[ad_1]
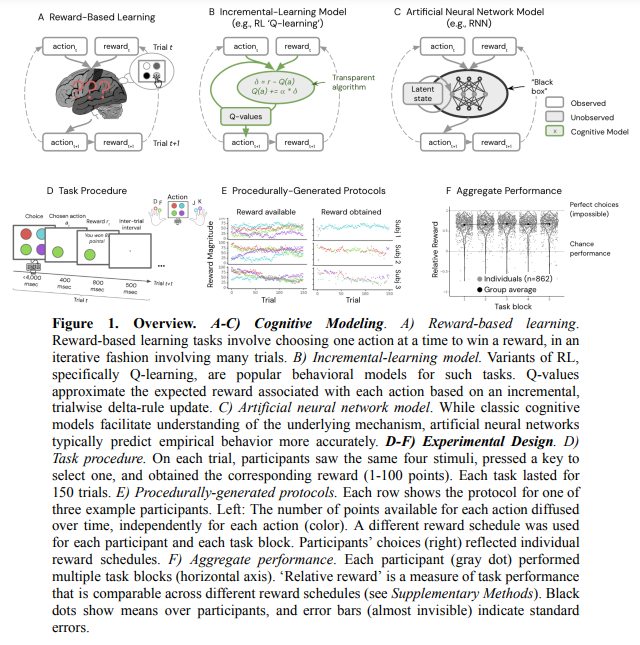
Human reward-guided studying is commonly modeled utilizing easy RL algorithms that summarize previous experiences into key variables like Q-values, representing anticipated rewards. Nonetheless, latest findings recommend that these fashions oversimplify the complexity of human reminiscence and decision-making. For example, particular person occasions and international reward statistics can considerably affect conduct, indicating that reminiscence entails extra than simply abstract statistics. ANNs, significantly RNNs, provide a extra advanced mannequin by capturing long-term dependencies and complicated studying mechanisms, although they usually should be extra interpretable than conventional RL fashions.
Researchers from establishments together with Google DeepMind, College of Oxford, Princeton College, and College School London studied human reward-learning conduct utilizing a hybrid strategy combining RL fashions with ANNs. Their findings recommend that human conduct must be adequately defined by algorithms that incrementally replace selection variables. As a substitute, human reward studying depends on a versatile reminiscence system that types advanced representations of previous occasions over a number of timescales. By iteratively changing parts of a traditional RL mannequin with ANNs, they uncovered insights into how experiences form reminiscence and information decision-making.
A dataset was gathered from a reward-learning job involving 880 contributors. On this job, contributors repeatedly selected between 4 actions, every rewarded based mostly on noisy, drifting reward magnitudes. After filtering, the research included 862 contributors and 617,871 legitimate trials. Most contributors realized the duty by persistently selecting actions with larger rewards. This in depth dataset enabled vital behavioral variance extraction utilizing RNNs and hybrid fashions, outperforming fundamental RL fashions in capturing human decision-making patterns.
The info was initially modeled utilizing a standard RL mannequin (Greatest RL) and a versatile Vanilla RNN. Greatest RL, recognized as the simplest amongst incremental-update fashions, employed a reward module to replace Q-values and an motion module for motion perseverance. Nonetheless, its simplicity restricted its expressivity. The Vanilla RNN, which processes actions, rewards, and latent states collectively, predicted selections extra precisely (68.3% vs. 58.9%). Additional hybrid fashions like RL-ANN and Context-ANN, whereas enhancing upon Greatest RL, nonetheless fell wanting Vanilla RNN. Reminiscence-ANN, incorporating recurrent reminiscence representations, matched Vanilla RNN’s efficiency, suggesting that detailed reminiscence use was key to contributors’ studying within the job.
The research reveals that conventional RL fashions, which rely solely on incrementally up to date resolution variables, must catch up in predicting human selections in comparison with a novel mannequin incorporating memory-sensitive decision-making. This new mannequin distinguishes between resolution variables that drive selections and reminiscence variables that modulate how these resolution variables are up to date based mostly on previous rewards. In contrast to RL fashions, the place resolution and studying variables are intertwined, this strategy separates them, offering a clearer understanding of how studying influences selections. The mannequin means that human data is influenced by compressed reminiscences of job historical past, reflecting each short- and long-term reward and motion histories, which modulate studying independently of how they’re carried out.
Reminiscence-ANN, the proposed modular cognitive structure, separates reward-based studying from action-based studying, supported by proof from computational fashions and neuroscience. The structure contains a “floor” stage of resolution guidelines that course of observable knowledge and a “deep” stage that handles advanced, context-rich representations. This dual-layer system permits for versatile, context-driven decision-making, suggesting that human reward studying entails easy surface-level processes and deeper memory-based mechanisms. These findings agree that advanced fashions with wealthy representations should seize the complete spectrum of human conduct, significantly in studying duties. The insights gained right here might have broader purposes, extending to varied studying duties and cognitive science.
Take a look at the Paper. All credit score for this analysis goes to the researchers of this challenge. Additionally, don’t overlook to observe us on Twitter and be part of our Telegram Channel and LinkedIn Group. When you like our work, you’ll love our e-newsletter..
Don’t Overlook to affix our 48k+ ML SubReddit
Discover Upcoming AI Webinars right here
Sana Hassan, a consulting intern at Marktechpost and dual-degree pupil at IIT Madras, is enthusiastic about making use of expertise and AI to deal with real-world challenges. With a eager curiosity in fixing sensible issues, he brings a contemporary perspective to the intersection of AI and real-life options.
[ad_2]