[ad_1]
Causal impact estimation is essential for understanding the affect of interventions in numerous domains, similar to healthcare, social sciences, and economics. This space of analysis focuses on figuring out how adjustments in a single variable trigger adjustments in one other, which is crucial for knowledgeable decision-making. Conventional strategies typically contain intensive knowledge assortment and structured experiments, which might be time-consuming and expensive.
The need for structured knowledge and guide knowledge curation hinders present approaches to causal impact estimation. This requirement will increase the fee and time of research and limits the scope of knowledge that may be analyzed. Unstructured knowledge, similar to pure language textual content from social media or boards, represents a wealthy however underutilized supply of data for causal evaluation.
Conventional strategies for estimating causal results embody randomized managed trials (RCTs) and observational research. RCTs are thought of the gold commonplace however are sometimes costly and impractical for a lot of interventions. Observational research use current knowledge however require it to be structured and freed from confounding variables. Widespread strategies embody inverse propensity rating weighting and end result imputation, which adjusts for biases within the knowledge.
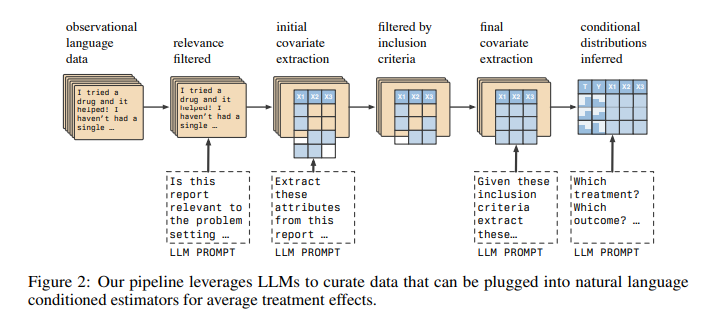
Researchers from the College of Toronto, Vector Institute, and Meta AI launched NATURAL, a novel household of causal impact estimators leveraging massive language fashions (LLMs) to investigate unstructured textual content knowledge. This methodology permits for extracting causal data from various sources similar to social media posts, medical experiences, and affected person boards. By automating knowledge curation and leveraging the capabilities of LLMs, NATURAL gives a scalable resolution for numerous purposes.
NATURAL makes use of LLMs to course of pure language textual content and estimate the conditional distributions of variables of curiosity. The method entails filtering related experiences, extracting covariates and coverings, and utilizing these to compute common therapy results (ATEs). The tactic mimics conventional causal inference strategies however operates on unstructured knowledge, making it a flexible and scalable resolution. The pipeline entails a number of steps:
- Preliminary filtering to take away irrelevant experiences.
- Extracting therapy and end result data.
- Guaranteeing the experiences meet particular inclusion standards.
This ends in a dataset that may estimate causal results precisely.
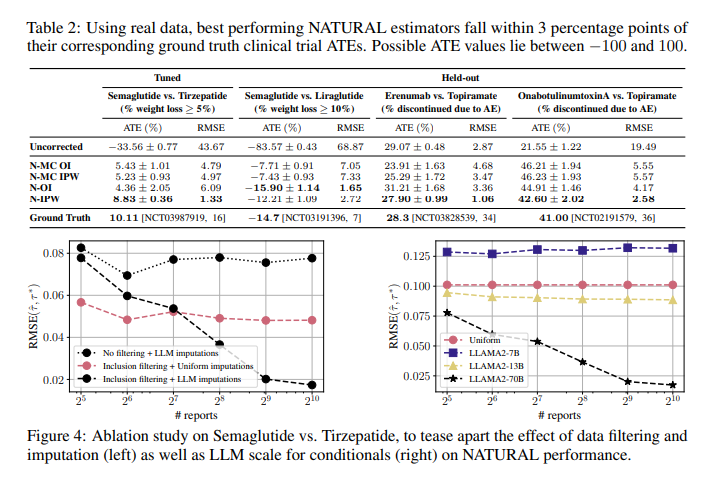
The proposed NATURAL estimators demonstrated exceptional accuracy, with estimated ATEs falling inside three share factors of floor reality values from randomized experiments. Particularly, the tactic was examined on six datasets, together with artificial datasets and real-world medical trial knowledge. For the Semaglutide vs. Tirzepatide dataset, NATURAL precisely predicted weight reduction outcomes with a imply absolute error of two.5%. The method additionally demonstrated sturdy efficiency in predicting outcomes for diabetes and migraine therapies, reaching excessive consistency with medical trial outcomes. The price of computational evaluation was considerably decrease, at just a few hundred {dollars}, in comparison with conventional strategies.
NATURAL’s capability to precisely estimate causal results from unstructured knowledge suggests a transformative potential for fields that rely closely on causal evaluation. By leveraging freely obtainable textual content knowledge, this methodology can considerably cut back the time and price related to conventional causal impact estimation strategies. The method is especially precious for purposes the place randomized trials are infeasible or too costly.
In conclusion, the NATURAL framework presents a groundbreaking method to causal impact estimation utilizing unstructured pure language knowledge. By automating knowledge curation and leveraging LLMs, researchers offered a scalable resolution that might revolutionize fields reliant on causal evaluation. This methodology addresses present limitations and opens new avenues for using wealthy, unstructured knowledge sources.
Try the Paper and GitHub. All credit score for this analysis goes to the researchers of this undertaking. Additionally, don’t overlook to comply with us on Twitter and be part of our Telegram Channel and LinkedIn Group. In case you like our work, you’ll love our publication..
Don’t Neglect to hitch our 47k+ ML SubReddit
Discover Upcoming AI Webinars right here
Nikhil is an intern guide at Marktechpost. He’s pursuing an built-in twin diploma in Supplies on the Indian Institute of Know-how, Kharagpur. Nikhil is an AI/ML fanatic who’s all the time researching purposes in fields like biomaterials and biomedical science. With a robust background in Materials Science, he’s exploring new developments and creating alternatives to contribute.
[ad_2]