[ad_1]
Utilizing in depth labeled knowledge, supervised machine studying algorithms have surpassed human consultants in varied duties, resulting in considerations about job displacement, significantly in diagnostic radiology. Nevertheless, some argue that short-term job displacement is unlikely since many roles contain a spread of duties past simply prediction. People might stay important in prediction duties as they’ll be taught from fewer examples. In radiology, human experience is essential for recognizing uncommon illnesses. Equally, autonomous automobiles face challenges with uncommon eventualities, which people can deal with utilizing broader information past driving-specific knowledge.
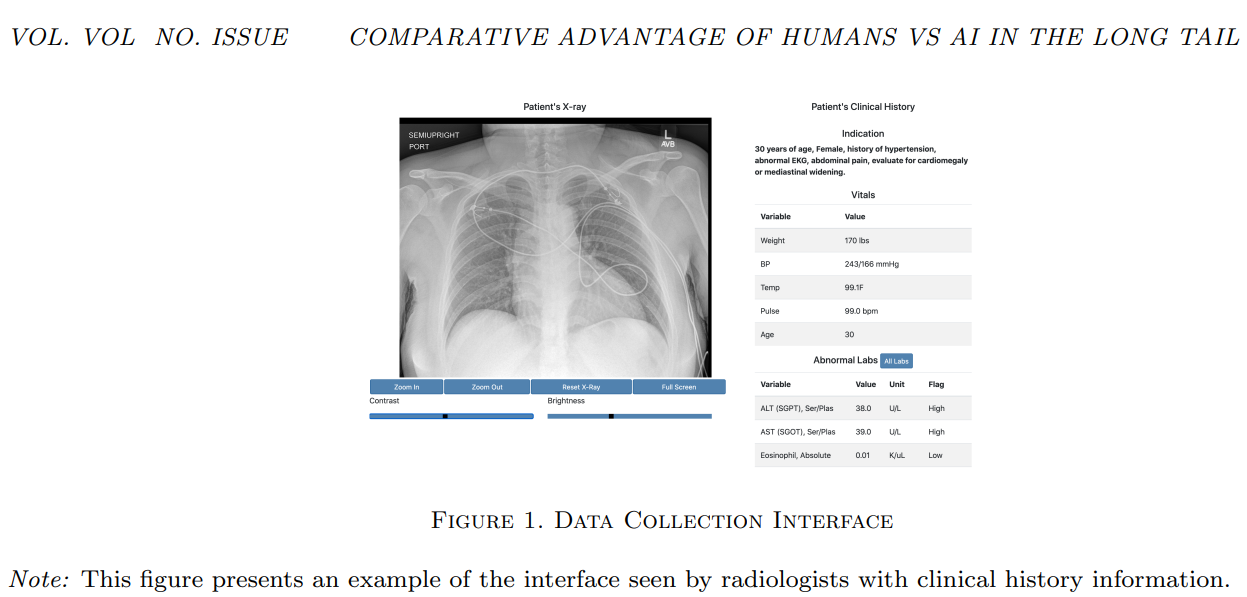
Researchers from MIT and Harvard Medical Faculty investigated whether or not zero-shot studying algorithms cut back the diagnostic benefit of human radiologists for uncommon illnesses. They in contrast the efficiency of CheXzero, a zero-shot algorithm for chest X-rays, to human radiologists and CheXpert, a standard supervised algorithm. CheXzero, educated on the MIMIC-CXR dataset, predicts a number of pathologies utilizing contrastive studying, whereas CheXpert, educated on Stanford radiographs, diagnoses twelve pathologies with express labels. Information was collected from 227 radiologists evaluating 324 circumstances from Stanford, excluding coaching knowledge circumstances, to evaluate efficiency variation with illness prevalence.
AI and radiologist efficiency is in contrast utilizing the concordance statistic (C), an extension of AUROC for steady settings. Concordance, Crt, measures the proportion of concordant pairs, calculated individually for every radiologist and pathology, then averaged to acquire Ct. AI’s concordance is denoted as CAt. Concordance is chosen for its invariance to prevalence and lack of choice dependency, making it appropriate even when no circumstances have a excessive consensus likelihood. Regardless of being an ordinal measure, it stays informative. One other efficiency metric, the deviation from consensus likelihood, is much less efficient for low-prevalence pathologies, thus influencing some conclusions.
The classification efficiency of human radiologists is in comparison with the CheXzero and CheXpert algorithms. The common prevalence of pathologies is low, round 2.42%, with some exceeding 15%. Radiologists have a mean concordance of 0.58, decrease than each AI algorithms, with CheXpert barely outperforming CheXzero. Nevertheless, CheXpert’s predictions cowl solely 12 pathologies, whereas CheXzero covers 79. Human and CheXzero performances are weakly correlated, indicating totally different focal factors in X-ray evaluation. CheXzero’s efficiency varies extensively, with concordance starting from 0.45 to 0.94, in comparison with the narrower 0.52 to 0.72 vary for human radiologists.
The research illustrates the importance of the lengthy tail in pathology prevalence, revealing that the majority related pathologies should not coated by the supervised studying algorithm studied. Whereas each human and AI efficiency improves with pathology prevalence, CheXpert exhibits substantial enhancement in larger prevalence circumstances. CheXzero’s efficiency is much less affected by prevalence, persistently outperforming people throughout all prevalence bins. Notably, CheXzero outperforms people even in low prevalence pathologies, difficult the notion of human superiority in such circumstances. Nevertheless, assessing total algorithmic efficiency requires cautious interpretation because of the complexity of changing ordinal outputs to diagnostic selections, particularly for uncommon pathologies.
Supervised machine studying algorithms have proven superiority in particular duties in comparison with people. Nevertheless, people nonetheless maintain worth resulting from their adeptness in dealing with uncommon circumstances, generally known as the lengthy tail. Zero-shot studying algorithms intention to sort out this problem by circumventing the necessity for in depth labeled knowledge. The research in contrast radiologists’ assessments to 2 main algorithms for diagnosing chest pathologies, indicating that self-supervised algorithms quickly shut the hole or surpass people in predicting uncommon illnesses. Nevertheless, challenges nonetheless should be solved in deploying algorithms, as their outputs don’t immediately translate into actionable selections, suggesting they’re extra prone to complement relatively than substitute people.
extra modalities.
Try the Paper. All credit score for this analysis goes to the researchers of this mission. Additionally, don’t neglect to observe us on Twitter. Be a part of our Telegram Channel, Discord Channel, and LinkedIn Group.
Should you like our work, you’ll love our e-newsletter..
Don’t Neglect to affix our 43k+ ML SubReddit | Additionally, try our AI Occasions Platform
Sana Hassan, a consulting intern at Marktechpost and dual-degree scholar at IIT Madras, is obsessed with making use of know-how and AI to handle real-world challenges. With a eager curiosity in fixing sensible issues, he brings a recent perspective to the intersection of AI and real-life options.
[ad_2]