[ad_1]
We’re excited to announce that Graviton, the ARM-based CPU occasion supplied by AWS, is now supported on the Databricks ML Runtime cluster. There are a number of ways in which Graviton cases present worth for machine studying workloads:
- Speedups for varied machine studying libraries: ML libraries like XGBoost, LightGBM, Spark MLlib, and Databricks Characteristic Engineering might see as much as 30-50% speedups.
- Decrease cloud vendor price: Graviton cases have decrease charges on AWS than their x86 counterparts, making their value efficiency extra interesting.
What are the advantages of Graviton for Machine Studying?
Once we examine Graviton3 processors with an x86 counterpart, third Gen Intel® Xeon® Scalable processors, we discover that Graviton3 processors speed up varied machine studying purposes with out compromising mannequin high quality.
- XGBoost and LightGBM: As much as 11% speedup when coaching classifiers for the Covertype dataset. (1)
- Databricks AutoML: Once we launched a Databricks AutoML experiment to seek out one of the best hyperparameters for the Covertype dataset, AutoML might run 63% extra hyperparameter tuning trials on Graviton3 cases than Intel Xeon cases, as a result of every trial run (utilizing libraries corresponding to XGBoost or LightGBM) completes sooner. (2) The upper variety of hyperparameter tuning runs can doubtlessly yield higher outcomes, as AutoML is ready to discover the hyperparameter search area extra exhaustively. In our AutoML experiment utilizing the Covertype dataset, after 2 hours of exploration, the experiment on Graviton3 cases might discover hyperparameter combos with a greater F1 rating.
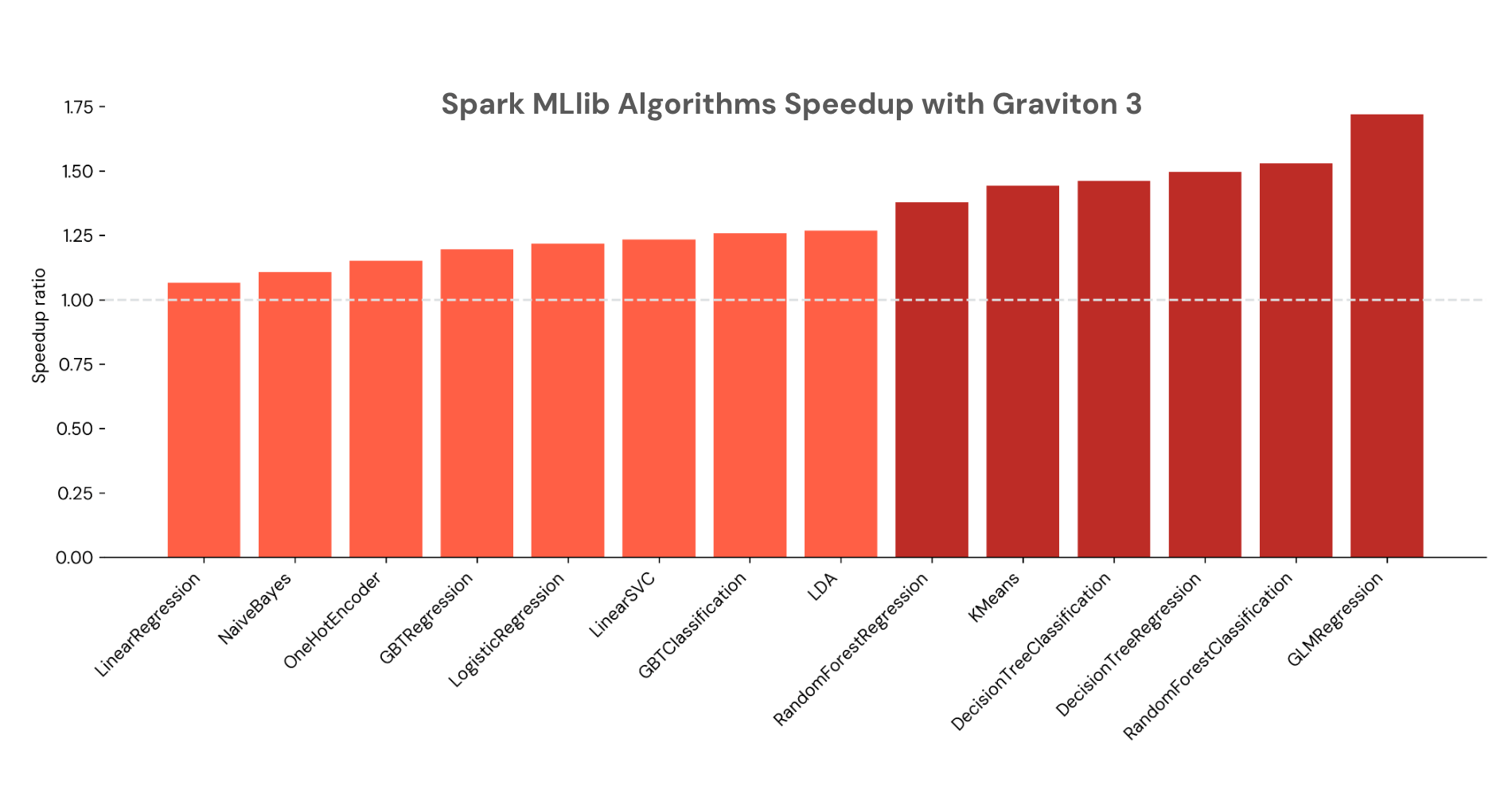
- Spark MLlib: Numerous algorithms from Spark MLlib additionally run sooner on Graviton3 processors, together with resolution bushes, random forests, gradient-boosted bushes, and extra, with as much as 1.7x speedup. (3)
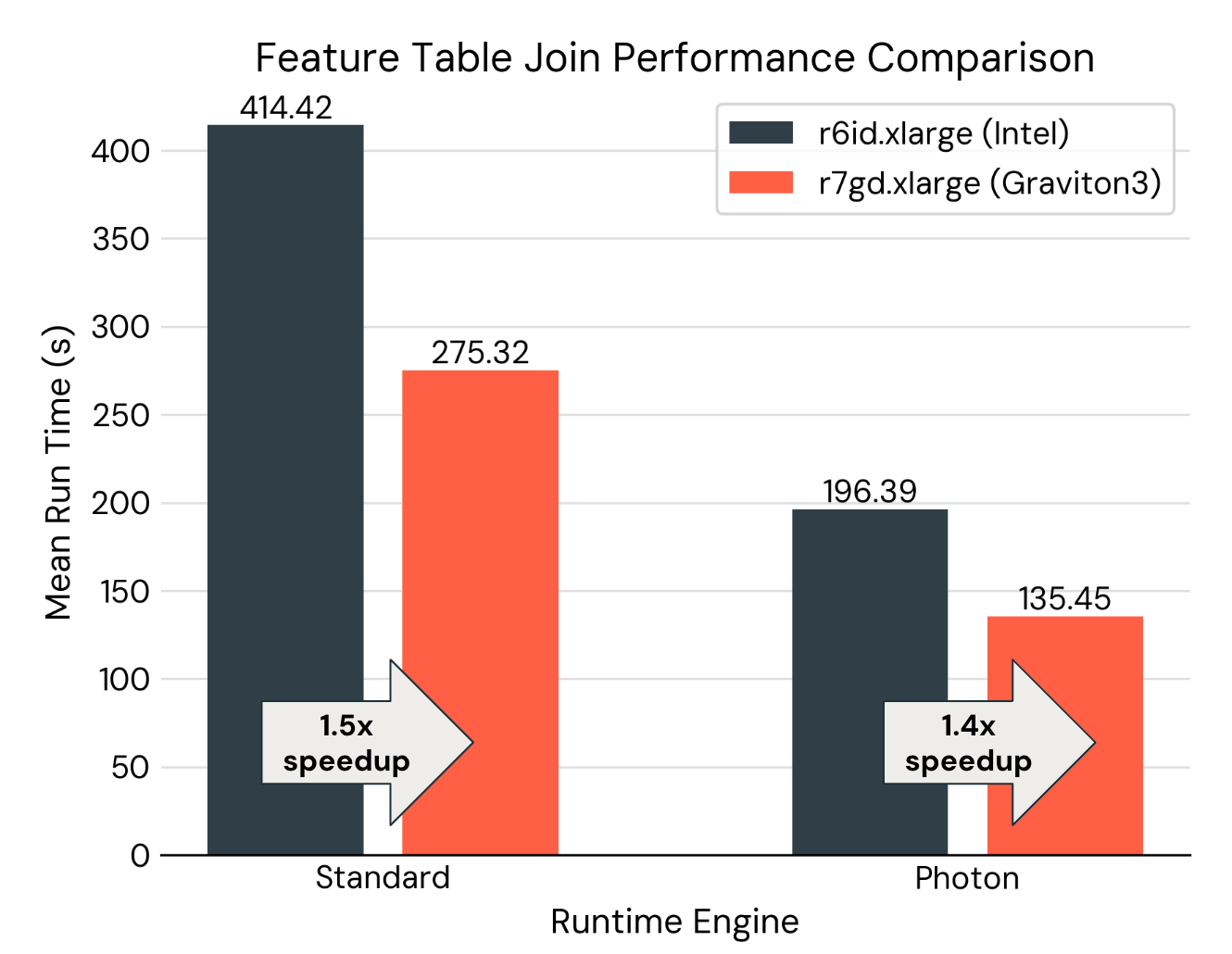
- Characteristic Engineering with Spark: Spark’s sooner velocity on Graviton3 cases makes time-series characteristic tables with a Level-in-Time be part of as much as 1.5x sooner than with third Gen Intel Xeon Scalable processors.
What about Photon + Graviton?
As talked about within the earlier weblog put up, Photon accelerates Spark SQL and Spark DataFrames APIs, which is especially helpful for characteristic engineering. Can we mix the acceleration of Photon and Graviton for Spark? The reply is sure, Graviton gives extra speedup on prime of Photon.
The determine beneath reveals the run time of becoming a member of a characteristic desk of 100M rows with a label desk. (4) Whether or not or not Photon is enabled, swapping to Graviton3 processors gives as much as a 1.5x speedup. Mixed with enabling Photon, there’s a whole of three.1x enchancment when each accelerations are enabled with Databricks Machine Studying Runtime.
Choose Machine Studying Runtime with Graviton Situations
Ranging from Databricks Runtime 15.4 LTS ML, you possibly can create a cluster with Graviton cases and Databricks Machine Studying Runtime. Choose the runtime model as 15.4 LTS ML or above; to seek for Graviton3 cases, sort in “7g” within the search field to seek out cases which have “7g” within the title, corresponding to r7gd, c7gd, and m7gd cases. Graviton2 cases (with “6g” within the occasion title) are additionally supported on Databricks, however Graviton3 is a more moderen era of processors and has higher efficiency.

To study extra about Graviton and Databricks Machine Studying Runtime, listed here are some associated documentation pages:
Notes:
- The in contrast occasion sorts are c7gd.8xlarge with Graviton3 processor, and c6id.8xlarge with third Gen Intel Xeon Scalable processor.
- Every AutoML experiment is run on a cluster with 2 employee nodes, and timeout set as 2 hours.
- Every cluster used for comparability has 8 employee nodes. The in contrast occasion sorts are m7gd.2xlarge (Graviton3) and m6id.2xlarge (third Gen Intel Xeon Scalable processors). The dataset has 1M examples and 4k options.
- The characteristic desk has 100 columns and 100k distinctive IDs, with 1000 timestamps per ID. The label desk has 100k distinctive IDs, with 100 timestamps per ID. The setup was repeated 5 instances to calculate the typical run time.
[ad_2]