[ad_1]

Hyperparameters decide how nicely your neural community learns and processes data. Mannequin parameters are realized throughout coaching. Not like these parameters, hyperparameters should be set earlier than the coaching course of begins. On this article, we’ll describe the strategies for optimizing the hyperparameters within the fashions.
Hyperparameters In Neural Networks
Studying Price
The training price tells the mannequin how a lot to alter based mostly on its errors. If the educational price is excessive, the mannequin learns rapidly however may make errors. If the educational price is low, the mannequin learns slowly however extra fastidiously. This results in much less errors and higher accuracy.
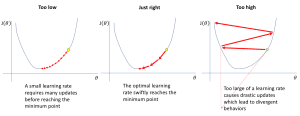 Supply: https://www.jeremyjordan.me/nn-learning-rate/
Supply: https://www.jeremyjordan.me/nn-learning-rate/There are methods of adjusting the educational price to realize the most effective outcomes potential. This includes adjusting the educational price at predefined intervals throughout coaching. Moreover, optimizers just like the Adam allows a self-tuning of the educational price in keeping with the execution of the coaching.
Batch Measurement
Batch measurement is the variety of coaching samples a mannequin undergoes at a given time. A big batch measurement mainly signifies that the mannequin goes by extra samples earlier than the parameter replace. It could actually result in extra steady studying however requires extra reminiscence. A smaller batch measurement then again updates the mannequin extra incessantly. On this case, studying may be sooner however it has extra variation in every replace.
The worth of the batch measurement impacts reminiscence and processing time for studying.
Variety of Epochs
Epochs refers back to the variety of instances a mannequin goes by the whole dataset throughout coaching. An epoch contains a number of cycles the place all the info batches are proven to the mannequin, it learns from it, and optimizes its parameters. Extra epochs are higher in studying the mannequin but when not nicely noticed they can lead to overfitting. Deciding the proper variety of epochs is critical to realize a very good accuracy. Strategies like early stopping are generally used to search out this stability.
Activation Perform
Activation features determine whether or not a neuron ought to be activated or not. This results in non-linearity within the mannequin. This non-linearity is useful particularly whereas attempting to mannequin advanced interactions within the information.
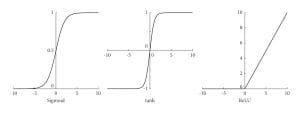 Supply: https://www.researchgate.web/publication/354971308/determine/fig1/AS:1080246367457377@1634562212739/Curves-of-the-Sigmoid-Tanh-and-ReLu-activation-functions.jpg
Supply: https://www.researchgate.web/publication/354971308/determine/fig1/AS:1080246367457377@1634562212739/Curves-of-the-Sigmoid-Tanh-and-ReLu-activation-functions.jpgWidespread activation features embrace ReLU, Sigmoid and Tanh. ReLU makes the coaching of neural networks sooner because it permits solely the optimistic activations in neurons. Sigmoid is used for assigning chances because it outputs a price between 0 and 1. Tanh is advantageous particularly when one doesn’t need to use the entire scale which ranges from 0 to ± infinity. The collection of a proper activation perform requires cautious consideration because it dictates whether or not the community shall be capable of make a very good prediction or not.
Dropout
Dropout is a method which is used to keep away from overfitting of the mannequin. It randomly deactivates or “drops out” some neurons by setting their outputs to zero throughout every coaching iteration. This course of prevents neurons from relying too closely on particular inputs, options, or different neurons. By discarding the results of particular neurons, dropout helps the community to give attention to important options within the course of of coaching. Dropout is usually carried out throughout coaching whereas it’s disabled within the inference section.
Hyperparameter Tuning Strategies
Handbook Search
This methodology includes trial and error of values for parameters that decide how the educational means of a machine studying mannequin is finished. These settings are adjusted one by one to watch the way it influences the mannequin’s efficiency. Let’s attempt to change the settings manually to get higher accuracy.
learning_rate = 0.01
batch_size = 64
num_layers = 4
mannequin = Mannequin(learning_rate=learning_rate, batch_size=batch_size, num_layers=num_layers)
mannequin.match(X_train, y_train)
Handbook search is straightforward as a result of you don’t require any difficult algorithms to manually set parameters for testing. Nonetheless, it has a number of disadvantages as in comparison with different strategies. It could actually take numerous time and it could not discover the perfect settings effectively than the automated strategies
Grid Search
Grid search exams many alternative combos of hyperparameters to search out the most effective ones. It trains the mannequin on a part of the info. After that, it checks how nicely it does with one other half. Let’s implement grid search utilizing GridSearchCV to search out the most effective mannequin .
from sklearn.model_selection import GridSearchCV
param_grid = {
'learning_rate': [0.001, 0.01, 0.1],
'batch_size': [32, 64, 128],
'num_layers': [2, 4, 8]
}
grid_search = GridSearchCV(mannequin, param_grid, cv=5)
grid_search.match(X_train, y_train)
Grid search is way sooner than handbook search. Nonetheless, it’s computationally costly as a result of it takes time to test each potential mixture.
Random Search
This method randomly selects combos of hyperparameters to search out probably the most environment friendly mannequin. For every random mixture, it trains the mannequin and checks how nicely it performs. On this method, it will probably rapidly arrive at good settings that trigger the mannequin to carry out higher. We will implement random search utilizing RandomizedSearchCV to realize the most effective mannequin on the coaching information.
from sklearn.model_selection import RandomizedSearchCV
from scipy.stats import uniform, randint
param_dist = {
'learning_rate': uniform(0.001, 0.1),
'batch_size': randint(32, 129),
'num_layers': randint(2, 9)
}
random_search = RandomizedSearchCV(mannequin, param_distributions=param_dist, n_iter=10, cv=5)
random_search.match(X_train, y_train)
Random search is generally higher than the grid search since only some variety of hyperparameters are checked to get appropriate hyperparameters settings. Nonetheless, it may not search the proper mixture of hyperparameters significantly when the working hyperparameters area is giant.
Wrapping Up
We have coated a few of the fundamental hyperparameter tuning strategies. Superior strategies embrace Bayesian Optimization, Genetic Algorithms and Hyperband.
Jayita Gulati is a machine studying fanatic and technical author pushed by her ardour for constructing machine studying fashions. She holds a Grasp’s diploma in Laptop Science from the College of Liverpool.
[ad_2]