[ad_1]
Introduction
Think about you’re conducting a examine to find out whether or not a brand new drug successfully reduces blood strain. You administer the drug to a gaggle of sufferers and examine their outcomes to a management group receiving a placebo. You analyze the information and conclude that the brand new drug considerably reduces blood strain when, in actuality, it doesn’t. This incorrect rejection of the null speculation (that the drug has no impact) is a Sort I error. Alternatively, suppose the drug truly does scale back blood strain, however your examine fails to detect this impact because of inadequate pattern measurement or variability within the information. Because of this, you conclude that the drug is ineffective, which is a failure to reject a false null speculation—a Sort II error.
These eventualities spotlight the significance of understanding Sort I and Sort II errors in statistical testing. Sort I errors, often known as false positives, happen once we mistakenly reject a real null speculation. Sort II errors, or false negatives, occur once we fail to reject a false null speculation. A lot of statistical idea revolves round minimizing these errors, although utterly eliminating each is statistically inconceivable. By understanding these ideas, we are able to make extra knowledgeable choices in numerous fields, from medical testing to high quality management in manufacturing.

Overview
- Sort I and Sort II errors signify false positives and false negatives in speculation testing.
- Speculation testing includes formulating null and different hypotheses, selecting a significance degree, calculating take a look at statistics, and making choices primarily based on vital values.
- Sort I errors happen when a real null speculation is mistakenly rejected, resulting in pointless interventions.
- Sort II errors occur when a false null speculation will not be rejected, inflicting missed diagnoses or ignored results.
- Balancing Sort I and Sort II errors includes trade-offs in significance ranges, pattern sizes, and take a look at energy to attenuate each errors successfully.
The Fundamentals of Speculation Testing
Speculation testing is a technique used to resolve whether or not there may be sufficient proof to reject a null speculation (H₀) in favor of another speculation (H₁). The method includes:
- Formulating Hypotheses
- No impact or no distinction: No impact or no distinction.
- Different Speculation (H₁): An impact or a distinction exists.
- Selecting a Significance Stage (α): The likelihood threshold for rejecting H₀, usually set at 0.05, 0.01, or 0.10.
- Calculating the Check Statistic: A price derived from pattern information used to check towards a vital worth.
- Making a Resolution: If the take a look at statistic exceeds the essential worth, reject H₀; in any other case, don’t reject H₀.
Additionally learn: Finish-to-Finish Statistics for Knowledge Science
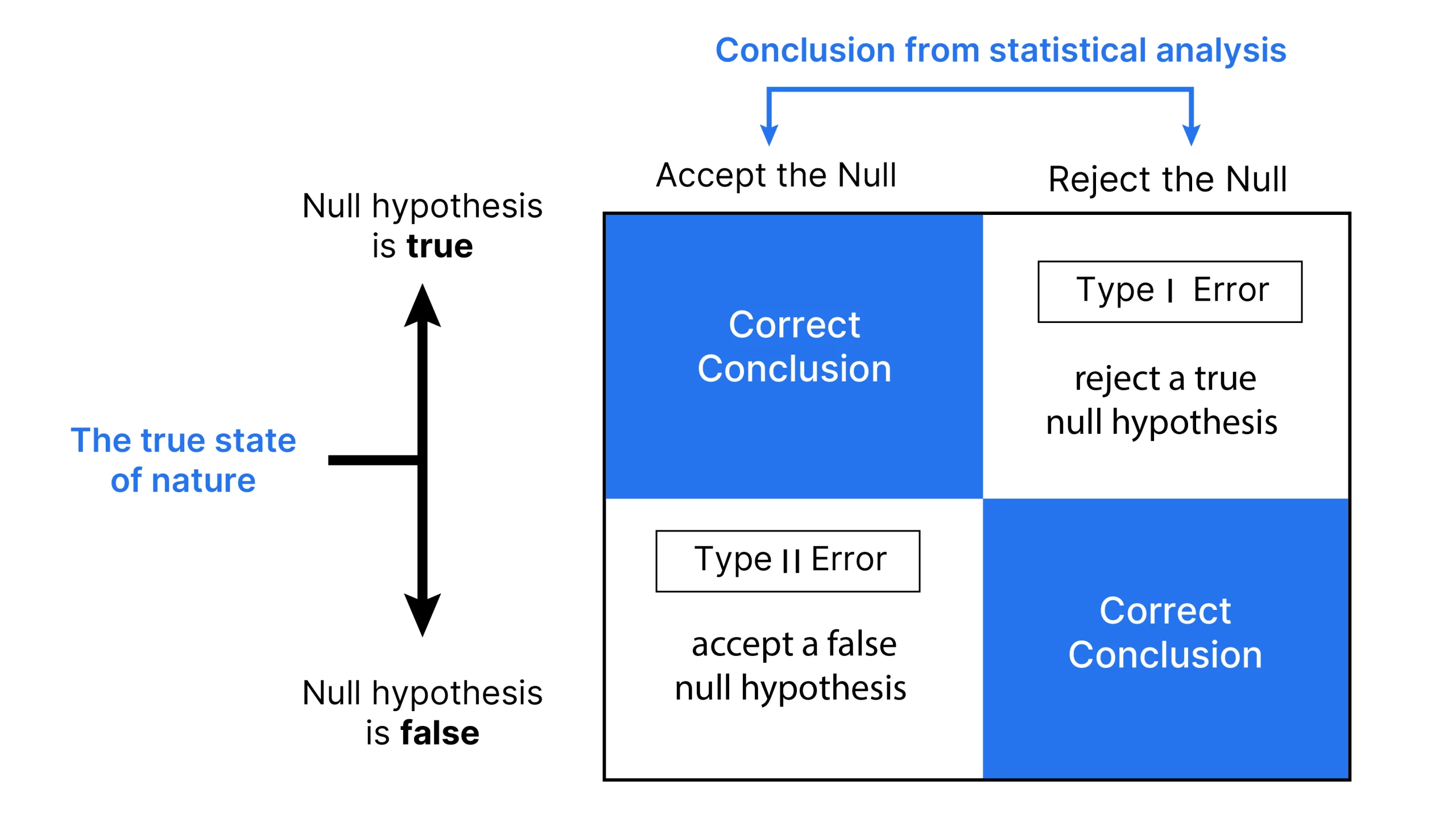
Sort 1 Error( False Optimistic)
A Sort I error happens when an experiment’s null speculation(H0) is true however mistakenly rejected (the Graph is talked about under).
This error represents figuring out one thing that isn’t truly current, just like a false optimistic. This may be defined in easy phrases with an instance: In a medical take a look at for a illness, a Sort I error would imply the take a look at signifies a affected person has the illness when they don’t, primarily elevating a false alarm. On this case, the null speculation(H0) would state: The affected person doesn’t have illness.
The chance of committing a Sort I error is known as the importance degree or price degree. It’s denoted by the Greek letter α (alpha) and is called the alpha degree. Sometimes, this opportunity or likelihood is ready at 0.05 or 5%. This manner, researchers are often inclined to just accept a 5% likelihood of incorrectly rejecting the null speculation when it’s sincerely precise.
Sort I errors can result in pointless therapies or interventions, inflicting stress and potential hurt to people.
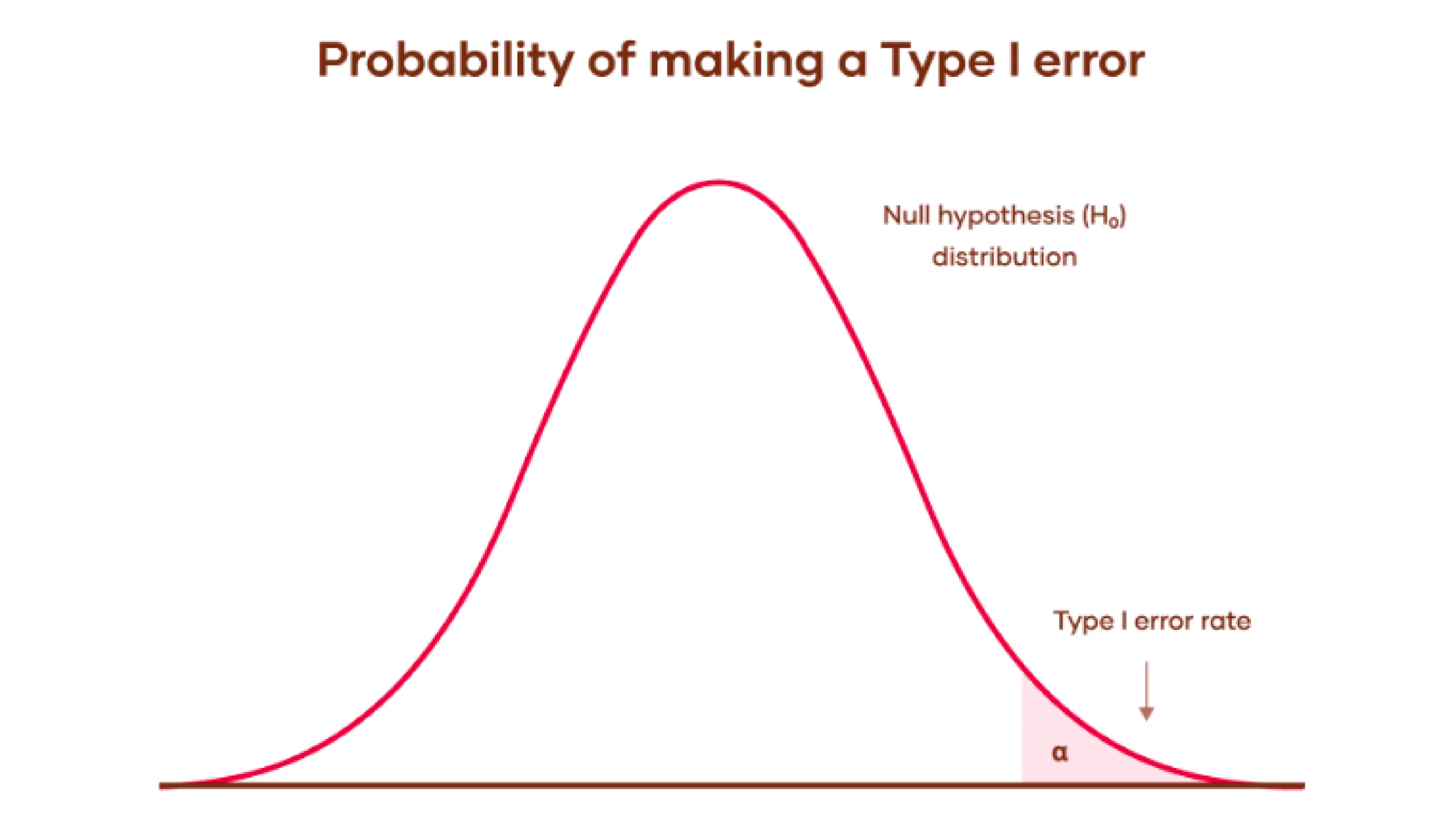
Let’s perceive this with Graph:
- Null Speculation Distribution: The bell curve reveals the vary of attainable outcomes if the null speculation is true. This implies the outcomes are because of random likelihood with none precise impact or distinction.
- Sort I Error Price: The shaded space beneath the curve’s tail represents the importance degree, α. It’s the likelihood of rejecting the null speculation when it’s truly true. Which leads to a Sort I error (false optimistic).
Sort 2 Error ( False Destructive)
A Sort II error occurs when a sound different speculation goes unrecognized. In less complicated phrases, it’s like failing to identify a bear that’s truly there, thus not elevating an alarm when one is required. On this situation, the null speculation (H0) nonetheless states, “There isn’t any bear.” The investigator commits a Sort II error if a bear is current however undetected.
The important thing problem isn’t all the time whether or not the illness exists however whether or not it’s successfully identified. The error can come up in two methods: both by failing to find the illness when it’s current or by claiming to find the illness when it’s not current.
The likelihood of Sort II error is denoted by the Greek letter β (beta). This worth is expounded to a take a look at’s statistical energy, which is calculated as 1 minus β (1−β).
Sort II errors can lead to missed diagnoses or ignored results, resulting in insufficient therapy or interventions.
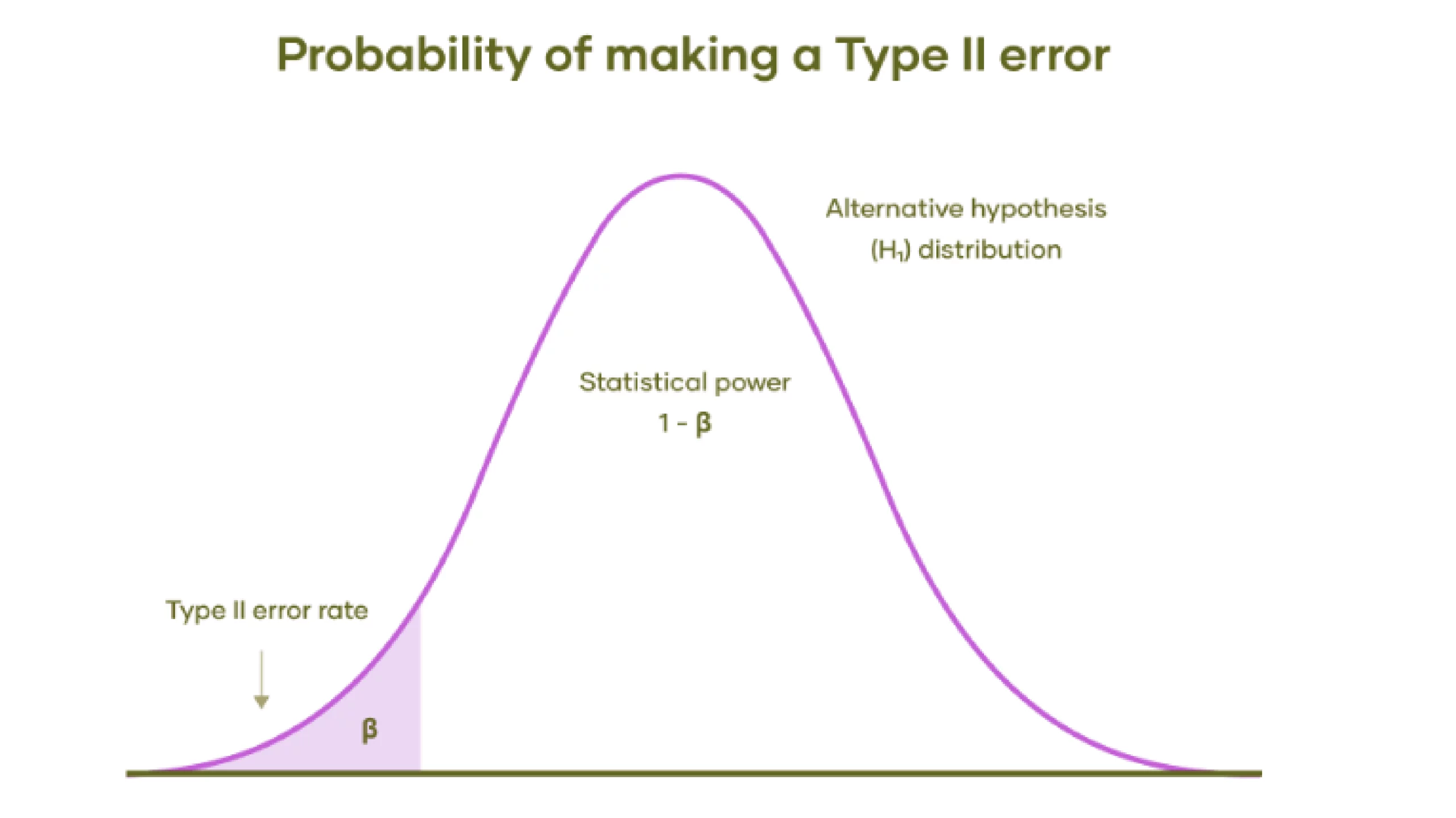
Let’s perceive this with Graph:
- Different Speculation Distribution: The bell curve represents the vary of attainable outcomes if the choice speculation is true. This implies there may be an precise impact or distinction, opposite to the null speculation.
- Sort II Error Price (β): The shaded space beneath the left tail of the distribution represents the likelihood of a Sort II error.
- Statistical Energy (1 – β): The unshaded space beneath the curve to the precise of the shaded space represents the take a look at’s statistical energy. Statistical energy is the likelihood of appropriately rejecting the null speculation when the choice speculation is true. Larger energy means a decrease likelihood of creating a Sort II error.
Additionally learn: Be taught all About Speculation Testing!
Comparability of Sort I and Sort II Errors
Right here is the detailed comparability:
| Side | Sort I Error | Sort II Error |
|---|---|---|
| Definition and Terminology | Rejecting a real null speculation (false optimistic) | Accepting a false null speculation (false unfavourable) |
| Symbolic Illustration | α (alpha) | β (beta) |
| Chance and Significance | Equal to the extent of significance set for the take a look at | Calculated as 1 minus the facility of the take a look at (1 – energy) |
| Error Discount Methods | Lower the extent of significance (will increase Sort II errors) | Enhance the extent of significance (raises Sort I errors) |
| Causal Elements | Probability or luck | Smaller pattern sizes or much less highly effective statistical checks |
| Analogies | “False hit” in a detection system | “Miss” in a detection system |
| Speculation Affiliation | Incorrectly rejecting the null speculation | Failing to reject a false null speculation |
| Incidence Situations | Happens when acceptance ranges are too lenient | Happens when acceptance standards are overly stringent |
| Implications | Prioritized in fields the place avoiding false positives is essential (e.g., medical testing) | Prioritized in fields the place avoiding false negatives is essential (e.g., screening for extreme illnesses) |
Additionally learn: Speculation Testing Made Simple for Knowledge Science Rookies
Commerce-off Between Sort I and Sort II Errors
There’s principally a trade-off amongst Sort I and Sort II errors. Lowering the chance of 1 sort of error usually will increase the chance for the other.
- Significance Stage (α): Reducing α reduces the prospect of a Sort I error however will increase the danger of a Sort II error. Rising α has the other impact.
- Pattern Dimension: Rising the pattern measurement can scale back each Sort I and Sort II errors, as bigger samples present extra correct estimates.
- Check Energy: Enhancing the take a look at’s energy by rising the pattern measurement or utilizing extra delicate checks can scale back the likelihood of Sort II errors.
Conclusion
Sort I and Sort II errors are elementary concepts in statistics and analysis strategies. By understanding the distinction between these errors and their implications, we are able to interpret analysis findings higher, conduct extra highly effective analysis, and make extra knowledgeable choices in various fields. Bear in mind, the objective isn’t to remove errors (which is inconceivable) however to handle them efficiently primarily based on the actual context and potential outcomes.
Ceaselessly Requested Questions
Ans. It’s difficult to remove each sorts of errors as a result of lowering one typically will increase the opposite. Nevertheless, by rising the pattern measurement and punctiliously designing the examine, researchers can lower each errors to relevant ranges.
Ans. Listed below are the widespread misconceptions about Sort I and Sort II errors:
False impression: A decrease α all the time means a greater take a look at.
Actuality: Whereas a decrease α reduces Sort I errors, it could possibly improve Sort II errors, resulting in missed detections of true results.
False impression: Giant pattern sizes remove the necessity to fear about these errors.
Actuality: Giant pattern sizes scale back errors however don’t remove them. Good examine design remains to be important.
False impression: A big outcome (p-value < α) means the null speculation is fake.
Actuality: A big outcome suggests proof towards H₀, however it doesn’t show H₀ is fake. Different components like examine design and context have to be thought-about.
Ans. Rising the facility of your take a look at makes it extra prone to detect a real impact. You are able to do this by:
A. Rising your pattern measurement.
B. Utilizing extra exact measurements.
C. Lowering variability in your information.
D. Rising the impact measurement, if attainable.
Ans. Pilot research show you how to estimate the parameters wanted to design a bigger, extra definitive examine. They supply preliminary information on impact sizes and variability, which inform your pattern measurement calculations and assist stability Sort I and Sort II errors in the primary examine.
[ad_2]