[ad_1]
We’re releasing an API for accessing AI fashions developed by Unbabel to guage translation high quality. These fashions are extensively established because the state-of-the-art and are behind Unbabel’s successful submissions to the WMT Shared Duties in 2022 and 2023, outperforming methods from Microsoft, Google and Alibaba.
Now you can request entry with a purpose to combine this API into your translation product.
Learn on to study:
- What’s High quality Estimation (QE) and the way it can influence language operations
- How QE fashions get skilled and the function of high quality datasets
- Particular examples of how what you are promoting can profit from the QI API
- What sort of high quality report information you may get utilizing Unbabel’s QI API, supporting excessive degree selections in addition to granular enhancements
- Tips on how to entry and make the most of the API right this moment
Computerized translation high quality analysis, often called High quality Estimation (QE), is an AI system that’s skilled to determine errors in translation and to measure the standard of any given translation with out human involvement. The perception that QE supplies, instantaneously and at scale, permits any enterprise to get transparency into the standard of all their multilingual content material on an ongoing foundation.
Supported with each excessive degree high quality scores and granular translation-by-translation reporting, companies could make broad changes, in addition to surgical enhancements, to their translation method.
The Unbabel fashions accessed by the API are constructed with our industry-standard COMET know-how, that are persistently acknowledged because the most correct and fine-grained of their class. These Unbabel fashions we offer entry to through the API are of even better accuracy than their state-of-the-art open supply counterparts.
How will we ship better accuracy? That is all all the way down to the Unbabel proprietary information used to coach the mannequin, a results of years of assortment and curation by Unbabel’s skilled annotators. These datasets complete tens of millions of translations overlaying a variety of languages, domains, and content material varieties, and crucially, the information catalogs the myriad methods during which translations can fail and might succeed.

How can what you are promoting profit ?
- You’re using a multi-vendor technique on your translations and wish to get visibility into the standard of the assorted translation suppliers
- Your group has an inner group of translators that you simply wish to audit for high quality
- You will have developed your personal machine translation methods and wish to implement your personal dynamic human-in-the-loop workflow, both in actual time or asynchronously
What information does the API present?
The High quality Intelligence API supplies the consumer with direct entry to Unbabel’s QE fashions, which offer predictions on two ranges:
- translation analysis, and;
- error rationalization of a particular translation analysis
Translation analysis returns a translation error evaluation following the MQM framework (Multidimensional High quality Metric). The prediction lists the detected errors categorized by severity (minor, main and significant), and summarizes the general translation high quality as a quantity between 0 (worst) and 100 (greatest), each at for sentence and at for the entire doc.
Error rationalization provides an in depth error-by-error evaluation. It labels the kind of error, identifies the a part of the supply textual content that’s mistranslated, suggests a correction that fixes the mistranslation, and supplies rationalization of this on the degree of the error, the sentence, and the doc.
Collectively, these predictions present the consumer with holistic perception into translation high quality, from the very best degree of aggregated MQM scores to the granularity of particular person error evaluation and rationalization. It’s this twin reporting that lets customers make excessive degree selections in addition to granular enhancements to make vital enhancements.
Why does computerized high quality analysis matter?
At Unbabel now we have frequently and persistently invested in QE. We imagine QE permits accountable use of AI-centric translation at scale, which is the current and way forward for the language {industry}.
Machine Translation (MT) is a robust instrument, particularly when augmented by context-rich information and complementary algorithms performing language-related duties within the translation course of. Nevertheless, with out visibility into MT high quality, companies won’t ever know if their translations ship worth, and whether or not or the place to spend the time and money to make enhancements. Till a catastrophic mistranslation reaches the client, in fact. With QE, there’s no must compromise on high quality, since companies can decide which computerized translation wants human correction, and which is nice as is. We imagine that that is accountable use of Machine Translation.
Skilled human translation can even profit from QE. With errors flagged upfront, translators can deal with excellent errors, letting them direct time and a spotlight to vital segments as an alternative of huge swaths of already appropriate translations. This can be a large effectivity improve that human translators can seize right this moment.
API Reporting Examples
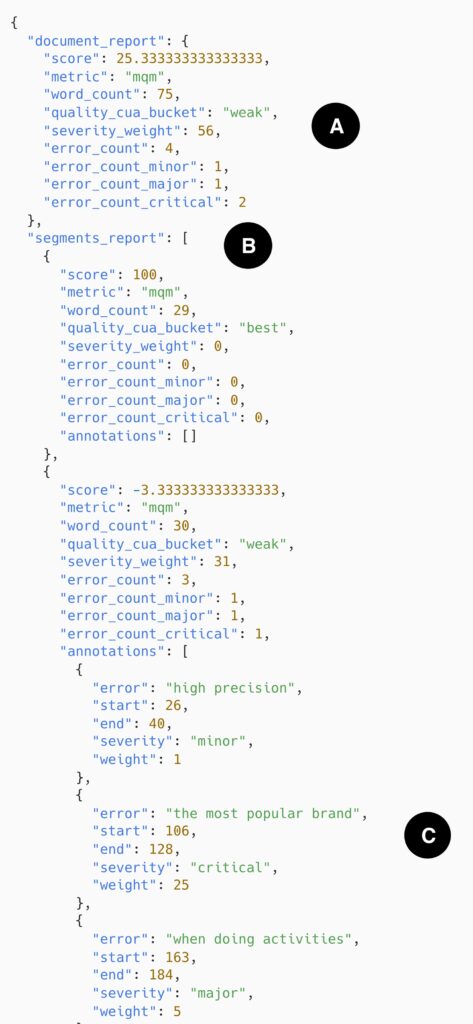
A – The consumer supplies a translated doc consisting of three translated segments
B – The consumer specifies that the interpretation is predicted to be from Chinese language (Simplified) to English (British) and in a casual register(These instance translations are taken from the check set of the WMT23 QE shared process.)

Analysis
A – The general translation high quality of this doc is predicted to be very low. With 4 errors, 2 of that are vital, the interpretation obtains an MQM rating of 25 out of 100, incomes it the label “weak”
B – Breaking down the analysis per phase reveals us that the errors are concentrated within the final two sentences, with the primary sentence deemed to be of excellent high quality
C – The error span annotations listing the errors that decided the analysis rating. The error spans find the error textual content, their severity, and the penalty (weight) that severity incurs. The MQM rating is computed from the sum of those severity weights (1 + 25 + 5 = 31) and is normalized by the variety of phrases (30) following the components (1 – 31 / 30) * 100 = -3.33. This components additionally applies on the degree of the doc, utilizing the doc complete severity weight and phrase rely.
Rationalization endpoint
A – The reason prediction explains – at every degree of the evaluation
B – The prediction additionally supplies advised corrections at every degree of the evaluation
C – Every error is categorized following an error typology and the a part of supply textual content concerned within the mistranslation is supplied for every recognized error

Entry the API
[ad_2]