[ad_1]
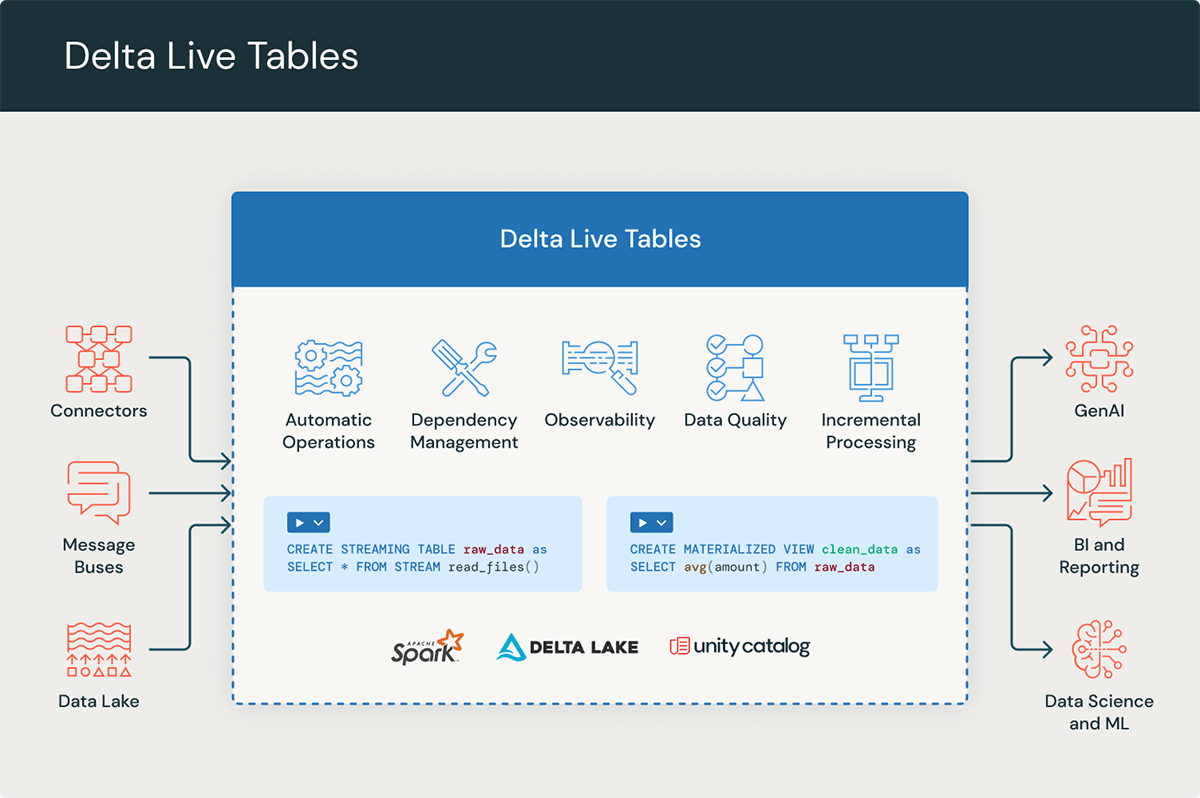
We not too long ago introduced the overall availability of serverless compute for Notebooks, Workflows, and Delta Reside Tables (DLT) pipelines. As we speak, we might like to clarify how your ETL pipelines constructed with DLT pipelines can profit from serverless compute.
DLT pipelines make it simple to construct cost-effective streaming and batch ETL workflows utilizing a easy, declarative framework. You outline the transformations in your knowledge, and DLT pipelines will routinely handle activity orchestration, scaling, monitoring, knowledge high quality, and error dealing with.
Serverless compute for DLT pipelines affords as much as 5 instances higher cost-performance for knowledge ingestion and as much as 98% value financial savings for advanced transformations. It additionally offers enhanced reliability in comparison with DLT on traditional compute. This mixture results in quick and reliable ETL at scale on Databricks. On this weblog put up, we’ll delve into how serverless compute for DLT achieves excellent simplicity, efficiency, and the bottom complete value of possession (TCO).
DLT pipelines on serverless compute are sooner, cheaper, and extra dependable
DLT on serverless compute enhances throughput, bettering reliability, and decreasing complete value of possession (TCO). This enchancment is because of its skill to carry out end-to-end incremental processing all through your complete knowledge journey—from ingestion to transformation. Moreover, serverless DLT can help a wider vary of workloads by routinely scaling compute assets vertically, which improves the dealing with of memory-intensive duties.
Simplicity
DLT pipelines simplify ETL growth by automating many of the operational complexity. This lets you give attention to delivering high-quality knowledge as a substitute of managing and sustaining pipelines.
Easy growth
- Declarative Programming: Simply construct batch and streaming pipelines for ingestion, transformation and making use of knowledge high quality expectations.
- Easy APIs: Deal with change-data-capture (CDC) for SCD sort 1 and kind 2 codecs from each streaming and batch sources.
- Information High quality: Implement knowledge high quality with expectation and leverage highly effective observability for knowledge high quality.
Easy operations
- Horizontal Autoscaling: Mechanically scale pipelines horizontally with automated orchestration and retries.
- Automated Upgrades: Databricks Runtime (DBR) upgrades are dealt with routinely, making certain you obtain the newest options and safety patches with none effort and minimal downtime.
- Serverless Infrastructure: Vertical autoscaling of assets while not having to choose occasion sorts or handle compute configurations, enabling even non-experts to function pipelines at scale.
Efficiency
DLT on serverless compute offers end-to-end incremental processing throughout your complete pipeline – from ingestion to transformation. Because of this pipelines working on serverless compute will execute sooner and have decrease total latency as a result of knowledge is processed incrementally for each ingestion and sophisticated transformations. Key advantages embrace:
- Quick Startup: Eliminates chilly begins because the serverless fleet ensures compute is all the time obtainable when wanted.
- Improved Throughput: Enhanced ingestion throughput with stream pipeline for activity parallelization.
- Environment friendly Transformations: Enzyme cost-based optimizer powers quick and environment friendly transformations for materialized views.
Low TCO
In DLT utilizing serverless compute, knowledge is processed incrementally, enabling workloads with massive, advanced materialized views (MVs) to profit from lowered total knowledge processing instances. The serverless mannequin makes use of elastic billing, that means solely the precise time spent processing knowledge is billed. This eliminates the necessity to pay for unused occasion capability or monitor occasion utilization. With DLT on serverless compute, the advantages embrace:
- Environment friendly Information Processing: Incremental ingestion with streaming tables and incremental transformation with materialized views.
- Environment friendly Billing: Billing happens solely when compute is assigned to workloads, not for the time required to amass and arrange assets.
“Serverless DLT pipelines halve execution instances with out compromising prices, improve engineering effectivity, and streamline advanced knowledge operations, permitting groups to give attention to innovation fairly than infrastructure in each manufacturing and growth environments.”
— Cory Perkins, Sr. Information & AI Engineer, Qorvo
“We opted for DLT particularly to spice up developer productiveness, in addition to the embedded knowledge high quality framework and ease of operation. The provision of serverless choices eases the overhead on engineering upkeep and value optimization. This transfer aligns seamlessly with our overarching technique to migrate all pipelines to serverless environments inside Databricks.”
— Bala Moorthy, Senior Information Engineering Supervisor, Compass
Let us take a look at a few of these capabilities in additional element:
Finish-to-end incremental processing
Information processing in DLT happens at two phases: ingestion and transformation. In DLT, ingestion is supported by streaming tables, whereas knowledge transformations are dealt with by materialized views. Incremental knowledge processing is essential for reaching the most effective efficiency on the lowest value. It is because, with incremental processing, assets are optimized for each studying and writing: solely knowledge that has modified because the final replace is learn, and present knowledge within the pipeline is just touched if vital to attain the specified consequence. This method considerably improves value and latency in comparison with typical batch-processing architectures.
Streaming tables have all the time supported incremental processing for ingestion from cloud recordsdata or message buses, leveraging Spark Structured Streaming know-how for environment friendly, exactly-once supply of occasions.
Now, DLT with serverless compute allows the incremental refresh of advanced MV transformations, permitting for end-to-end incremental processing throughout the ETL pipeline in each ingestion and transformation.
Higher knowledge freshness at decrease value with incremental refresh of materialized views
Absolutely recomputing massive MVs can turn into costly and incur excessive latency. Beforehand with a view to do incremental processing for advanced transformation customers solely had one possibility: write difficult MERGE and forEachBatch() statements in PySpark to implement incremental processing within the gold layer.
DLT on serverless compute routinely handles incremental refreshing of MVs as a result of it features a cost-based optimizer (“Enzyme”) to routinely incrementally refresh materialized views with out the person needing to put in writing advanced logic. Enzyme reduces the price and considerably improves latency to hurry up the method of doing ETL. This implies which you can have higher knowledge freshness at a a lot decrease value.
Based mostly on our inside benchmarks on a 200 billion row desk, Enzyme can present as much as 6.5x higher throughput and 85% decrease latency than the equal MV refresh on DLT on traditional compute.
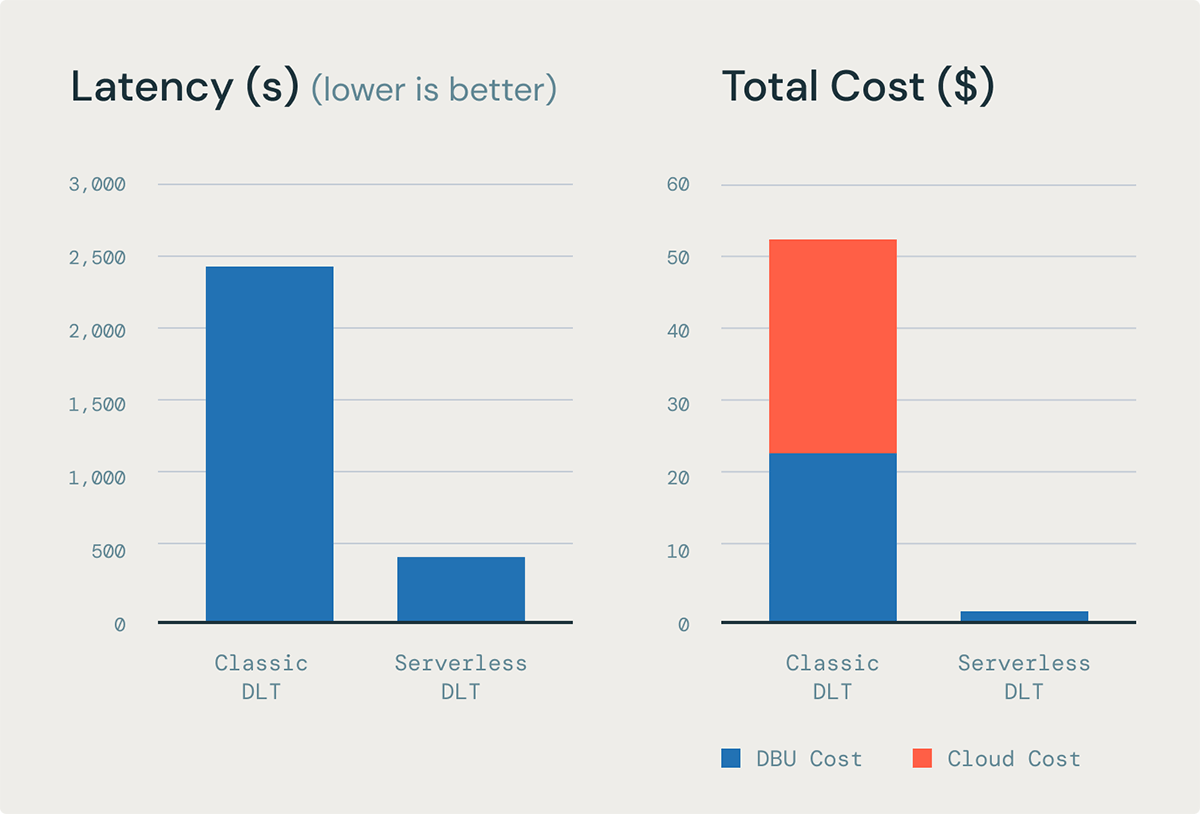
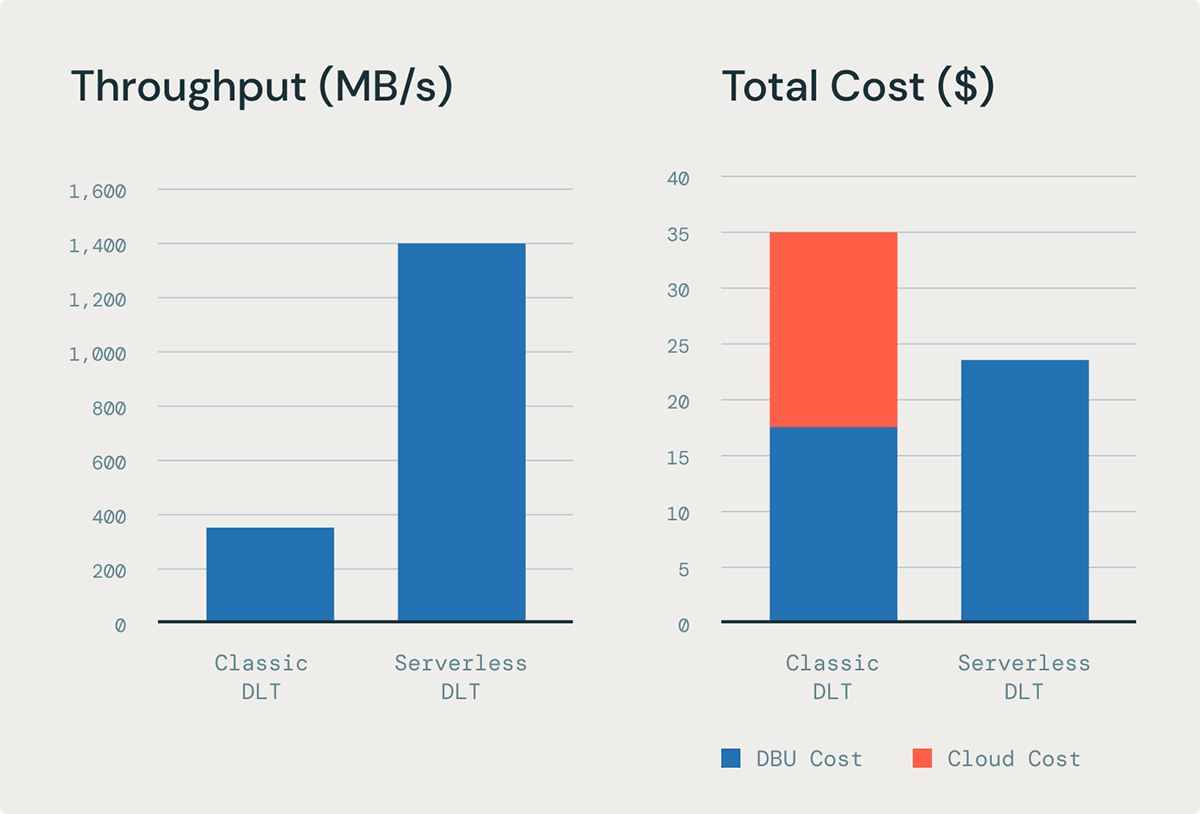
Quicker, cheaper ingestion with stream pipelining
Streaming pipelining improves the throughput of loading recordsdata and occasions in DLT when utilizing streaming tables. Beforehand, with traditional compute, it was difficult to totally make the most of occasion assets as a result of some duties would end early, leaving slots idle. Stream pipelining with DLT on serverless compute solves this by enabling SparkTM Structured Streaming (the know-how that underpins streaming tables) to concurrently course of micro-batches. All of this results in important enhancements of streaming ingestion latency with out rising value.
Based mostly on our inside benchmarks of loading 100K JSON recordsdata utilizing DLT, stream pipelining can present as much as 5x higher worth efficiency than the equal ingestion workload on a DLT traditional pipeline.
Allow memory-intensive ETL workloads with computerized vertical scaling
Choosing the proper occasion sort for optimum efficiency with altering, unpredictable knowledge volumes – particularly for giant, advanced transformations and streaming aggregations – is difficult and infrequently results in overprovisioning. When transformations require extra reminiscence than obtainable, it may trigger out-of-memory (OOM) errors and pipeline crashes. This necessitates manually rising occasion sizes, which is cumbersome, time-consuming, and leads to pipeline downtime.
DLT on serverless compute addresses this with computerized vertical auto-scaling of compute and reminiscence assets. The system routinely selects the suitable compute configuration to satisfy the reminiscence necessities of your workload. Moreover, DLT will scale down by decreasing the occasion dimension if it determines that your workload requires much less reminiscence over time.

DLT on serverless compute is prepared now
DLT on serverless compute is accessible now, and we’re constantly working to enhance it. Listed here are some upcoming enhancements:
- Multi-Cloud Assist: At present obtainable on Azure and AWS, with GCP help in public preview and GA bulletins later this yr.
- Continued Optimization for Value and Efficiency: Whereas at the moment optimized for quick startup, scaling, and efficiency, customers will quickly be capable of prioritize targets like decrease value.
- Personal Networking and Egress Controls: Connect with assets inside your non-public community and management entry to the general public web.
- Enforceable Attribution: Tag notebooks, workflows, and DLT pipelines to assign prices to particular value facilities, comparable to for chargebacks.
Get began with DLT on serverless compute in the present day
To begin utilizing DLT on serverless compute in the present day:
[ad_2]