[ad_1]
Language fashions (LMs) exhibit improved efficiency with elevated measurement and coaching knowledge, but the connection between mannequin scale and hallucinations stays unexplored. Defining hallucinations in LMs presents challenges as a consequence of their diverse manifestations. A brand new research from Google Deepmind focuses on hallucinations the place right solutions seem verbatim in coaching knowledge. Attaining low hallucination charges calls for bigger fashions and extra computational sources than beforehand thought. Hallucination detection turns into more and more tough as LM measurement grows. Data graphs (KGs) provide a promising strategy to offering structured, factual coaching knowledge for LMs, doubtlessly mitigating hallucinations.
The research investigates the connection between the language mannequin (LM) scale and hallucinations, specializing in situations the place right solutions are current within the coaching knowledge. Utilizing a data graph (KG)–based mostly dataset, researchers prepare more and more giant LMs to manage coaching content material successfully. Findings point out that bigger, longer-trained LMs hallucinate much less, however reaching low hallucination charges requires considerably extra sources than beforehand thought. The research additionally reveals an inverse relationship between the LM scale and hallucination detectability.
Exactly defining and quantifying hallucinations in pure language settings stays difficult as a consequence of language ambiguity and unclear data content material in coaching knowledge. Regardless of developments in generative capabilities, hallucinations persist as a major problem for LMs. The analysis addresses the hole in understanding how hallucinations depend upon mannequin scale. Data graphs provide a structured strategy to LM coaching, enabling easy truth verification in opposition to the dataset and offering a quantifiable measure of hallucination.
Conventional language fashions (LMs) educated on pure language knowledge usually produce hallucinations and repetitive info as a consequence of semantic ambiguity. The research employs a data graph (KG) strategy, utilizing structured triplets of knowledge to supply a clearer understanding of how LMs misrepresent coaching knowledge. This technique permits for a extra exact analysis of hallucinations and their relationship to mannequin scale.
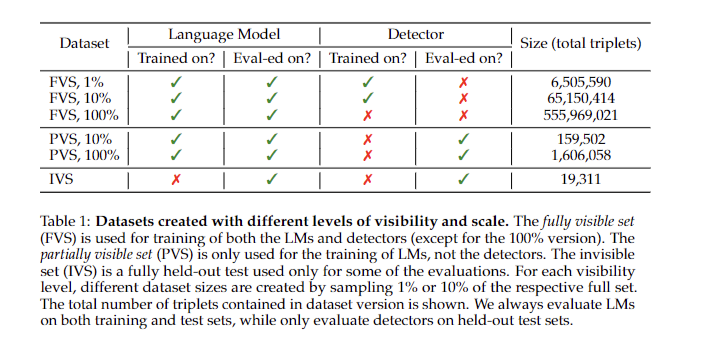
The research constructs a dataset utilizing data graph triplets (topic, predicate, object), enabling exact management over coaching knowledge and quantifiable hallucination measurement. Language fashions (LMs) are educated from scratch on this dataset, optimizing auto-regressive log-likelihood. Analysis entails prompting fashions with topic and predicate, and assessing object completion accuracy in opposition to the data graph. Token duties and head detectors consider hallucination detection efficiency. The methodology focuses on hallucinations the place right solutions seem verbatim within the coaching set, exploring the connection between the LM scale and hallucination frequency.
The analysis trains more and more giant LMs to analyze scale results on hallucination charges and detectability. Evaluation reveals that bigger, longer-trained LMs hallucinate much less, although bigger datasets could improve hallucination charges. The authors acknowledge limitations in generalizability to all hallucination varieties and using smaller-than-state-of-the-art fashions. This complete strategy gives insights into LM hallucinations and their detectability, contributing to the sector of pure language processing.
The research reveals that bigger language fashions and prolonged coaching scale back hallucinations on mounted datasets, whereas elevated dataset measurement elevates hallucination charges. Hallucination detectors present excessive accuracy, bettering with mannequin measurement. Token-level detection typically outperforms different strategies. A trade-off exists between truth recall and generalization capacity, with prolonged coaching minimizing hallucinations on seen knowledge however risking overfitting on unseen knowledge. AUC-PR serves as a dependable measure of detector efficiency. These findings spotlight the advanced relationship between mannequin scale, dataset measurement, and hallucination charges, emphasizing the significance of balancing mannequin measurement and coaching period to mitigate hallucinations whereas addressing challenges posed by bigger datasets.
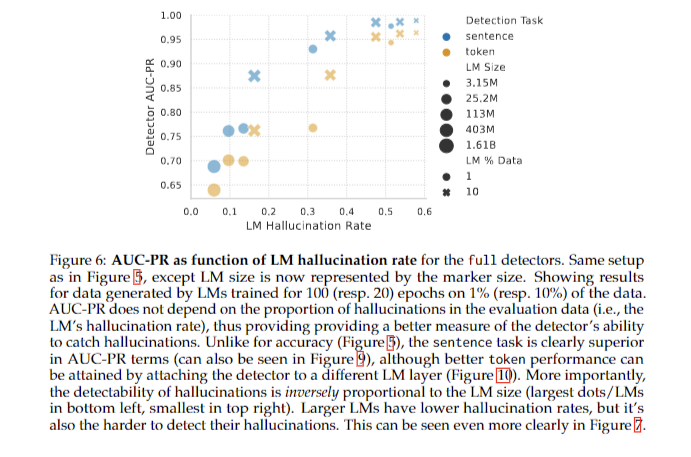
In conclusion, the research reveals that bigger, longer-trained language fashions exhibit lowered hallucination charges, however reaching minimal hallucinations requires substantial computational sources. Elevated dataset measurement correlates with increased hallucination charges when mannequin measurement and coaching epochs stay fixed. A trade-off exists between memorization and generalization, with prolonged coaching bettering truth retention however doubtlessly hindering adaptability to new knowledge. Paradoxically, as fashions develop bigger and hallucinate much less, detecting remaining hallucinations turns into tougher. Future analysis ought to deal with enhancing hallucination detection in bigger fashions and exploring the sensible implications of those findings for language mannequin purposes.
Take a look at the Paper. All credit score for this analysis goes to the researchers of this challenge. Additionally, don’t overlook to comply with us on Twitter and be part of our Telegram Channel and LinkedIn Group. For those who like our work, you’ll love our e-newsletter..
Don’t Neglect to hitch our 48k+ ML SubReddit
Discover Upcoming AI Webinars right here

Shoaib Nazir is a consulting intern at MarktechPost and has accomplished his M.Tech twin diploma from the Indian Institute of Know-how (IIT), Kharagpur. With a robust ardour for Information Science, he’s notably within the numerous purposes of synthetic intelligence throughout numerous domains. Shoaib is pushed by a want to discover the most recent technological developments and their sensible implications in on a regular basis life. His enthusiasm for innovation and real-world problem-solving fuels his steady studying and contribution to the sector of AI

[ad_2]