of latent tokens. After the ViT encoder processes the picture options, the ensuing latent tokens kind the picture’s latent illustration.
Together with the Picture Technology activity utilizing a tokenizer, TiTok additionally reveals its effectivity in picture technology through the use of a typical pipeline. For the technology framework, MaskGIT is used due to its simplicity and effectiveness, which permits for coaching a MaskGIT mannequin by merely changing its VQGAN tokenizer with TiTok mannequin. The method begins by pre-tokenizing the picture into 1D discrete tokens, and a random ratio of the latent tokens is changed with masks tokens at every coaching step. After that, a bidirectional transformer takes this masked token sequence as enter and predicts the corresponding discrete token IDs for the masked tokens.
TiTok supplies a extra compact manner for latent illustration, making it far more environment friendly than conventional strategies. For instance, a 256 × 256 × 3 picture will be decreased to only 32 discrete tokens, in comparison with the 256 or 1024 tokens utilized by earlier strategies. Utilizing the identical generator framework, TiTok achieves a gFID rating of 1.97, outperforming the MaskGIT baseline by 4.21 on the ImageNet 256 × 256 benchmark. TiTok’s benefits are much more important at larger resolutions. On the ImageNet 512 × 512 benchmark, TiTok not solely outperforms the main diffusion mannequin DiT-XL/2 but additionally reduces the variety of picture tokens by 64 occasions, leading to a technology course of that’s 410 occasions sooner.
On this paper, researchers have launched an modern methodology that tokenizes photos into 1D latent sequences known as TiTok. It may be used for reconstructing and producing pure photos. A compact formulation is supplied to tokenize a picture right into a 1D latent sequence. The proposed methodology can characterize a picture with 8 to 64 occasions fewer tokens than the generally used 2D tokenizers. Furthermore, the compact 1D tokens improve the coaching and inference velocity of the technology mannequin, in addition to get hold of a aggressive FID on the ImageNet benchmarks. The longer term course will deal with extra environment friendly picture illustration and technology fashions with 1D picture tokenization.
Take a look at the Paper and Venture. All credit score for this analysis goes to the researchers of this mission. Additionally, don’t neglect to observe us on Twitter.
Be a part of our Telegram Channel and LinkedIn Group.
Should you like our work, you’ll love our e-newsletter..
Don’t Neglect to hitch our 44k+ ML SubReddit

Sajjad Ansari is a ultimate 12 months undergraduate from IIT Kharagpur. As a Tech fanatic, he delves into the sensible functions of AI with a deal with understanding the impression of AI applied sciences and their real-world implications. He goals to articulate complicated AI ideas in a transparent and accessible method.
[ad_2]